数据库中的每个表都是由一个或多个列构成的。在用create table 语句创建一个表时,要为每列指定一个类型。列的类型比数据类型更为特殊,它仅仅是如“数”或“串”这样的通用类型。列的类型精确地描述了给定表列可能包含的值的种类,如smallint 或varchar( 3 2 )。
mysql的列类型是一种手段,通过这种手段可以描述一个表列包含什么类型的值,这又决定了mysql怎样处理这些值。例如,数值值既可用数值也可用串的列类型来存放,但是根据存放这些值的类型, mysql对它们的处理将会有些不同。每种列类型都有父鎏匦匀缦拢?br> ■ 其中可以存放什么类型的值。
■ 值要占据多少空间,以及该值是否是定长的(所有值占相同数量的空间)或可变长的(所占空间量依赖于所存储的值)。
■ 该类型的值怎样比较和存储。
■ 此类型是否允许null 值。
■ 此类型是否可以索引。
我们将简要地考察一下mysql列类型以获得一个总的概念,然后更详细地讨论描述每种列类型的属性。
2.2.1列类型概述
mysql为除null 值以外的所有通用数据类型的值都提供了列类型。在列是否能够包含null 值被视为一种类型属性的意义上,可认为所有类型都包含null属性。mysql有整数和浮点数值的列类型,如表2 - 2所示。整数列类型可以有符号也可无符号。有一种特殊的属性允许整数列值自动生成,这对需要唯一序列或标识号的应用系统来说是非常有用的。
mysql串列类型如表2 - 3所示。串可以存放任何内容,即使是像图像或声音这样的绝对二进制数据也可以存放。串在进行比较时可以设定是否区分大小写。此外,可对串进行模式匹配(实际上,在mysql中可以在任意列类型上进行模式匹配,但最经常进行模式匹配还是在串类型上)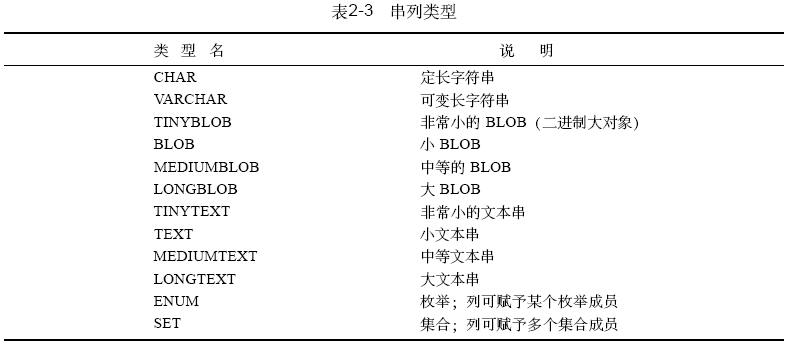
日期与时间列类型在表2 - 4中示出。对于临时值, mysql提供了日期(有或没有时间)、时间和时间戳(一种允许跟踪对记录何时进行最后更改的特殊类型)的类型。而且还提供了一种在不需要完整的日期时有效地表示年份的类型。
要创建一个表,应使用create table 语句并指定构成表列的列表。每个列都有一个名字和类型,以及与每个类型相关的各种属性。下面是创建具有三个分别名为f、c 和i 的列的表my_table 的例子:
定义一个列的语法如下: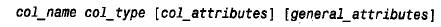
其中列名由col_name 给出。列名可最多包含64 个字符,字符包括字母、数字、下划线及美元符号。列名可以名字中合法的任何符号(包括数字)开头。但列名不能完全由数字组成,因为那样可能使其与数据分不开。mysql保留诸如s e l e c t、delete 和create 这样的词,这些词不能用做列名。但是函数名(如pos 和m i n)是可以使用的。
列类型col_type 表示列可存储的特定值。列类型说明符还能表示存放在列中的值的最大长度。对于某些类型,可用一个数值明确地说明其长度。而另外一些值,其长度由类型名蕴含。例如,char(10) 明确指定了10 个字符的长度。而tinyblob 值隐含最大长度为2 5 5个字符。有的类型说明符允许指定最大的显示宽度(即显示值时使用多少个字符)。浮点类型允许指定小数位数,所以能控制浮点数的精度值为多少。
可以在列类型之后指定可选的类型说明属性,以及指定更多的常见属性。属性起修饰类型的作用,并更改其处理列值的方式,属性有以下类型:
■ 专用属性用于指定列。例如,unsigned 属性只针对整型,而b i n a ry 属性只用于char 和varchar。
