Oracle Hash join 是一种非常高效的join 算法,主要以CPU(hash计算)和内存空间(创建hash table)为代价获得最大的效率。Hash join一般用于大表和小表之间的连接,我们将小表构建到内存中,称为Hash cluster,大表称为PRobe表。
效率
Hash join具有较高效率的两个原因:
1.Hash 查询,根据映射关系来查询值,不需要遍历整个数据结构。
2.Mem 访问速度是Disk的万倍以上。
理想化的Hash join的效率是接近对大表的单表选择扫描的。
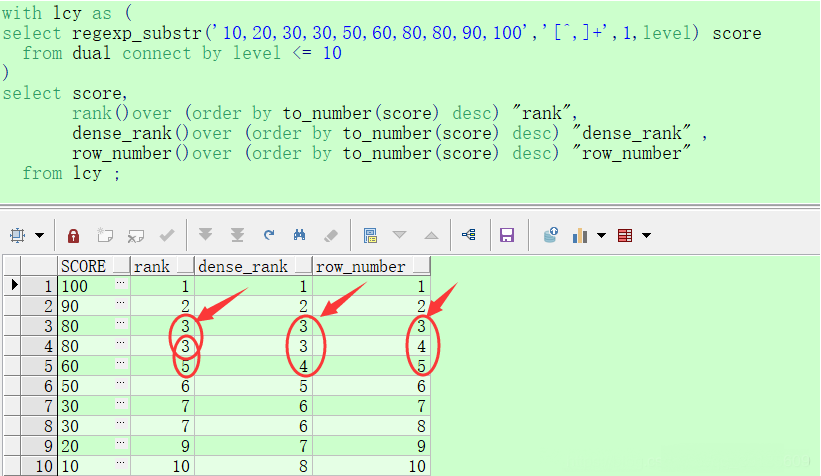
首先我们来比较一下,几种join之间的效率,首先 optimizer会自动选择使用hash join。
注意到Cost= 221
SQL> select * from vendition t,customer b WHERE t.customerid = b.customerid;
100000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3402771356
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106K| 22M| 221 (3)| 00:00:03 |
|* 1 | HASH JOIN | | 106K| 22M| 221 (3)| 00:00:03 |
| 2 | TABLE access FULL| CUSTOMER | 5000 | 424K| 9 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| VENDITION | 106K| 14M| 210 (2)| 00:00:03 |
--------------------------------------------------------------------------------
不使用hash,这时optimizer自动选择了merge join。。
注意到Cost=3507大大的增加了。
SQL> select /*+ USE_MERGE (t b) */* from vendition t,customer b WHERE t.customerid = b.customerid;
100000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1076153206
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106K| 22M| | 3507 (1)| 00:00:43 |
| 1 | MERGE JOIN | | 106K| 22M| | 3507 (1)| 00:00:43 |
| 2 | SORT JOIN | | 5000 | 424K| | 10 (10)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CUSTOMER | 5000 | 424K| | 9 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 106K| 14M| 31M| 3496 (1)| 00:00:42 |
| 5 | TABLE ACCESS FULL| VENDITION | 106K| 14M| | 210 (2)| 00:00:03 |
-----------------------------------------------------------------------------------------
那么Nest loop呢,经过漫长的等待后,发现Cost达到了惊人的828K,同时伴随3814337 consistent gets(由于没有建索引),可见在这个测试中,Nest loop是最低效的。在给customerid建立唯一索引后,减低到106K,但仍然是内存join的上千倍。
SQL> select /*+ USE_NL(t b) */* from vendition t,customer b WHERE t.customerid = b.customerid;
100000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2015764663
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106K| 22M| 828K (2)| 02:45:41 |
| 1 | NESTED LOOPS | | 106K| 22M| 828K (2)| 02:45:41 |
| 2 | TABLE ACCESS FULL| VENDITION | 106K| 14M| 210 (2)| 00:00:03 |
