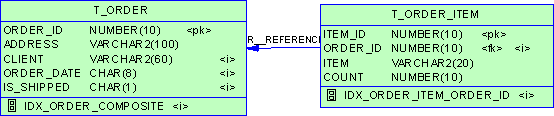
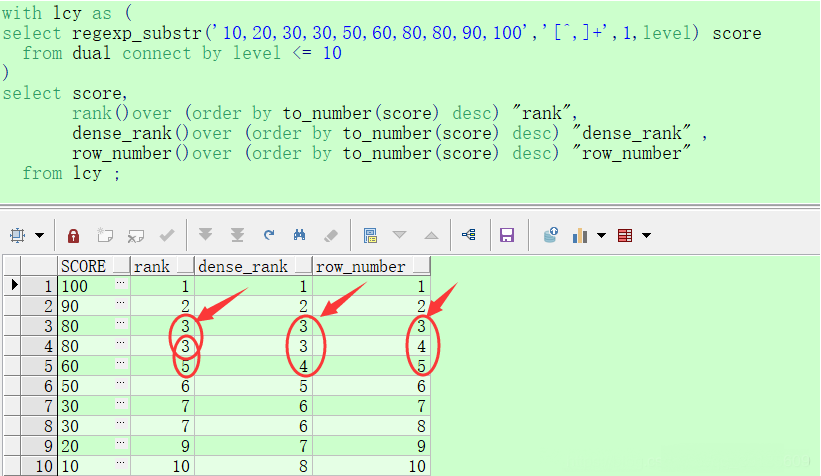
关于Oracle的性能调整,一般包括两个方面,一是指Oracle数据库本身的调整,比如SGA、PGA的优化设置,二是连接Oracle的应用程序以及SQL语句的优化。做好这两个方面的优化,就可以使一套完整的Oracle应用系统处于良好的运行状态。 本文主要是把一些Oracle Tuning的文章作了一个简单的总结,力求以实际可操作为目的,配合讲解部分理论知识,使大部分具有一般Oracle知识的使用者能够对Oracle Tuning有所了解,并且能够根据实际情况对某些参数进行调整。关于更加具体的知识,请参见本文结束部分所提及的推荐书籍,同时由于该话题内容太多且复杂,本文必定有失之偏颇甚至错误的地方,请不吝赐教,并共同进步。 1. SGA的设置 在Oracle Tuning中,对SGA的设置是要害。SGA,是指Shared Global Area , 或者是 System Global Area , 称为共享全局区或者系统全局区,结构如下图所示。
对于SGA区域内的内存来说,是共享的、全局的,在UNIX 上,必须为oracle 设置共享内存段(可以是一个或者多个),因为oracle 在UNIX上是多进程;而在WINDOWS上oracle是单进程(多个线程),所以不用设置共享内存段。1.1 SGA的各个组成部分 下面用 sqlplus 查询举例看一下 SGA 各个组成部分的情况: SQL> select * from v$sga; NAME VALUE -------------------- ---------- Fixed Size 104936 Variable Size 823164928 Database Buffers 1073741824 Redo Buffers 172032或者 SQL> show sga Total System Global Area 1897183720 bytes Fixed Size 104936 bytes Variable Size 823164928 bytes Database Buffers 1073741824 bytes Redo Buffers 172032 bytesFixed Size oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了SGA 各部分组件的信息,可以看作引导建立SGA的区域。Variable Size 包含了shared_pool_size、java_pool_size、large_pool_size 等内存设置Database Buffers 指数据缓冲区,在8i 中包含db_block_buffer*db_block_size、buffer_pool_keep、buffer_pool_recycle 三部分内存。在9i 中包含db_cache_size、db_keep_cache_size、db_recycle_cache_size、 db_nk_cache_size。Redo Buffers 指日志缓冲区,log_buffer。在这里要额外说明一点的是,对于v$parameter、v$sgastat、v$sga查询值可能不一样。v$ parameter 里面的值,是指用户在初始化参数文件里面设置的值,v$sgastat是oracle 实际分配的日志缓冲区大小(因为缓冲区的分配值实际上是离散的,也不是以block 为最小单位进行分配的),v$sga 里面查询的值,是在oracle 分配了日志缓冲区后,为了保护日志缓冲区,设置了一些保护页,通常我们会发现保护页大小是8k(不同环境可能不一样)。参考如下内容
SQL> select substr(name,1,10) name,substr(value,1,10) value 2 from v$parameter where name = 'log_buffer'; NAME VALUE -------------------- -------------------- log_buffer 163840SQL> select * from v$sgastat where pool is null;POOL NAME BYTES ----------- -------------------------- ---------- fixed_sga 104936 db_block_buffers 1073741824 log_buffer 163840SQL> select * from v$sga;NAME VALUE -------------------- ---------- Fixed Size 104936 Variable Size 823164928 Database Buffers 1073741824 Redo Buffers 172032172032 – 163840 = 8192(以上试验数据是在 HP B.11.11 + Oracle 8.1.7.4 环境下得到的) 1.2 SGA的大小设置 在对SGA的结构进行简单分析以后,下面是关于如何根据系统的情况正确设置SGA大小的问题。 