我今天的页面也是出现了乱码,所以在网上查找了相关的问题,看来一下,这个方法挺不错的,我也试验了呢,我用的editp编辑器,在文档—文件编码—更改文件编码—选择自己所需要的编码就行
在网页中,中文乱码的问题时常出现。以前我遇到乱码问题时,就是不停的尝试不同的编码方式,直到成功。昨天项目又遇到了这个问题,我于是做了简单的测试。
html文件是有编码方式的,比如"UTF-8"、"GBK"等等。这些在记事本中或许看不出来,但是在eclipse中,可以设置html文件的编码方式,以下的图片中会有说明。
测试一:
以"UTF-8"方式保存html文件,具体的文件内容见下图:
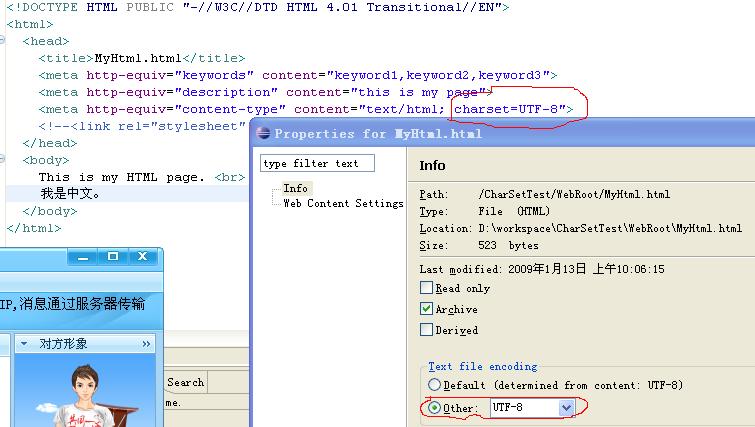
图中可以看到,文件的编码方式为"UTF-8",下方的红框中的Other所示,是在eclipse中设置的。图片上方的红框指明浏览器打开该文件的编码方式,可以看到为"UTF-8"。
使用IE打开该文件,可以看到下图:
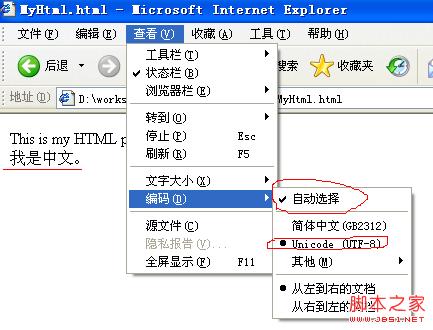
查看浏览器的编码方式,可以看到浏览器自动选择了"UTF-8"方式,并且没有出现乱码。
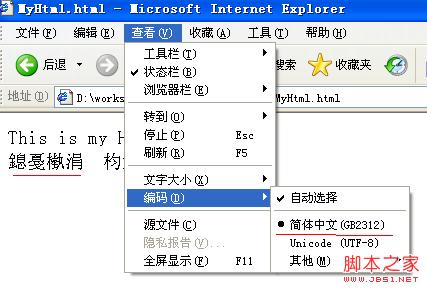
切换浏览器的编码方式到"GB2312",可以看到下图:
测试二:
以"UTF-8"方式保存html文件,并设置文件头中的编码方式为"GBK",如下图:

这表明:文件的编码方式为"UTF-8",默认的文件打开方式为"GBK"。
使用IE打开这个文件的截图如下:
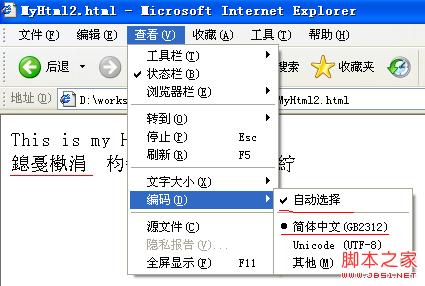
可以看到浏览器根据html文件的指示,用"GB2312"方式来打开。由于文件本身的编码方式是"UTF-8",所以出现了乱码。但是网页源文件并不是乱码。
选择浏览器的编码方式为"UTF-8",可以看到乱码现象消失。截图如下:
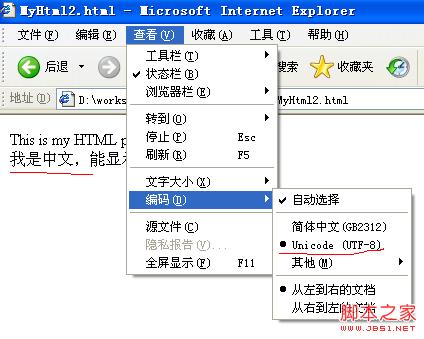
至此,测试结束。归纳以下几点:
1. html文件是有编码格式的,这个在特定的编辑器中才能看出来,并进行设置。
2. html文件中头部的"content-type"中设置的"charset"是告诉浏览器打开该文件的编码方式。
3. 一般1、2点中的编码方式应该一致,不一致可能出现乱码。
4. 如果浏览器中显示乱码,但是页面源文件不是乱码,可以通过修改浏览器的编码方式看到正确的中文,如果在源文件中设置了正确的"charset",就不需要修改浏览器的编码方式了。
新闻热点






疑难解答