|* 3 | TABLE ACCESS FULL| CUSTOMER | 1 | 87 | 8 (0)| 00:00:01 |
HASH的内部
HASH_AREA_SIZE在Oracle 9i 和以前,都是影响hash join性能的一个重要的参数。但是在10g发生了一些变化。Oracle不建议使用这个参数,除非你是在MTS模式下。Oracle建议采用自动PGA管理(设置PGA_AGGREGATE_TARGET和WORKAREA_SIZE_POLICY)来,替代使用这个参数。由于我的测试环境是mts环境,自动内存管理,所以我在这里只讨论mts下的hash join。
Mts的PGA中,只包含了一些栈空间信息,UGA则包含在large pool中,那么实际类似hash,sort,merge等操作都是有large pool来分配空间,large pool同时也是auto管理的,它和SGA_TARGET有关。所以在这种条件下,内存的分配是很灵活。
Hash连接根据内存分配的大小,可以有三种不同的效果:
1.optimal 内存完全足够
2.onepass 内存不能装载完小表
3.multipass workarea executions 内存严重不足
下面,分别测试小表为50行,500行和5000行,内存的分配情况(内存都能完全转载)。
Vendition表 10W条记录
Customer表 5000
Customer_small 500,去Customer表前500行建立
Customer_pity 50,取Customer表前50行建立
表的统计信息如下:
SQL> SELECT s.table_name,S.BLOCKS,S.AVG_SPACE,S.NUM_ROWS,S.AVG_ROW_LEN,S.EMPTY_BLOCKS FROM user_tables S WHERE table_name IN ('CUSTOMER','VENDITION','CUSTOMER_SMALL','CUSTOMER_PITY') ;
TABLE_NAME BLOCKS AVG_SPACE NUM_ROWS AVG_ROW_LEN EMPTY_BLOCKS
CUSTOMER 35 1167 5000 38 5
CUSTOMER_PITY 4 6096 50 37 4
CUSTOMER_SMALL 6 1719 500 36 2
VENDITION 936 1021 100000 64 88打开10104事件追踪:(hash 连接追踪)
ALTER SYSTEM SET EVENTS ‘ 10104 TRACE NAME CONTEXT,LEVEL 2’;
测试SQL
SELECT * FROM vendition a,customer b WHERE a.customerid = b.customerid;
SELECT * FROM vendition a,customer_small b WHERE a.customerid = b.customerid;
SELECT * FROM vendition a,customer_pity b WHERE a.customerid = b.customerid;
小表50行时候的trace分析:
*** 2008-03-23 18:17:49.467
*** session ID:(773.23969) 2008-03-23 18:17:49.467
kxhfInit(): enter
kxhfInit(): exit
*** RowSrcId: 1 HASH JOIN STATISTICS (INITIALIZATION) ***
Join Type: INNER join
Original hash-area size: 3883510
PS:hash area的大小,大约380k,本例中最大的表也不过250块左右,所以内存完全可以完全装载
Memory for slot table: 2826240
Calculated overhead for partitions and row/slot managers: 1057270
Hash-join fanout: 8
Number of partitions: 8
PS:hash 表数据连一个块都没装满,Oracle仍然对数据进行了分区,这里和以前在一些文档上看到的,当内存不足时才会对数据分区的说法,发生了变化。
Number of slots: 23
Multiblock IO: 15
Block size(KB): 8
Cluster (slot) size(KB): 120
PS:分区中全部行占有的cluster的size
Minimum number of bytes per block: 8160
Bit vector memory allocation(KB): 128
Per partition bit vector length(KB): 16