SGA是一块内存区域,占用的是系统物理内存,因此对于一个Oracle应用系统来说,SGA决不是越大越好,这就需要寻找一个系统优化的平衡点。 1.2.1 设置参数前的预备 在设置SGA的内存参数之前,我们首先要问自己几个问题 一:物理内存多大 二:操作系统估计需要使用多少内存 三:数据库是使用文件系统还是裸设备 四:有多少并发连接 五:应用是OLTP 类型还是OLAP 类型根据这几个问题的答案,我们可以粗略地为系统估计一下内存设置。那我们现在来逐个问题地讨论,首先物理内存多大是最轻易回答的一个问题,然后操作系统估计使用多少内存呢?从经验上看,不会太多,通常应该在200M 以内(不包含大量进程PCB)。 接下来我们要探讨一个重要的问题,那就是关于文件系统和裸设备的问题,这往往轻易被我们所忽略。操作系统对于文件系统,使用了大量的buffer 来缓存操作系统块。这样当数据库获取数据块的时候,虽然SGA 中没有命中,但却实际上可能是从操作系统的文件缓存中获取的。而假如数据库和操作系统支持异步IO,则实际上当数据库写进程DBWR写磁盘时,操作系统在文件缓存中标记该块为延迟写,等到真正地写入磁盘之后,操作系统才通知DBWR写磁盘完成。对于这部分文件缓存,所需要的内存可能比较大,作为保守的估计,我们应该考虑在 0.2——0.3 倍内存大小。但是假如我们使用的是裸设备,则不考虑这部分缓存的问题。这样的情况下SGA就有调大的机会。
注: 在Oracle9i 中,不存在internal 用户,可以使用sys 用户以sysdba 身份连接。 先转到$ORACLE_HOME/RDBMS/ADMIN 目录,检查安装脚本是否存在,同时我们执行脚本也可以方便些。$ cd $ORACLE_HOME/rdbms/admin $ ls -l sp*.sql -rw-r--r-- 1 oracle other 1774 Feb 18 2000 spauto.sql -rw-r--r-- 1 oracle other 62545 Jun 15 2000 spcpkg.sql -rw-r--r-- 1 oracle other 877 Feb 18 2000 spcreate.sql -rw-r--r-- 1 oracle other 31193 Jun 15 2000 spctab.sql -rw-r--r-- 1 oracle other 6414 Jun 15 2000 spcusr.sql -rw-r--r-- 1 oracle other 758 Jun 15 2000 spdrop.sql -rw-r--r-- 1 oracle other 3615 Jun 15 2000 spdtab.sql -rw-r--r-- 1 oracle other 1274 Jun 15 2000 spdusr.sql -rw-r--r-- 1 oracle other 6760 Jun 15 2000 sppurge.sql -rw-r--r-- 1 oracle other 71034 Jul 12 2000 spreport.sql -rw-r--r-- 1 oracle other 2191 Jun 15 2000 sptrunc.sql -rw-r--r-- 1 oracle other 30133 Jun 15 2000 spup816.sql $接下来我们就可以开始安装Statspack 了。在Oracle8.1.6 版本中运行statscre.sql; 在Oracle8.1.7 版本中运行spcreate.sql。 这期间会提示你输入缺省表空间和临时表空间的位置,输入我们为 perfstat 用户创建的表空间和你的临时表空间。安装脚本会自动创建perfstat 用户。$ sqlplusSQL*Plus: Release 8.1.7.0.0 - Production on Sat Jul 26 16:27:31 2003(c) Copyright 2000 Oracle Corporation. All rights reserved.Enter user-name: internalConnected to: Oracle8i Enterprise Edition Release 8.1.7.0.0 - Production With the Partitioning option JServer Release 8.1.7.0.0 - ProductionSQL> SQL> @spcreate ... Installing Required PackagesPackage created.Grant succeeded.View created.Package body created.Package created.Synonym dropped.Synonym created. ……Specify PERFSTAT user's default tablespace Enter value for default_tablespace: perfstat Using perfstat for the default tablespaceUser altered.User altered.Specify PERFSTAT user's temporary tablespace Enter value for temporary_tablespace: temp Using temp for the temporary tablespaceUser altered.NOTE: SPCUSR complete. Please check spcusr.lis for any errors.……假如安装成功,你可以接着看到如下的输出信息:
