1、编写目的
使用统一的命名和编码规范,使数据库命名及编码风格标准化,以便于阅读、理解和继承。
2、适用范围
本规范适用于公司范围内所有以Oracle作为后台数据库的应用系统和项目开发工作。
3、对象命名规范
3.1 数据库和SID
数据库名定义为系统名+模块名
★ 全局数据库名和例程SID 名要求一致
★ 因SID 名只能包含字符和数字,所以全局数据库名和SID 名中不能含有“_”等字符
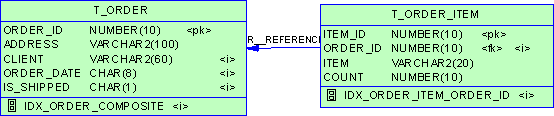
3.2 表相关
3.2.1 表空间
★ 面向用户的专用数据表空间以用户名+_+data命名 ,如Aud 用户专用数据表空间可命名为Aud_data
★ 面向用户的专用索引表空间以用户名+_+idx命名
★ 面向用户的专用临时表空间以用户名+_+tmp命名
★ 面向用户的专用回滚段表空间以用户名+_+rbs 命名
★ 面向应用的表空间以应用名+_data/应用名+_idx/应用名+_tmp/应用名+_rbs 命名
★ LOB 段数据专用表空间以其数据表空间+_+lobs 命名,如上例中数据表空间为Aud_data,则LOB 段表空间可命名为Aud_data_lobs
3.2.2 表空间文件
表空间文件命名以表空间名+两位数序号(序号从01开始)组成,如Aud_data01 等
3.2.3 表
表命名要遵循以下原则:
★ 一般表采用“系统名+t_+模块名+_+表义名” 格式构成
★ 若数据库中只含有单个模块,命名可采用“系统名+t_+表义名”格式构成
★ 模块名或表义名均以其汉语拼音的首字符命名,表义名中汉语拼音均采用小写,且字符间不加分割符;
★ 表别名命名规则:取表义名的前3 个字符加最后一个字符。如果存在冲突,适当增加字符(如取表义名的前4 个字符加最后一个字符等)
★ 临时表采用“系统名+t_tmp_+表义名” 格式构成
★ 表的命名如
dft_gy_cbap:系统名(电费 df)+t_+模块名(高压 gy)+_+表义名(抄表安排 cbap)
dft_cbbj: 系统名(电费 df)+t_+表义名(抄表标记 cbbj)
dft_tmp_hj: 系统名(电费 df)+tmp+表义名(合计hj)(此处为临时表)
★ 关联表命名为Re_表A_表B,Re 是Relative的缩写,表A 和表B均采用其表义名或缩写形式。
3.2.4 属性(列或字段)
属性命名遵循以下原则:
★ 采用有意义的列名,为实际含义的汉语拼音的首字符,且字符间不加任何分割符
★ 属性名前不要加表名等作为前缀
★ 属性后不加任何类型标识作为后缀
★ 不要使用“ID”作为列名
★ 关联字段命名以 “cd+_+关联表的表义名(或缩写)+_+字段名”进行
3.2.5 主键
★ 任何表都必须定义主键
★ 表主键命名为:“pk+_+表名(或缩写)+_+主键标识”如“pk_YHXX_IDKH”等
3.2.6 外键
表外键命名为: “fk+_+表名(或缩写)+_主表名(或缩写)+_+主键标识”如“fk_YHLX_YHXX_SFZH”等
3.2.7 CHECK约束
CHECK 约束命名为: “chk+_+CHECK约束的列名(或缩写)”
3.2.8 UNIQUE约束
UNIQUE 约束命名为: “unq+_+UNIQUE约束的列名(或缩写)”
3.2.9 索引
索引的命名为:“表名(或缩写)+_+列名+_idx”。其中多单词组成的属性列列名取前几个单词首字符再加末单词首字符组成如yd_kh 表khid 上的index: yd_kh_khid_idx
3.2.10 触发器
★ AFTER型触发器
系统名+tr_+<表名>_+ +[_row]
★ BEFORE型触发器
系统名+tr_+<表名>_+bef_+[_row]
★ INSTEAD OF型触发器
系统名+ti_+<表名>+_++[_row]
★ 各种类型的触发器中
i,u,d 分别表示insert、update 和delete行级触发器,后加_row 标识,语句级触发器不加,如 yddftr_CSH_i_row
3.2.11 簇
簇以簇中要存储的各个表(或表别名)及表间加and的组成 命名,即表“A+And+表B…”,如存储GR(工人)和GRJN(工人技能)表的簇命名为GRAndGRJN