Maximum possible row length: 270
Estimated build size (KB): 0
Estimated Build Row Length (includes overhead): 45
# Immutable Flags:
Not BUFFER(execution) output of the join for PQ
Evaluate Left Input Row Vector
Evaluate Right Input Row Vector
# Mutable Flags:
IO sync
kxhfSetPhase: phase=BUILD
kxhfAddChunk: add chunk 0 (sz=32) to slot table
kxhfAddChunk: chunk 0 (lbs=0x2a97825c38, slotTab=0x2a97825e00) successfuly added
kxhfSetPhase: phase=PROBE_1
qerhjFetch: max build row length (mbl=44)
*** RowSrcId: 1 END OF HASH JOIN BUILD (PHASE 1) ***
Revised row length: 45
Revised build size: 2KB
kxhfResize(enter): resize to 12 slots (numAlloc=8, max=23)
kxhfResize(exit): resized to 12 slots (numAlloc=8, max=12)
Slot table resized: old=23 wanted=12 got=12 unload=0
*** RowSrcId: 1 HASH JOIN BUILD HASH TABLE (PHASE 1) ***
Total number of partitions: 8
Number of partitions which could fit in memory: 8
Number of partitions left in memory: 8
Total number of slots in in-memory partitions: 8
Total number of rows in in-memory partitions: 50
(used as preliminary number of buckets in hash table)
Estimated max # of build rows that can fit in avail memory: 66960
### Partition Distribution ###
Partition:0 rows:5 clusters:1 slots:1 kept=1
Partition:1 rows:6 clusters:1 slots:1 kept=1
Partition:2 rows:4 clusters:1 slots:1 kept=1
Partition:3 rows:9 clusters:1 slots:1 kept=1
Partition:4 rows:5 clusters:1 slots:1 kept=1
Partition:5 rows:9 clusters:1 slots:1 kept=1
Partition:6 rows:4 clusters:1 slots:1 kept=1
Partition:7 rows:8 clusters:1 slots:1 kept=1
PS:每个分区只有不到10行,这里有一个重要的参数Kept,1在内存中,0在磁盘
*** (continued) HASH JOIN BUILD HASH TABLE (PHASE 1) ***
PS:hash join的第一阶段,但是要观察更多的阶段,需提高trace的level,这里略过
Revised number of hash buckets (after flushing): 50
Allocating new hash table.
*** (continued) HASH JOIN BUILD HASH TABLE (PHASE 1) ***
Requested size of hash table: 16
Actual size of hash table: 16
Number of buckets: 128
Match bit vector allocated: FALSE
kxhfResize(enter): resize to 14 slots (numAlloc=8, max=12)
kxhfResize(exit): resized to 14 slots (numAlloc=8, max=14)
freeze work area size to: 2359K (14 slots)