…. Creating Package STATSPACK...Package created.No errors. Creating Package Body STATSPACK...Package body created.No errors.NOTE: SPCPKG complete. Please check spcpkg.lis for any errors.可以查看.lis 文件查看安装时的错误信息。§ 步骤四: 假如安装过程中出现错误,那么可以运行spdrop.sql 脚本来删除这些安装脚本建立的对象。然后重新运行spcreate.sql来创建这些对象。SQL> @spdrop Dropping old versions (if any)Synonym dropped.Sequence dropped.Synonym dropped.Table dropped.Synonym dropped.View dropped. …… NOTE: SPDUSR complete. Please check spdusr.lis for any errors.(以上的安装过程描述是在 HP 11.11 + Oracle 8.1.7 平台上得到的)2.1.2 测试statspack 运行statspack.snap 可以产生系统快照,运行两次,然后执行spreport.sql 就可以生成一个基于两个时间点的报告。 假如一切正常,说明安装成功。SQL>execute statspack.snap PL/SQL procedure successfully completed. SQL>execute statspack.snap PL/SQL procedure successfully completed. SQL>@spreport.sql可是有可能你会得到以下错误:SQL> exec statspack.snap; BEGIN statspack.snap; END; * ERROR at line 1: ORA-01401: inserted value too large for column ORA-06512: at "PERFSTAT.STATSPACK", line 978 ORA-06512: at "PERFSTAT.STATSPACK", line 1612 ORA-06512: at "PERFSTAT.STATSPACK", line 71 ORA-06512: at line 1这是Oracle 的一个Bug,Bug 号1940915。 该Bug 自8.1.7.3 后修正。 这个问题只会出现在多位的字符集, 需要修改spcpkg.sql 脚本,$ORACLE_HOME/rdbms/admin/spcpkg.sql,将"substr" 修改为 "substrb",然后重新运行该脚本。 该脚本错误部分: select l_snap_id , p_dbid , p_instance_number , substr(sql_text,1,31) ........... substr 会将多位的字符, 当作一个byte.substrb 则会当作多个byte。在收集数据时, statpack 会将 top10 的 sql 前 31 个字节 存入数据表中,若在SQL 的前31 个字有中文,就会出现此错误。 注重:运行 spcpkg.sql 也需要以 internal 用户登录 sqlplus 2.1.3 生成statspack报告 调用spreport.sql 可以生成分析报告: 当调用spreprot.sql 时,系统首先会查询快照列表,然后要求你选择生成报告的开始快照ID(begin_snap)和结束快照ID(end_snap),生成一个报告. 为了生成一个report,我们至少需要两次采样: SQL> @spreport DB Id DB Name Inst Num Instance ----------- ------------ -------- ------------ 2749170756 RES 1 resCompleted Snapshots Snap Snap Instance DB Name Id Snap Started Level Comment ------------ ------------ ----- ----------------- ----- ---------------------- res RES 1 26 Jul 2003 16:36 5
