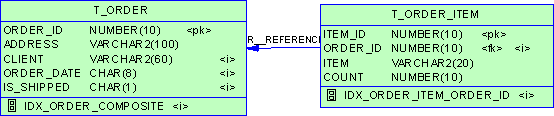
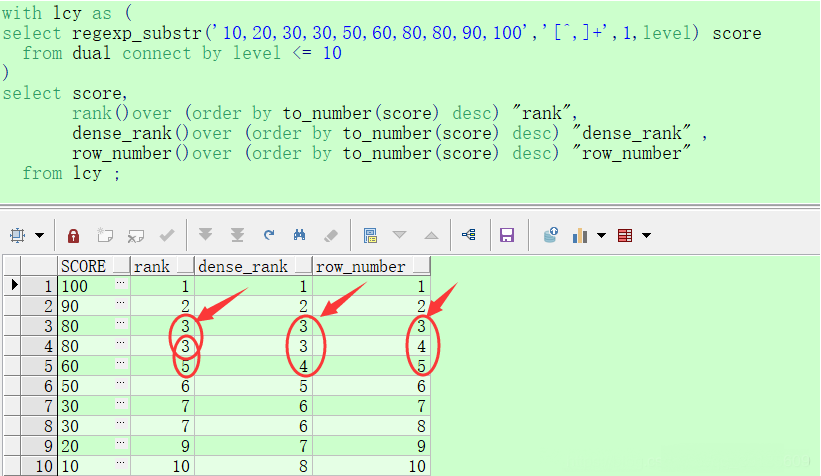
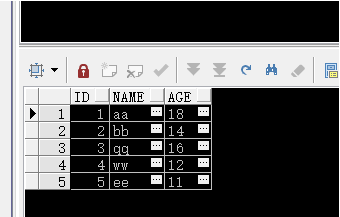
| SELECT SUBSTR(country,1,20) country, SUBSTR(prod,1,15) prod, year, salesFROM sales_viewWHERE country IN ('Italy','Japan') MODEL RETURN UPDATED ROWS PARTITION BY (country) DIMENSION BY (prod, year) MEASURES (sale sales) RULES ( sales['Bounce', 2002] = sales['Bounce', 2001] + sales['Bounce', 2000], sales['Y Box', 2002] = sales['Y Box', 2001], sales['2_Products', 2002] = sales['Bounce', 2002] + sales['Y Box', 2002])ORDER BY country, prod, year; |