■ 通用属性除少数列之外可用于任意列。可以指定null 或not null 以表示某个列是否能够存放null。还可以用d e fa u lt def_value 来表示在创建一个新行但未明确给出该列的值时,该列可赋予值d e f _ v a l ue。def_value 必须为一个常量;它不能是表达式,也不能引用其他列。不能对blob 或text 列指定缺省值。
如果想给出多个列的专用属性,可按任意顺序指定它们,只要它们跟在列类型之后、通用属性之前即可。类似地,如果需要给出多个通用属性,也可按任意顺序给出它们,只要将它们放在列类型和可能给出的列专用属性之后即可。本节其余部分讨论每个mysql的列类型,给出定义类型和描述它们的属性的语法,诸如取值范围和存储需求等。类型说明如在create table 语句中那样给出。可选的信息由方括号([ ])给出。如,语mediumint[(m)] 表示最大显示宽度(指定为m)是可选的。另一方面,对于char( m ),无方括号表示的(m) 是必须的。
2.2.2 数值列类型
mysql的数值列类型有两种:
■ 整型。用于无小数部分的数,如1、4 3、- 3、0 或- 7 9 8 4 3 2。可对正数表示的数据使用整数列,如磅的近似数、英寸的近似数,银河系行星的数目、家族人数或一个盘子里的细菌数等。
■ 浮点数。用于可能具有小数部分的数,如3 . 14 15 9、- . 0 0 27 3、- 4 . 7 8、或3 9 . 3 e + 4。可将浮点数列类型用于有小数点部分或极大、极小的数。可能会表示为浮点数的值有农作物平均产量、距离、钱数(如物品价格或工资)、失业率或股票价格等等。整型值也可
以赋予浮点列,这时将它们表示为小数部分为零的浮点值。每种数值类型的名称和取值范围如表2 - 5所示。各种类型值所需的存储量如表2-6 所示。
create table 语句
本章中例子中大量使用了create table 语句。您应该对此语句相当熟悉,因为我们在第1章中的教程部分使用过它。关于create table 语句也可参阅附录d。
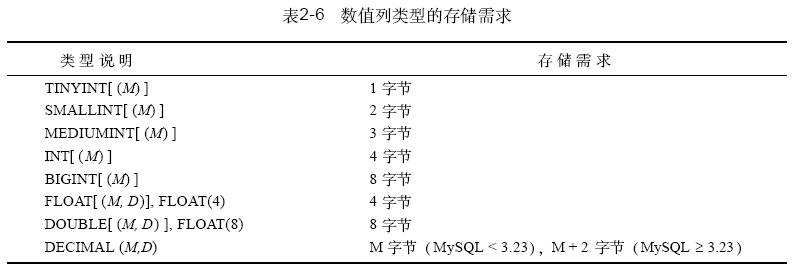
mysql提供了五种整型: t i n y i n t、s m a l l i n t、m e d i u m i n t、int 和b i g i n t。i n t 为i n t e g e r的缩写。这些类型在可表示的取值范围上是不同的。整数列可定义为unsigned 从而禁用负值;这使列的取值范围为0 以上。各种类型的存储量需求也是不同的。
取值范围较大的类型所需的存储量较大。
mysql提供三种浮点类型: float、double 和decimal。与整型不同,浮点类型不能是unsigned 的,其取值范围也与整型不同,这种不同不仅在于这些类型有最大值,而且还有最小非零值。最小值提供了相应类型精度的一种度量,这对于记录科学数据来说是非常重要的(当然,也有负的最大和最小值)。
double precision[(m, d)] 和real[(m, d)] 为double[(m, d)] 的同义词。而numeric(m, d) 为decimal(m, d) 的同义词。float(4) 和float(8) 是为了与odbc 兼容而提供的。在mysql3.23 以前,它们为float(10, 2) 和double(16, 4) 的同义词。自mysql3.23 以来,float(4) 和float(8) 各不相同,下面还要介绍。
在选择了某种数值类型时,应该考虑所要表示的值的范围,只需选择能覆盖要取值的范围的最小类型即可。选择较大类型会对空间造成浪费,使表不必要地增大,处理起来没有选择较小类型那样有效。对于整型值,如果数据取值范围较小,如人员年龄或兄弟姐妹数,则tinyint 最合适。mediumint 能够表示数百万的值并且可用于更多类型的值,但存储代价较大。bigint 在全部整型中取值范围最大,而且需要的存储空间是表示范围次大的整型i n t类型的两倍,因此只在确实需要时才用。对于浮点值, d o u b l e占用float的两倍空间。除非特别需要高精度或范围极大的值,一般应使用只用一半存储代价的float型来表示数据。