2 26 Jul 2003 16:37 5 3 26 Jul 2003 17:03 5 Specify the Begin and End Snapshot Ids ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Enter value for begin_snap:2 Begin Snapshot Id specified: 2Enter value for end_snap: 3 End Snapshot Id specified: 3 Specify the Report Name ~~~~~~~~~~~~~~~~~~~~~~~ The default report file name is sp_2_3. To use this name, press to continue, otherwise enter an alternative. Enter value for report_name: rep0726.txt …… End of Report 在运行 spreport.sql 生成 statspack 报告的过程中,会有三个地方提示用户输入: 1、 开始快照ID; 2、 结束快照ID; 3、 输出报告文件的文件名,缺省的文件名是sp__ 上面输入的开始快照ID是2,开始快照ID是3,输出报告文件的文件名是rep0726.txt 成功运行一次 statspack.snap 就会产生一个 snapshot ,在生成 statspack 报告的时候就可以看到这个 snap id 和 snap 运行的时间。运行 statspack.snap ,就是上面所说的采样,statspack 报告是分析两个采样点之间各种情况。2.1.4 删除历史快照数据 前面讲过,成功运行一次 statspack.snap 就会产生一个 snapshot ,这个 snapshot 的基本信息是存放在 PERFSTAT.stats$snapshot 表中的,生成 statspack报告时会查询该表的数据,供用户选择预备分析的 snapshot 。假如运行 statspack.snap 次数多了以后,该表的数据也会增加,历史数据会影响正常运行的效果,因此需要定时清理一下历史快照数据。 删除stats$snapshot 数据表中的相应数据,其他表中的数据会相应的级连删除:SQL> select max(snap_id) from stats$snapshot; MAX(SNAP_ID) ------------ 166SQL> delete from stats$snapshot where snap_id < = 166; 143 rows deleted你可以更改snap_id 的范围以保留你需要的数据。 在以上删除过程中,你可以看到所有相关的表都被锁定。 SQL> select a.object_id,a.oracle_username ,b.object_name from v$locked_object a,dba_objects b where a.object_id = b.object_id / OBJECT_ID ORACLE_USERNAME OBJECT_NAME ------------------------------------- -------------------------------------------------------------------------------- 156 PERFSTAT SNAP$ 39700 PERFSTAT STATS$LIBRARYCACHE 39706 PERFSTAT STATS$ROLLSTAT 39712 PERFSTAT STATS$SGA 39754 PERFSTAT STATS$PARAMETER 39745 PERFSTAT STATS$SQL_STATISTICS 39739 PERFSTAT STATS$SQL_SUMMARY 39736 PERFSTAT STATS$ENQUEUESTAT 39733 PERFSTAT STATS$WAITSTAT 39730 PERFSTAT STATS$BG_EVENT_SUMMARY 39724 PERFSTAT STATS$SYSTEM_EVENT 39718 PERFSTAT STATS$SYSSTAT 39715 PERFSTAT STATS$SGASTAT 39709 PERFSTAT STATS$ROWCACHE_SUMMARY 39703 PERFSTAT STATS$BUFFER_POOL_STATISTICS 39697 PERFSTAT STATS$LATCH_MISSES_SUMMARY 39679 PERFSTAT STATS$SNAPSHOT 39682 PERFSTAT STATS$FILESTATXS 39688 PERFSTAT STATS$LATCH 174 PERFSTAT JOB$ 20 rows selectedOracle 还提供了系统脚本用于Truncate 这些统计信息表,这个脚本名字是: sptrunc.sql (8i、9i 都相同) 该脚本主要内容如下,里面看到的就是statspack 相关的所有系统表: truncate table STATS$FILESTATXS; truncate table STATS$LATCH;
