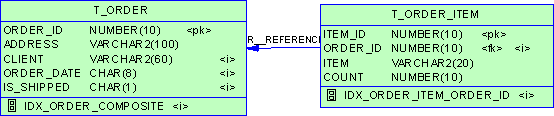
AWR 使用几个表来存储采集的统计数据,所有的表都存储在新的名称为 SYSAUX 的特定表空间中的 SYS 模式下,并且以 WRM$_* 和 WRH$_* 的格式命名。前一种类型存储元数据信息(如检查的数据库和采集的快照),后一种类型保存实际采集的统计数据。(您可能已经猜到,H 代表“历史数据 (historical)”而 M 代表“元数据 (metadata)”。)在这些表上构建了几种带前缀 DBA_HIST_ 的视图,这些视图可以用来编写您自己的性能诊断工具。视图的名称直接与表相关;例如,视图 DBA_HIST_SYSMETRIC_SUMMARY 是在WRH$_SYSMETRIC_SUMMARY 表上构建的。 AWR 历史表采集的信息比 Statspack 多许多,这些信息包括表空间使用率、文件系统使用率、甚至操作系统统计数据。这些表的完整的列表可以通过以下命令从数据字典中看到:
select view_name from user_views where view_name like 'DBA/_HIST/_%' escape '/';
视图 DBA_HIST_METRIC_NAME 定义 AWR 采集到的重要的量度、它们所属的组和采集它们的单位。例如,下面是一个记录(竖直格式):
DBID : 4133493568 GROUP_ID : 2 GROUP_NAME : System Metrics Long Duration METRIC_ID : 2075 METRIC_NAME : CPU Usage Per Sec METRIC_UNIT : CentiSeconds Per Second
它显示一个量度“每秒 CPU 使用率”以“每秒的厘秒数”为单位进行测量,并且该量度属于一个量度组 “System Metrics Long Duration”。这条记录可以和其它的表(如 DBA_HIST_SYSMETRIC_SUMMARY)结合,以获得数据库的活动信息,形式如下:
select begin_time, intsize, num_interval, minval, maxval, average, standard_deviation sd from dba_hist_sysmetric_summary where metric_id = 2075; BEGIN INTSIZE NUM_INTERVAL MINVAL MAXVAL AVERAGE SD----- ---------- ------------ ------- ------- -------- ----------11:39 179916 30 0 33 3 9.8155354811:09 180023 30 21 35 28 5.91543912 ... and so on ...
下面我们看看 CPU 时间是如何消耗的(以厘秒为单位)。标准差加入到了我们的分析中,它有助于确定平均数字是否反映了实际的工作负载。在第一条记录中,平均值是每秒消耗 CPU 时间 3 厘秒,但标准差是 9.81,这意味着平均值 3 不能反映工作负载。在第二个例子中,平均值为 28,标准差为 5.9,这更具有代表性。这种类型的信息趋势有助于了解几个环境参数对性能量度的影响。使用统计数据 迄今为止,我们看到了 AWR 所采集的内容,现在让我们看看它将如何处理数据。 大多数性能问题并不是孤立存在的,而留有指示性的迹象,这些迹象将通向问题最终的根源。让我们使用一个典型的调整实践来说明这一点:您注重到系统很慢,于是决定查看等待的原因。您检查发现“缓冲区忙等待”非常高。问题可能出在哪里呢?有几种可能:可能有一个单调增加的索引,可能一个表太满了,以至于要求将单个数据块非常快速地加载到内存中,或其它一些因素。无论在哪种情况下,您都首先要确定存在问题的段。假如它是一个索引段,那么您可以决定重新构建它,把它修改为一个反向键索引,或把它转换成一个在 Oracle Database 10g 中引进的散列分区索引。假如它是一个表,您可以考虑修改存储参数来使它不那么密集,或者利用自动段空间治理把它转移到一个表空间中。 您的处理计划一般是有规律的,并且通常基于您对各种事件的了解和您处理它们的经验。现在设想相同的事情由一个引擎来完成,这个引擎采集量度并根据预先确定的逻辑来推出可能的计划。您的工作不就变得更轻松了吗? 现在在 Oracle Database 10g 中推出的这个引擎称为自动数据库诊断监控程序 (ADDM)。为了作出决策,ADDM 使用了由 AWR 采集的数据。在上面的讨论中,ADDM 可以看到发生了缓冲区忙等待,然后取出相应的数据来查看发生缓冲区忙等待的段,评估其特性和成分,最后为数据库治理员提供解决方案。在 AWR 进行的每一次快照采集之后,调用 ADDM 来检查量度并生成建议。因此,实际上您拥有了一个一天二十四小时工作的自动数据库治理员,它主动地分析数据并生成建议,从而把您解放出来,使您能够关注更具有战略意义的问题。 要查看 ADDM 建议和 AWR 信息库数据,请使用在名称为 DB Home 的页面上的新的 EnterPRise Manager 10g 控制台。要查看 AWR 报表,您可以从治理转至工作负载信息库,然后转至 Snapshots 来查看它们。在以后的部分中,我们将更具体地讨论 ADDM。 您还可以指定根据特定的情况来生成警报。这些警报称为服务器生成警报,它们被推送到高级队列中,在其中它们可以被任意监听它的客户端使用。一个这样的客户端是 Enterprise Manager 10g,在其中警报被突出显示。 时间模型 当您有性能问题时,要缩短响应时间您最先想到的是什么?很明显,您希望消除(或减少)增加时间的因素的根源。您如何知道时间花费在哪里 — 不是等待,而是真正在进行工作? Oracle Database 10g 引进了时间模型,以确定在各个地方花费的时间。花费的总的系统时间记录在视图 V$SYS_TIME_MODEL 中。下面是查询和输出结果。
STAT_NAME VALUE ------------------------------------- -------------- DB time 58211645 DB CPU 54500000 background cpu time 254490000 sequence load elapsed time 0 parse time elapsed 1867816 hard parse elapsed time 1758922 sql execute elapsed time 57632352 connection management call elapsed time 288819 failed parse elapsed time 50794 hard parse (sharing criteria) elapsed time 220345 hard parse (bind mismatch) elapsed time 5040 PL/SQL execution elapsed time 197792 inbound PL/SQL rpc elapsed time 0 PL/SQL compilation elapsed time