在定义整型列时,可以指定可选的显示尺寸m。如果这样,m 应该是一个1到255 的整数。它表示用来显示列中值的字符数。例如, mediumint(4) 指定了一个具有4 个字符显示宽度的mediumint 列。如果定义了一个没有明确宽度的整数列,将会自动分配给它一个缺省的宽度。缺省值为每种类型的“最长”值的长度。如果某个特定值的可打印表示需要不止m 个字符,则显示完全的值;不会将值截断以适合m 个字符。对每种浮点类型,可指定一个最大的显示尺寸m 和小数位数d。m 的值应该取1到2 5 5。d 的值可为0 到3 0,但是不应大于m - 2。(如果熟悉odbc 术语,就会知道m 和d 对应于
odbc 概念的“精度”和“小数点位数”)m 和d 对float和double 都是可选的,但对于decimal 是必须的。在选项m 和d时,如果省略了它们,则使用缺省值。下面的语句创建了一个表,它说明了数值列类型的m 和d 的缺省值(其中不包括decimal,因为m 和d 对这种类型不是可选的):
如果在创建表之后使用describe my_table 语句,则输出的field 和type 列如下所示(注意,如果用mysql的3.23 以前的版本运行这个查询,则有一个小故障, 即bigint 的显示宽度将是21而不是2 0。):
每一个数字列都具有一个由列类型所决定的取值范围。如果打算插入一个不在列范围内的值,将会进行截取:mysql将剪裁该值为取值范围的边界值并使用这个结果。在检索时不进行值的剪裁。
值的剪裁根据列类型的范围而不是显示宽度进行。例如,一个smallint(3) 列显示宽度为3 而取值范围为-32768 到3 27 6 7。值12345 比显示宽度大,但在该列的取值范围内,因此它可以插入而不用剪裁并且作为12345 检索。值99999 超出了取值范围,因此在插入时被剪裁为3 27 6 7。以后在检索中将以值3 27 6 7检索该值。
一般赋予浮点列的值被四舍五入到这个列所指定的十进制数。如果在一个float(8, 1)的列中存储1. 2 3 4 5 6,则结果为1. 2。如果将相同的值存入float(8, 4) 的列中,则结果为1. 2 3 4 6。这表示应该定义具有足够位数的浮点列以便得到尽可能精确的值。如果想精确到千分之一,那就不要定义使该类型仅有两位小数。
浮点值的这种处理在mysql3.23 中有例外,float(4) 和float(8) 的性能有所变化。这两种类型现在为单精度( 4 字节)和双精度( 8 字节)的类型,在其值按给出的形式存放(只受硬件的限制)这一点上说,这两种类型是真浮点类型。
decimal 类型不同于float和decimal,其中decimal 实际是以串存放的。decimal 可能的最大取值范围与double 一样,但是其有效的取值范围由m 和d 的值决定。如果改变m 而固定d,则其取值范围将随m 的变大而变大。表2 - 7的前三行说明了这一点。如果固定m 而改变d,则其取值范围将随d 的变大而变小(但精度增加)。表2 - 7的后三行说明了这一点。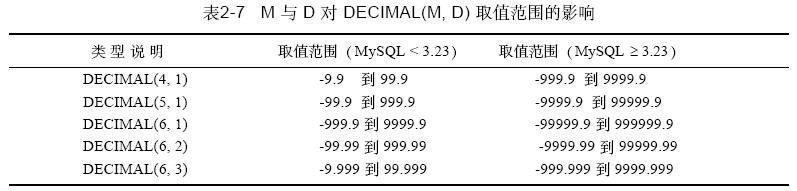
给定的decimal 类型的取值范围取决于mysql的版本。对于mysql3.23 以前的版本,decimal(m, d) 列的每个值占用m 字节,而符号(如果需要)和小数点包括在m 字节中。因此,类型为decimal(5, 2) 的列,其取值范围为-9.99 到9 9 . 9 9,因为它们覆盖了所有可能的5 个字符的值。