下面接合一个实际的statspack报告,大致分析一下。2.2.1 基本信息分析 DB Name DB Id Instance Inst Num Release OPS Host ------------ ----------- ------------ -------- ----------- --- --------- --- RES 2749170756 res 1 8.1.7.0.0 NO res Snap Id Snap Time Sessions ------- ------------------ -------- Begin Snap: 2 26-Jul-03 16:37:08 38 End Snap: 3 26-Jul-03 17:03:23 38 Elapsed: 26.25 (mins)Statspack报告首先描述了数据库的基本情况,比如数据库名、实例名、实例个数、oracle版本号等等;然后是该报告的开始快照和结束快照的信息,包括 snap id , snap time 等等;最后是该报告经过的时间跨度,单位是分钟(mins)。Cache Sizes ~~~~~~~~~~~ db_block_buffers: 61440 log_buffer: 163840 db_block_size: 8192 shared_pool_size: 52428800然后描述了Oracle内存结构中几个重要的参数。2.2.2 内存信息分析 Load Profile ~~~~~~~~~~~~ Per Second Per Transaction --------------- --------------- Redo size: 4,834.87 11,116.67 Logical reads: 405.53 932.43 Block changes: 60.03 138.02
Physical reads: 138.63 318.75 Physical writes: 54.27 124.79 User calls: 62.69 144.13 Parses: 19.14 44.00 Hard parses: 2.26 5.20 Sorts: 1.83 4.20 Logons: 0.21 0.47 Executes: 21.10 48.50 Transactions: 0.43 % Blocks changed per Read: 14.80 Recursive Call %: 34.45 Rollback per transaction %: 0.00 Rows per Sort: 20.57Redo size: 是日志的生成量,分为每秒和每事务所产生的,通常在很繁忙的系统中日志生成量可能达到上百k,甚至几百k;Logical reads: 逻辑读实际上就是logical IO=buffer gets表示的含义,我们可以这样认为,block在内存中,我们每一次读一块内存,就相当于一次逻辑读;Parses 和 Hard parses: Parse 和 hard parse通常是很轻易出问题的部分,80%的系统的慢都是由于这个原因所导致的。
所谓parse分soft parse 和hard parse,soft parse是当一条sql传进来后,需要在shared pool中找是否有相同的sql,假如找到了,那就是soft parse,假如没有找着,那就开始hard parse,实际上hard parse主要是检查该sql所涉及到的所有的对象是否有效以及权限等关系,hard parse之后才根据rule/cost模式生成执行计划,再执行sql。 而hard parse的根源,基本都是由于不使用bind var所导致的,不使用bind var违反了oracle的shared pool的设计的原则,违反了这个设计用来共享的思想,这样导致shared_pool_size里面命中率下降。因此不使用bind var,将导致cpu使用率的问题,极有使得性能急剧下降。 还有就是为了维护internal structure,需要使用latch,latch是一种Oracle低级结构,用于保护内存资源,是一种内部生命周期很短的lock,大量使用latch将消耗大量的cpu资源。Sorts: 表示排序的数量;Executes: 表示执行次数;Transactions: 表示事务数量;Rollback per transaction %: 表示数据库中事务的回退率。假如不是因为业务本身的原因,通常应该小于10%为好,回退是一个很消耗资源的操作。 Instance Efficiency Percentages (Target 100%) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 100.00 Redo NoWait %: 99.98 Buffer Hit %: 65.82 In-memory Sort %: 99.65 Library Hit %: 91.32 Soft Parse %: 88.18 Execute to Parse %: 9.28 Latch Hit %: 99.99 Parse CPU to Parse ElaPSD %: 94.61 % Non-Parse CPU: 99.90Buffer Hit %: 数据缓冲区命中率,通常应该大于90%;Library Hit %: libaray cache的命中率,通常应该大于98%;In-memory Sort %: 排序在内存的比例,假如这个比例过小,可以考虑增大sort_area_size,使得排序在内存中进行而不是在temp表空间中进行;Soft Parse %: 软解析的百分比,这个百分比也应该很大才好,因为我们要尽量减少hard parse。 