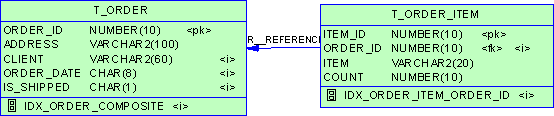
CONNECT SYSTEM/MANAGER@cl.world CREATE PUBLIC DATABASE LINK js.world USING ’js.world’; CONNECT repadmin/repadmin@cl.world CREATE DATABASE LINK js.world CONNECT TO repadmin IDENTIFIED BY repadmin;
同样,在解释站点上建立与处理站点的数据库链接。 以下为引用的内容:
CONNECT SYSTEM/MANAGER@js.world CREATE PUBLIC DATABASE LINK cl.world USING ’cl.world’; CONNECT repadmin/repadmin@js.world CREATE DATABASE LINK cl.world CONNECT TO repadmin IDENTIFIED BY repadmin;