正如mysql3.23 一样,decimal 值是根据ansi 规范进行处理的, ansi 规范规定decimal(m, d) 必须能够表示m 位数字及d 位小数的任何值。例如, decimal(5, 2) 必须能够表示从-999.99 到999.99 的所有值。而且必须存储符号和小数点,因此自mysql3.23以来decimal 值占m + 2 个字节。对于decimal(5, 2),“最长”的值(- 9 9 9 . 9 9)需要7个字节。在正取值范围的一端,不需要正号,因此mysql利用它扩充了取值范围,使其超
过了ansi 所规范所要求的取值范围。如decimal(5, 2) 的最大值为9 9 9 9 . 9 9,因为有7 个字节可用。
简而言之,在mysql3.23 及以后的版本中,decimal(m, d) 的取值范围等于更早版本中的decimal(m + 2, d) 的取值范围。在mysql的所有版本中,如果某个decimal 列的d 为0,则不存储小数点。这样做的结果是扩充了列的取值范围,因为过去用来存储小数点的字节现在可用来存放其他数字了。
1. 数值列的类型属性
可对所有数值类型指定zerofill 属性。它使相应列的显示值用前导零来填充,以达到显示宽度。在希望确定列值总是以给定的数字位数显示时可利用z e r o f i l l。实际上,更准确地说是“一个给定的最小数目的数字位数”,因为比显示宽度更宽的值可完全显示而未被剪裁。使用下列语句可看到这一点:
其中select 语句的输出结果如下。请注意最后一行值,它比列的显示宽度更宽,但仍然完全显示出来: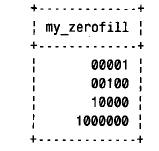
如下所示两个属性只用于整数列:
■ auto_increment。在需要产生唯一标识符或顺序值时,可利用auto_ increment属性。auto_increment 值一般从1开始,每行增加1。在插入null 到一个auto _increment 列时,mysql插入一个比该列中当前最大值大1的值。一个表中最多只能有一个auto_increment 列。对于任何想要使用auto_increment 的列,应该定义为not null,并定义为primary key 或定义为unique 键。例如, 可按下列任何一种方式定义auto_increment 列:
auto_increment 的性能将在下一小节“使用序列”中作进一步的介绍。
■ u n s i g n e d。此属性禁用负值。将列定义为unsigned 并不改变其基本数据类型的取值范围;它只是前移了取值的范围。考虑下列的表说明:
itiny 和itiny_u两列都是t i n y i n t列,并且都可取2 5 6个值,但是i t i n y的取值范围为-12 8 到127,而itiny_u的取值范围为0 到2 5 5。unsigned 对不取负值的列是非常有用的,如存入人口统计或出席人数的列。如果用常规的有符号列来存储这样的值,那么就只利用了该列类型取值范围的一半。通过使列为u n s i g n e d,能有效地成倍增加其取值范围。如果将列用于序列号,且将它设为u n s i g n e d,则可取原双倍的值。在指定以上属性之后(它们是专门用于数值列的),可以指定通用属性null 或n o tnull。如果未指定null 或not null,则缺省为null。也可以用d e fa u lt 属性来指定一个缺省值。如果不指定缺省值,则会自动选择一个。对于所有数值列类型,那些可以包含null 的列的缺省将为null,不能包含null 的列其缺省为0。下面的样例创建三个int 列,它们分别具有缺省值-1、1和null: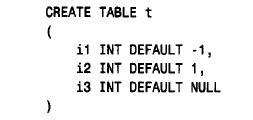