soft parse 百分比=soft/(soft+hard);Execute to Parse %: 这个数字也应该是越大越好,接近100%最好。有些报告中这个值是负的,看上去很希奇。事实上这表示一个问题,sql假如被age out的话就可能出现这种情况,也就是sql老化,或执行alter system flush shared_pool等。 Shared Pool Statistics Begin End ------ ------ Memory Usage %: 90.63 87.19 % SQL with executions>1: 71.53 75.39 % Memory for SQL w/exec>1: 59.45 65.17% SQL with executions>1: 这个表示SQL被执行次数多于一次的比率,也应该大为好,小则表示很多sql只被执行了一次,说明没有使用bind var;2.2.3 等待事件分析 接下来,statspack报告中描述的是等待事件(Wait Events),这是Oracle中比较复杂难懂的概念。 Oracle 的等待事件是衡量Oracle 运行状况的重要依据及指标。 等待事件的概念是在Oracle7.0.1.2 中引入的,大致有100 个等待事件。在Oracle 8.0 中这个数目增加到了大约150 个,在Oracle8i 中大约有200 个事件,在Oracle9i 中大约有360 个等待事件。 主要有两种类别的等待事件,即空闲(idle)等待事件和非空闲(non-idle)等待事件。 空闲事件指Oracle 正等待某种工作,在诊断和优化数据库的时候,我们不用过多注重这部分事件。 常见的空闲事件有:
? dispatcher timer ? lock element cleanup ? Null event ? parallel query dequeue wait ? parallel query idle wait - Slaves ? pipe get ? PL/SQL lock timer ? pmon timer- pmon ? rdbms ipc message ? slave wait ? smon timer ? SQL*Net break/reset to client ? SQL*Net message from client ? SQL*Net message to client ? SQL*Net more data to client ? virtual circuit status ? client message非空闲等待事件专门针对Oracle 的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是我们在调整数据库的时候应该关注与研究的。 一些常见的非空闲等待事件有: ? db file scattered read ? db file sequential read ? buffer busy waits ? free buffer waits ? enqueue ? latch free ? log file parallel write ? log file sync下面接合statspack中的一些等待事件进行讲述。Top 5 Wait Events ~~~~~~~~~~~~~~~~~ Wait % Total Event Waits Time (cs) Wt Time -------------------------------------------- ------------ ------------ ------- db file scattered read 26,877 12,850 52.94 db file parallel write 472 3,674 15.13 log file parallel write 975 1,560 6.43 direct path write 1,571 1,543 6.36 control file parallel write 652 1,290 5.31 -------------------------------------------------------------db file scattered read: DB文件分散读取。这个等待事件很常见,经常在top5中出现,这表示,一次从磁盘读数据进来的时候读了多于一个block的数据,而这些数据又被分散的放在不连续的内存块中,因为一次读进来的是多于一个block的。 通常来说我们可以认为是全表扫描类型的读,因为根据索引读表数据的话一次只读一个block,假如这个数字过大,就表明该表找不到索引,或者只能找到有限的索引,可能是全表扫描过多,需要检查sql是否合理的利用了索引,或者是否需要建立合理的索引。 当全表扫描被限制在内存时,它们很少会进入连续的缓冲区内,而是分散于整个缓冲存储器中。尽管在特定条件下执行全表扫描可能比索引扫描更有效,但假如出现这种等待时,最好检查一下这些全表扫描是否必要,是否可以通过建立合适的索引来减少对于大表全表扫描所产生的大规模数据读取。