3.3 视图
视图命名以系统名v_+模块名作为前缀,其他命名规则和表的命名类似
3.4 序列
序列命名以seq_+含义名组成
3.5 同义词
同义词命名与其基础对象的名称一致,但要去除其用户前缀或含有远程数据库链接的后缀
3.6 存储对象相关
3.6.1 存储过程
存储过程命名由“系统名+sp+_+存储过程标识(缩写)”组成存储过程标识要以实际含义的汉语拼音的首字符构成,并用下划线分割各个组成部分。如增加代理商的帐户的存储过程为“sfsp_ZJDLSZH”。
3.6.2 函数
函数命名由“系统名+f+_+函数标识”组成
3.6.3 包
包命名由“系统名+pkg+_+包标识”组成
3.6.4 函数文本中的变量采用下列格式命名:
★ 参数变量命名采用“i (o或io)+_+名称”形式,前缀i 或o 表输入还是输出参数
★ 过程变量命名采用“l+_+名称”形式
★ 全局包变量命名采用“g+_+名称”形式
★ 游标变量命名采用“名称+_+cur”形式
★ 常量型变量命名采用“c+_+名称”形式
★ 变量名采用小写,若属于词组形式,用下划线分隔每个单词
★ 变量用来存放表中的列或行数据值时,使用%TYPE、%ROWTYPE 方式声明变量,使变量声明的类型与表中的保持同步,随表的变化而变化
3.7 用户及角色
★ 用户命名由“系统名称+_+user+_+名词(或缩写)或名词短语(或缩写)”组成
★ 角色命名由“系统名称+_+role+_+名词(或缩写)或名词短语(或缩写)”组成
3.8 数据库链接
★ 数据库链接命名由“远程服务器名+_+数据库名+_+link”组成
★ 若远程服务器名和数据库名一致,上式“_+数据库名”部分省去
3.9 命名中的其它注意事项
★ 命名都不得超过30个字符。
★ 不要在对象名的字符之间留空格
★ 小心保留词,要保证你的命名没有和保留词、数据库系统或者常用访问方法冲突
4、 编码规范
4.1 一般性注释
4.1.1 注释尽可能简洁、详细而全面
4.1.2 创建每一数据库对象时都要加上COMMENT ON注释,以说明该对象的功能和用途;建表时,对某些数据列也要加上COMMENT ON注释,以说明该列和/或列取值的含义。如:XX 表中有CZZT列属性为NUMBER(10, 0)可加COMMENT ON 注释如下COMMENT ON COLUMN XX.CZZT IS '0 = 正常, 1 = 等待, 2 = 超时, 3 = 登出'
4.1.3 注释语法包含两种情况:单行注释、多行注释
单行注释:注释前有两个连字符(--),一般对变量、条件子句可以采用该类注释。
多行注释:符号/*和*/之间的内容为注释内容。对某项完整的操作建议使用该类注释。
4.2 函数文本注释
4.2.1 在每一个块和过程(存储过程、函数、包、触发器、视图等)的开头放置注释
/************************************************************************
*name : --函数名
*function : --函数功能
*input : --输入参数
*output : --输出参数
*author : --作者
*CreateDate : --创建时间
*UpdateDate : --函数更改信息(包括作者、时间、更改内容等)
*************************************************************************/
CREATE [OR REPLACE] PROCEDURE dfsp_xxx
…
4.2.2 传入参数的含义应该有所说明。如果取值范围确定,也应该一并说明。取值有特定含义的变量(如boolean类型变量),应给出每个值的含义。
4.2.3 在每一个变量声明的旁边添加注释。说明该变量要用作什么
通常,简单使用单行注释就行了,例如l_sfzh CHAR(11) --身份证号码
4.2.4 在块的每个主要部分之前添加注释
在块的每个主要部分之前增加注释,解释下—组语句目的,最好是说明该段语句及算法的目的以及要得到的结果,但不要对其细节进行过多的描述
4.2.5 在块和过程的开头注释中还可以增加要访问的数据库等信息