2. 使用序列
许多应用程序出于标识的目的需要使用唯一的号码。需要唯一值的这种要求在许多场合都会出现,如:会员号、试验样品编号、顾客id、错误报告或故障标签等等。auto_increment 列可提供唯一编号。这些列可自动生成顺序编号。本节描述auto_increment 列是怎样起作用的,从而使您能够有效地利用它们而不至于出错。另外,还介绍了怎样不用auto_increment 列来产生序列的方法。
(1) mysql3.23 以前的版本中的auto _ i n c r e m e n tmysql3.23 版以前的auto_increment 列的性能如下:
■ 插入null 到auto_increment 列,使mysql自动地产生下一个序列号并将此序列号自动地插入列中。auto_increment 序列从1开始,因此插入表中的第一个记录得到为1的序列值,而后继插入的记录分别得到序列值2、3 等等。一般,每个自动生成的值都比存储在该列中的当前最大值大1。
■ 插入0 到auto_increment 与插入null 到列中的效果一样。插入一行而不指定auto_increment 列的值也与插入null 的效果一样。
■ 如果插入一个记录并明确指定auto_increment 列的一个值,将会发生两件事之一。如果已经存在具有该值的某个记录,则出错,因为auto_increment 列中的值必须是惟一的。如果不存在具有该值的记录,那么新记录将被插入,并且如果新记录的auto_increment 列中的值是新的最大值,那么后续行将用该值的下一个值。换句话说,也就是可以通过插入一个具有比当前值大的序列值的记录,来增大序列的计数器。增大计数器会使序列出现空白,但这个特性也有用。例如创建一个具有auto _increment 列的表,但希望序列从1000 而不是1开始。则可以用后述的两种办法之一达到此目的。一个办法是插入具有明确序列值1000 的第一个记录,然后通过插入null 到auto_increment 列来插入后续的记录。另一个办法是插入
auto_increment 列值为999 的假记录。然后第一个实际插入的记录将得到一个序列号10 0 0,这时再将假记录删除。
■ 如果将一个不合规定的值插入auto_increment 列,将会出现难以预料的结果。
■ 如果删除了在auto_increment 列中含有最大值的记录,则此值在下一次产生新值时会再次使用。如果删除了表中的所有记录,则所有值都可以重用;相应的序列重新从1开始。
■ replace 语句正常起作用。
■ update语句按类似插入新记录的规则起作用。如果更新一个auto _ i n c r e m e n t列为null 或0,则会自动将其更新为下一个序列号。如果试图更新该列为一个已经存在的值,将出错(除非碰巧设置此列的值为它所具有的值,才不会出错,但这没有任何意义)。如果更新该列的值为一个比当前任何列值都大的值,则以后序列将从下一个值继续进行编号。
■ 最近自动产生的序列编号值可调用l a s t _ insert_id( ) 函数得到。它使得能在其他不知道此值的语句中引用auto_increment 值。l a s t _ insert_id( ) 依赖于当前服务器会话中生成的auto_increment 值; 它不受与其他客户机相关的auto_increment 活动的影响。如果当前会话中没有生成auto_increment 值,则l a s t _ insert_id( ) 返回0。能够自动生成顺序编号这个功能特别有用。但是刚才介绍的auto_increment 性能有两个缺陷。首先,序列中顶上的记录被删除时,序列值的重用使得难于生成可能删除和插入记录的应用的一系列单调(严格递增)值。其次,利用从大于1的值开始生成序列的方法是很笨的。