*** (continued) HASH JOIN BUILD HASH TABLE (PHASE 1) ***
Total number of rows (may have changed): 50
Number of in-memory partitions (may have changed): 8
Final number of hash buckets: 128
Size (in bytes) of hash table: 1024
kxhfIterate(end_iterate): numAlloc=8, maxSlots=14
*** (continued) HASH JOIN BUILD HASH TABLE (PHASE 1) ***
### Hash table ###
# NOTE: The calculated number of rows in non-empty buckets may be smaller
# than the true number.
Number of buckets with 0 rows: 86
Number of buckets with 1 rows: 37
Number of buckets with 2 rows: 5
Number of buckets with 3 rows: 0
PS:桶里面的行数,最大的桶也只有2行,理论上,桶里面的行数越少,性能越佳。
Number of buckets with 4 rows: 0
Number of buckets with 5 rows: 0
Number of buckets with 6 rows: 0
Number of buckets with 7 rows: 0
Number of buckets with 8 rows: 0
Number of buckets with 9 rows: 0
Number of buckets with between 10 and 19 rows: 0
Number of buckets with between 20 and 29 rows: 0
Number of buckets with between 30 and 39 rows: 0
Number of buckets with between 40 and 49 rows: 0
Number of buckets with between 50 and 59 rows: 0
Number of buckets with between 60 and 69 rows: 0
Number of buckets with between 70 and 79 rows: 0
Nmber of buckets with between 80 and 89 rows: 0
Number of buckets with between 90 and 99 rows: 0
Number of buckets with 100 or more rows: 0
### Hash table overall statistics ###
Total buckets: 128 Empty buckets: 86 Non-empty buckets: 42
PS:创建了128个桶,Oracle 7开始的计算公式
Bucket数=0.8*hash_area_size/(hash_multiblock_io_count*db_block_size)
但是不准确,估计10g发生了变化。
Total number of rows: 50
Maximum number of rows in a bucket: 2
Average number of rows in non-empty buckets: 1.190476
小表500行时候的trace分析
Original hash-area size: 3925453
Memory for slot table: 2826240
。。。
Hash-join fanout: 8
Number of partitions: 8
。。。
### Partition Distribution ###
Partition:0 rows:52 clusters:1 slots:1 kept=1
Partition:1 rows:63 clusters:1 slots:1 kept=1
Partition:2 rows:55 clusters:1 slots:1 kept=1
Partition:3 rows:74 clusters:1 slots:1 kept=1
Partition:4 rows:66 clusters:1 slots:1 kept=1
Partition:5 rows:66 clusters:1 slots:1 kept=1
Partition:6 rows:54 clusters:1 slots:1 kept=1
Partition:7 rows:70 clusters:1 slots:1 kept=1
PS:每个partition的行数增加
。。。
Number of buckets with 0 rows: 622
Number of buckets with 1 rows: 319
Number of buckets with 2 rows: 71
Number of buckets with 3 rows: 10
Number of buckets with 4 rows: 2
Number of buckets with 5 rows: 0
。。。
### Hash table overall statistics ###
Total buckets: 1024 Empty buckets: 622 Non-empty buckets: 402
Total number of rows: 500
Maximum number of rows in a bucket: 4
Average number of rows in non-empty buckets: 1.243781
小表5000行时候的trace分析
Original hash-area size: 3809692
Memory for slot table: 2826240
。。。
Hash-join fanout: 8
Number of partitions: 8
Nuber of slots: 23
Multiblock IO: 15
Block size(KB): 8
Cluster (slot) size(KB): 120
Minimum number of bytes per block: 8160
Bit vector memory allocation(KB): 128
Per partition bit vector length(KB): 16
Maximum possible row length: 270
Estimated build size (KB): 0
。。。
### Partition Distribution ###
Partition:0 rows:588 clusters:1 slots:1 kept=1
Partition:1 rows:638 clusters:1 slots:1 kept=1
Partition:2 rows:621 clusters:1 slots:1 kept=1
Partiton:3 rows:651 clusters:1 slots:1 kept=1
Partition:4 rows:645 clusters:1 slots:1 kept=1
Partition:5 rows:611 clusters:1 slots:1 kept=1
Partitio:6 rows:590 clusters:1 slots:1 kept=1
Partition:7 rows:656 clusters:1 slots:1 kept=1
。。。
# than the true number.
Number of buckets with 0 rows: 4429
Number of buckets with 1 rows: 2762
Number of buckets with 2 rows: 794
Number of buckets with 3 rows: 182
Number of buckets with 4 rows: 23
Number of buckets with 5 rows: 2
Number of buckets with 6 rows: 0
。。。
### Hash table overall statistics ###
Total buckets: 8192 Empty buckets: 4429 Non-empty buckets: 3763
Total number of rows: 5000
Maximum number of rows in a bucket: 5
PS:当小表上升到5000行的时候,bucket的rows最大也不过5行。注意,如果bucket行数过多,遍历带来的开销会带来性能的严重下降。
Average number of rows in non-empty buckets: 1.328727
结论:
Oracle数据库10g中,内存问题并不是干扰Hash join的首要问题,现今硬件价格越来越便宜,内存2G,8G,64G的环境也很常见。大家在针对hash join调优的过程,更要偏重于partition和bucket的数据分配诊断。
新闻热点






疑难解答