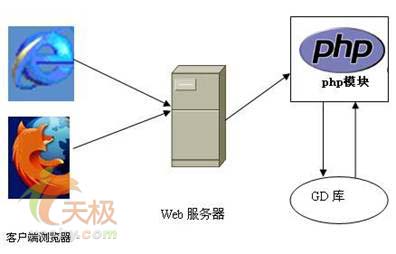
在Linux中,通过taskstats能过获得per-task或者per-process的统计数据,这样我们可以通过taskstats监控服务器的I/O.
了解taskstats的最初目的,是为了监控服务器的IO,防止jmeter因为受压机异常,打印大量日志,把磁盘空间用光,后来发现,由于服务器内核版本比较低(2.6.19),所以没法直接通过读取proc里面的IO来获取进程IO,但是也同样是因为内核版本太低,taskstats结构中,也比新内核少了磁盘写入和读取的统计,只能获取到磁盘延迟写入块数,所以还没有实战过.
关于taskstats,内核文档有非常详细的文档和示例代码,见:http://www.kernel.org/doc/Documentation/accounting/
首先说下taskstats结构,按张文档的说法“Taskstats is a netlink-based interface for sending per-task and per-process statistics from the kernel to userspace.”注意这里说明了,通过taskstats能过获得per-task或者per-process的统计数据,也就是内核的所谓pid和tgid的概念.
taskstats的优势在于:
- efficiently provide statistics during lifetime of a task and on its exit
- unified interface for multiple accounting subsystems --Vevb.com
- extensibility for use by future accounting patches
第一点比较有用,可以注册一个进程,当进程推出的时候收到taskstats消息,其他没用到.
taskstats通过netlink和内核进行交互,也就是说交互是异步的,在创建了netlink的fd之后,所有的操作和普通的socket也差不多了,就是需要根据netlink判断状态,并且取出真正的payload,也就是taskstats结构。
taskstats的结构在linux/taskstats.h文件中可以看见,里面有几个比较有用的成员,如:
cpu_count、cpu_delay_total,blkio_count、blkio_delay_total,swapin_count、swapin_delay_total。通过注释可以大概了解到,xxx_count is the number of delay values recorded,xxx_delay_total is the corresponding cumulative delay in nanoseconds,这样就能算出delay的量,大概需要多少时间能够消耗完,从侧面可以了解负载情况。我现在在使用的内核,还有很多IO统计的数据,但是2.6.19的内核不支持,就没办法使用了。
具体的使用,内核文档的getdelays.c已经很详细、很通用了,我参照这个,写了个比较简单的.
首先,是创建netlink连接,直接使用里面的create_nl_socket函数就好了,和创建普通socket差不多,只是类型上的区别,前面已经提到,taskstats使用的是NETLINK_GENERIC方式创建的netlink,然后就是发送netlink数据包给内核,具体的发送方式send_cmd函数已经进行了封装,通过枚举TASKSTATS_CMD_ATTR_TGID和TASKSTATS_CMD_ATTR_PID,可以获取对应的pid或者tgid的数据了.
新闻热点






疑难解答