4.3 常用SQL 语句的编写规范
4.3.1 CREATE语句
CREATE TABLE dft_dksz(
YHBS VARCHAR2(20) NOT NULL,
ZHGX DATE,
DKKHD VARCHAR2(24),
CONSTRAINT pk_dksz_yhbs PRIMARY KEY (YHBS)
)
4.3.2 SELECT语句
查询语句采用以下原则编写(可最大化重用共享池中的SQL 语句,提高应用程序性能):
★ 将SELECT 语句分为5部分:
(1) 由SELECT 开头,后跟一个显示查询结果的列表;
(2) 由FROM 开头,后跟一个或多个获取数据所涉及的表;
(3) 由WHERE 开头,后跟一个或多个确定所需值的条件;
(4) 由GROUP BY开头,后跟一个或多个表列名,通过这些列以对查询结果进行汇总;
(5) 由ORDER BY开头,后跟一个或多个表列名,通过这些列以对查询结果进行排序。
★ 每个部分分行编写,将每一行的第一个关键字与第一行的SELECT尾部对齐,如
SELECT col1, col2, col3
FROM table1
WHERE col1 > col2
GROUP BY col1, col2
ORDER BY col1;
★ 关键字用大写,列名和表名采用小写
★ 语句中嵌入逗号时,在逗号后面加一空格,当逗号是最后一个字符时,把它放在本行
★ 当语句的同一部分要延续到下一行时,按下列格式排列:
SELECT col1, col2, col3, col4, col5, col6,
col7, col8, col9, col10
★ 将语句中WHERE 和AND 部分格式化,书写布局类似于
WHERE
AND
AND
★ 当语句中出现括号时,括号的两边不留空格
★ 在SQL 语句使用运算符时,操作两边应各留一个空格,如
WHERE X = Y
AND A = B
AND C = D
4.3.3 INSERT语句
INSERT INTO <要插入的表名>
(<列1>, <列2>, .., <列n-1>, <列n>)
VALUES (<列1值>, <列2值>, .., <列n-1值>, <列n值>)
4.3.4 UPDATE语句
UPDATE <要更新的表名>
SET <要更新的列> = <列值>
4.3.5 DELETE语句
DELETE FROM table1
WHERE col1 = '???'
4.4 条件执行语句(IF)编写规范
条件执行语句IF…ELSE 按以下格式编写
IF <条件表达式>
THEN
<一条或多条语句>
[ELSE (或ELSIF<条件表达式>)
THEN
<一条或多条语句>
END IF;
注:
(1) 在IF…THEN和ELSE(或ELSIF)及ELSE…THEN和END IF间可包含一条或多条PL/SQL
语句,而不需要加BEGIN 和END
(2) IF…ELSE…ENDIF 语句可以嵌套
(3) 注意ELSIF的写法
4.5 循环语句编写规范
4.5.1 简单循环语句
LOOP
<零条或多条语句>
EXIT WHEN <条件表达式>
<零条或多条语句>
END LOOP;
4.5.2 FOR循环语句
FOR 变量 IN [变量取值范围]
LOOP
<一条或多条语句>
END LOOP;
4.5.3 WHILE循环语句
WHILE <条件表达式>
LOOP
<一条或多条语句>
END LOOP;
4.6 函数文本(存储过程、函数和包等)
★ 对于存储过程、函数等程序块都要有异常处理部分,在异常部分的最后都要设置OTHERS异常情态处理器,以提高程序的自检能力,格式如下:
BEGIN
…
EXCEPTION
WHEN excep—name1 THEN
…
WHEN excep—name2 THEN
…
WHEN OTHERS THEN
…
END;
★ 对于子程序、触发器、包等带名的程序块,要使用结束标识,如
CREATE OR REPLACE PROCEDURE XXXsp_XXX IS
…
BEGIN
…
END XXXsp_XXX;
/* 此处的过程名XXXsp_XXX是可选的,规范要求写上,与块开始的CREATE相对应 */
新闻热点






疑难解答