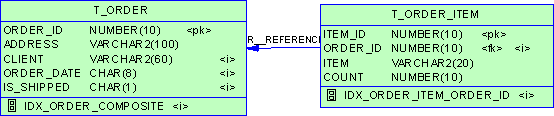
alter tablespace XXX begin backup;cp XXX ....alter tablespace XXX end backup;
(这里需要注重一点,Oracle的最小存储单位是一个数据块,一个块的大小通常设置为8KB,而操作系统的块通常是512B,这样的话一个Oracle的数据由很多个操作系统的块组成。而且对于一个数据文件来说,它的所有块对应的操作系统的块并不是按顺序存储的,当运行cp等操作系统命令时并不能指定从那个Oracle数据块开始拷贝。)当open数据库的时候,Oracle会去比较控制文件中数据文件记录和数据文件头的checkpoint cnt,假如两者相同,则判定不需要介质恢复,假如不同,这时候Oracle就会报某某文件需要介质恢复。然后拷贝回数据文件备份我们开始recover,这时候就从上次做备份时的scn开始恢复,运用日志,直到恢复结束。当cp数据文件时,比如说我们拷贝的第一个块可能是scn为100的数据块,当我们完成这个块的拷贝后,这个块有可能被别的进程多次修改,scn变为900。我们知道当数据库发生检查点时会去更新数据文件头和控制文件中的checkpoint scn,假如当我们在cp数据文件的同时发生了n次checkpoint,这时候数据文件头的scn可能被更新了很多次。这时候cp的进程去拷贝数据文件头所在的操作系统块,可能这个数据文件头的块因为被checkpoint了很多次导致它的scn为1000,这时候整个数据文件会出现不一致,当用这个备份文件去恢复时,恢复进程会从scn=1000开始恢复,这样的话开始那个scn=100的块将丢失从scn100-scn1000的数据,因为数据块并不应用scn在1000以前的日志,而且这样做的话可能出现一些数据块的corruption,所以不置成backup模式备份的话并不可取。当然,假如你能确保当cp的时候不发生checkpoint,或者你的操作系统块的大小不小于Oracle的数据块大小,这些情况下不置backup mode拷贝出来的文件也是有效的。 现在我们知道了为什么不能不设置backup模式,下面来讲讲alter tablespace XXX begin backup做了什么? 当数据文件置于backup模式时,Oracle会去锁定数据文件头,这时候数据库发生检查点的话将不会修改文件头的checkpoint scn,而只是增加checkpoint cnt,所以不管执行cp的时候操作系统块的拷贝顺序是如何,Oracle总会从文件头的scn开始恢复,这样的话也就避免了数据丢失和数据块corruption。假如大家用的是rman来备份,那么就不会有这个问题,因为rman备份的时候rman会去对比数据块的头尾标志,假如发现不一致,那么它将会再去读这个块,直到读到一致的块才往备份集里写。 但是alter tablespace XXX begin backup带来的另一个问题是会导致产生多余的日志,通过一个小小的试验就可以证实这一点。
SQL> select name,value from v$sysstat where name='redo size';NAME VALUE--------------------------------------------------- ----------redo size 43408SQL> update test set a=a;1 row updated.SQL> commit;Commit complete.SQL> select name,value from v$sysstat where name='redo size';NAME VALUE--------------------------------------------------------------redo size 44060 SQL> ALTER SYSTEM DUMP LOGFILE '/netapPRedo/redo05.log';System altered.
SQL> alter tablespace test begin backup;Tablespace altered.SQL> select name,value from v$sysstat where name='redo size';NAME VALUE------------------------------------------------------------------redo size 44732SQL> update test set a=a;1 row updated.SQL> commit;Commit complete.SQL> select name,value from v$sysstat where name='redo size';NAME VALUE-------------------------------------------------------------------redo size 53560SQL> alter tablespace test end backup;Tablespace altered.