(2) mysql3.23 版以后的auto_incrementmysql3.23 对auto_increment 的性能进行了下列变动以便能够处理上述问题:
■ 自动顺序生成的值严格递增且不重用。如果最大的值为143 并删除了包含这个值的记录,mysql继续生成下一个值14 4。
■ 在创建表时,可以明确指定初始的序列编号。下面的例子创建一个auto _ i n c r e -ment 列seq 从1,000,000 开始的表:
在一个表具有多个列时(正如多数表那样),最后的auto_increment = 1000000子句应用到哪一列是不会混淆的,因为每个表只能有一个auto_increment 列。
(3) 使用auto_increment 应该考虑的问题在使用auto_increment 列时,应该记住下列要点:
■ auto_increment 不是一种列类型,它只是一种列类型属性。此外, auto _increment 是一种只能用于整数类型的属性。mysql早于3.23 的版本并不严格服从这个约束,允许定义诸如char 这样的列类型具有auto_increment 属性。但是只有整数类型作为auto_increment 列正常起作用。
■ auto_increment 机制的主要目的是生成一个正整数序列,并且如果以这种方式使用,则auto_increment 列效果最好。所以应该定义auto_increment 列为u n s i g n e d。这样做的优点是在到达列类型的取值范围上限前可以进行两倍的序列编号。在某些环境下,也有可能利用auto_increment 列来生成负值的序列,但是我们不建议这样做。如果您决定要试一下,应该保证进行充分的试验,并且在升级到不同的mysql版本时需要重新测试。笔者的经验表明,不同的版本中,负序列的性能并不完全一致。
■ 不要认为对某个列定义增加auto_increment 是一个得到无限的编号序列的奇妙方法。事实并非这样; auto_increment 序列受基础列类型的取值范围所限制。例如,如果使用tinyint unsigned 列,则最大的序列号为2 5 5。在达到这个界限时,应用程序将开始出现“重复键”错误。
■ mysql3.23 引入了不重用序列编号的新auto_increment 性能,并且允许在create table 语句中指定一个初始的序列编号。这些性能在使用下列形式的delete 语句删除了表中所有记录后可以撤消:
在此情形下,序列重新从1开始而不按严格的增量顺序继续增加。即使在c r e at etable 语句中明确指定了一个初始的序列编号,相应的序列也会从头开始。出现这种情形的原因在于mysql优化完全删空一个表的delete 语句的方法上;它从头开始重新创建数据文件和索引文件而不是去删除每个记录,这样就丢失了所有的序列号信息。如果要删除所有记录,但希望保留序列信息,可以取消优化并强制mysql执行逐行的删除操作,如下所示: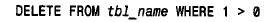
如果使用的是3 . 2 3以上的版本,怎样保持严格的增量序列?方法之一是保持一个只用来生成auto_increment 值的独立的表,永远不从这个表中删除记录。在这种情况下,独立表中的值永远不会重用。在主表中需要生成一个新记录时,首先在序列编号表中插入一个null。然后对希望包含序列编号的列使用l a s t _ insert_id( ) 的值将该记录插入主表,如下所示:
如果想要编写一个生成auto_increment 值的应用程序,但希望序列从100 而不是1开始。再假定希望这个程序可移植到所有mysql版本。怎样来完成它呢?如果可移植是一个目标,那么不能依赖mysql3.23 所提供的在create table 语句中指定初始序列编号的功能。而是在想要插入一个记录时,首先用下列语句检查表是否是空的: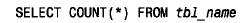
