Oracle SQL语句
2024-08-29 13:53:44
供稿:网友
ORDER BY 排序
ASC 升序(默认)
DESC 降序
select * from s_emp order by dept_id , salary desc
部门号升序,工资降序
关键字distinct也会触发排序操作。
select * from employee order by 1; //按第一字段排序
NULL被认为无穷大。order by 可以跟别名。
select table_name from user_tables where table_name='S_EMP'; 查某个具体表名时,表名的字符串必须要为大写
或者采用 upper(table_name)
select * from user_talbes where table_name like ‘s/_%’ escape ‘/’;
使用转义字符对关键字进行转义。
concat 连接字符串 select concat(first_name , last_name) from s_emp;等效于||
substr 求子串 select substr('tarenasd0603' ,1,6) from dual; (取前六个字符) select substr('tarenasd0603',-2) from dual; (取后两个字符)
length 求字符长度
select length('zhonghua') from dual;
from dual的意思
虚表(dual)是Oracle提供的最小的工作表,它仅包含一行一列。对于虚表(dual)来说,其中的列往往是不相关的或无关紧要的。
如:查询当前的系统日期
SQL> select sysdate from dual;
SYSDATE
-------------------
2004/04/28 08:49:41
round 函数(四舍五入) select round(45.935, 2) from dual; 不带参数时默认为0位小数
trunc 函数(截取,不管后面的数字) select trunc(45.995, 1) from dual;
组函数
group by 分组子句 对分组后的子句进行过滤还可以用having 条件 对分组后的条件进行过滤 where 是对记录进行过滤
有佣金人数的百分比
select count( commission_pct )count(*) from s_emp;
select count(dept_id) from s_emp;
select count(distinct dept_id) from s_emp;//区分相同的dept_id
求各个部门的平均工资:group by 子句也会触发排序
select dept_id , avg(salary) aa from s_emp group by dept_id order by aa ; //对平均工资排序
select dept_id , avg(salary) aa from s_emp group by dept_id;
哪些部门的平均工资比2000高:
select dept_id, avg(salary) aa from s_emp group by (dept_id) having avg(salary)>2000;
除了42部门以外的部门的平均工资:
select dept_id , avg(salary) from s_emp group by (dept_id ) having dept_id!=42;
select dept_id , avg(salary) from s_emp where dept_id!=42 group by (dept_id ) ;(此种sql效率要高,先过滤) 再计算)
where 单行函数。
having 组函数。
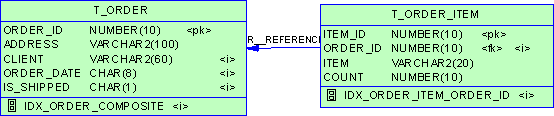
每个员工所在的部门和部门所在的地区
select first_name , s_dept.name, s_region.name from s_emp, s_dept, s_region where
s_emp.dept_id=s_dept.id and s_dept.region_id=s_region.id;
等价于
select first_name,d.name,r.name
from s_emp e,s_dept d,s_region r
where e.dept_id=d.id and d.region_id=r.id;