有时我们在操作数据时,需要剔除单列数据的重复值,下面小编为大家介绍Excel剔除单列数据的重复值五种方法,满足大家的日常需求。
方法一:菜单按钮
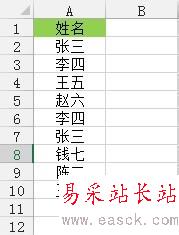
如下图,是本次操作的源数据。
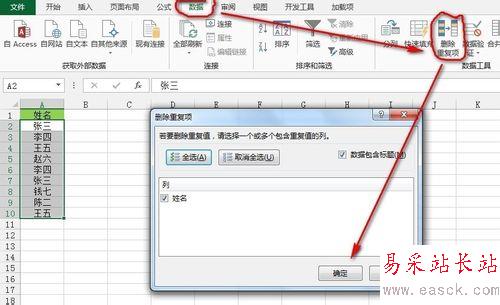
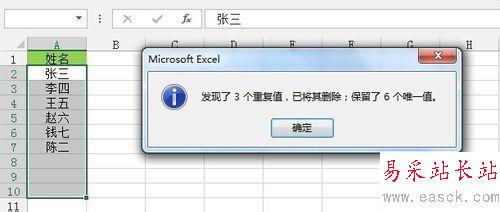
单击“数据”选项卡--》“数据工具”功能区--》“删除重复项”,弹出“删除重复项”对话框,单击“确定”即可删除单列数据重复值。如下图所示:
方法二:数据透视表法
依然使用上面的数据源,单击“插入”选项卡--》“表格”功能区--》“数据透视表”,出现如下图的提示框,这里我选择现有工作表的C1单元格(大家根据需要可以选择新工作表),单击“确定”完成数据透视表的创建,如下图:

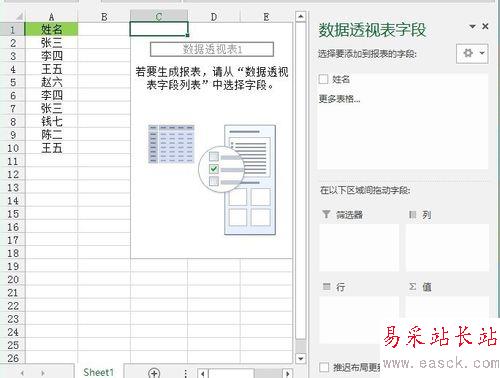
接着,勾选“姓名”前面的复选框,“姓名”字段就出现在《行》字段的框框里,如下图:
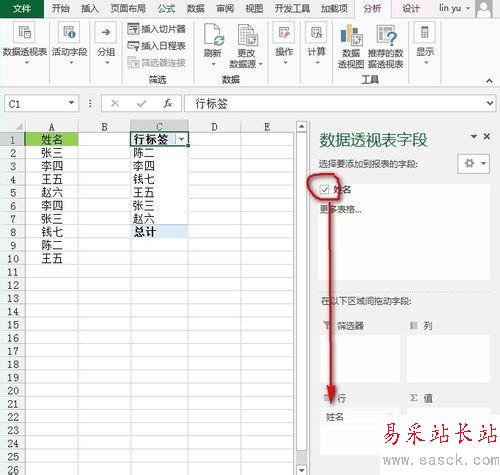
然后,我们对数据透视表的数据进行修饰,单击“行标签”所在的单元格,将单元格的文字改成“姓名”,然后单击数据透视表内的任意单元格,单击“数据透视表工具”--》“设计”选项卡--》“布局”功能区--》“总计”下的“对行和列禁用”按钮就完成了,如下图所示:
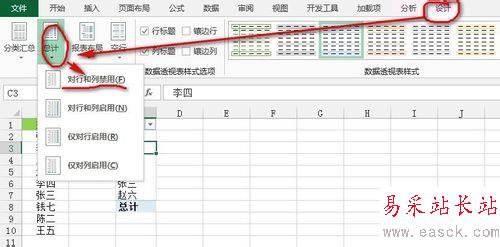
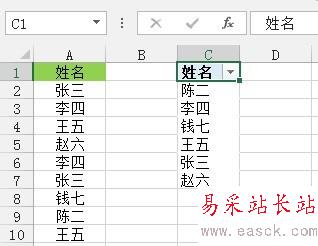
方法三:公式法
如图,在C1单元格输入如下公式,然后同时按Ctrl+Shift+Enter三个键结束,接着拖动输入公式单元格右下角的填充柄,完成此次不重复数据的筛选。
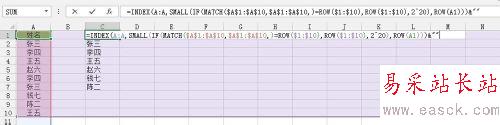
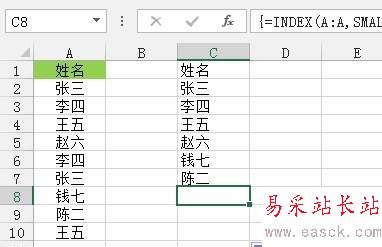
接着我们对公式进行逐步的讲解,首先,MATCH($A$1:$A$10,$A$1:$A$10,)=ROW($1:$10)表示查找A1至A10单元格在引用区域$A$1:$A$10的位置是否等于当前单元格行号所在的位置,如果相等,则说明该数据在这个区域中唯一,然后通过IF(MATCH())组合函数返回这个字段的行号,否则返回2^20=1048576,接着用SMALL函数对获取的行号进行升序排序,最后通过INDEX函数查找行号所在位置的值,&“”主要是为了容错处理,试想,如果数据都取完了,就剩下1048576的位置了,然后INDEX(A:A,1048576)=0,加个&“”则返回空文本。
新闻热点






疑难解答