这个步骤虽然是附加的,但不会花费太多的时间,因为没有where 子句的select count(*) 是优化的,返回很快。如果表是空的,则插入记录并明确地对序列编号列指定值10 0。如果表不空,则对序列编号列值指定null 使mysql自动生成下一个编号。此方法允许插入序列编号为10 0、101等的记录,它不管mysql是否允许指定初始序列值都能正常工作。如果要求序列编号即使是从表中删除了记录后也要严格递增,则此方法不起作用。在这样的情形下,可将此方法与前面描述的什么也不做只是用来产生用于主表的序列编号的辅助表技术结合使用。为什么会希望从一个大于1的序列编号开始呢?一个原因是想使所有序列编号全都具有相同的数字位数。如果需要生成顾客id 号,并且希望不要多于一百万个顾客,则可以从1000 000
开始编号。在对顾客id 值计数的数字位数改变之前,可以追加一百万个顾客。当然,强制序列编号为一个固定宽度的另一个方法是采用zerofill 列。对于有的情形,这样做有可能会出问题。例如,如果在perl 或php 脚本中处理具有前导零的序列编号,则必须仔细地将它们只作为串使用;如果将它们转换成数字,前导零将会丢失。下面的短perl 脚本说明了处理编号时可能会出的问题: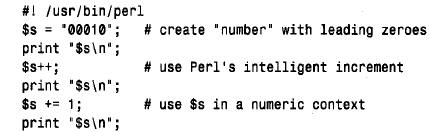
打印时,此脚本给出下列输出:
perl’s‘+ +’自动增量操作是很灵巧的而且可以利用串或数值建立序列值,但‘+ =’操作只应用于数值。在所显示的输出中,可看到‘ + =’引起串到数值的转换并且丢失了$s 值中的前导零。
序列不从1开始的另一个原因从技术的角度来说可能不值一提。例如,在分配会员号时,序列号不要从1开始,以免出现关于谁是第一号的政治争论。
(4) 不用auto_increment 生成序列生成序列号的另一个方法根本就不需要使用auto_increment 列。它利用取一个参数的l a s t _ insert_id( ) 函数的变量来生成序列号。(这种形式在mysql3.22.9. 中引入)如果利用l a s t _ insert_id(expr) 来插入或更新一个列, 则下一次不用参数调用l a s t _ insert_id( ) 时,将返回expr 的值。换句话说,就像由auto_increment 机制生成的那样对expr 进行处理。这样使得能生成一个序列号,然后可在以后的客户会话中利用它,用不着取受其他客户机影响的值。利用这种策略的一种方法是创建一个包含一个值的单行表,该值在想得到序列中下一个值时进行更新。例如,可创建如下的表: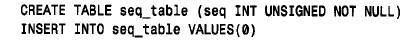
上面的语句创建了表seq_table 并用包含seq 值0 的行对其进行初始化。可利用这个表产生下一个序列号,如下所示: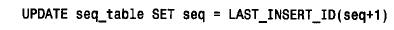
该语句取出seq 列的当前值并对其加1,产生序列中的下一个值。利用l a s t _ insert _id(seq + 1) 生成新值使它就像一个auto_increment 值一样,而且此值可在以后的语句中通过调用无参数的l a s t _ insert_id( ) 来取出。即使某个其他客户机同时生成了另一个序列号,上述作用也不会改变,因为l a s t _ insert_id( ) 是客户机专用的。如果希望生成增量不是1的编号序列或负增量的编号序列,也可以利用这个方法。例如,下面两个语句可以用来分别生成一个增量为100 的编号序列和一个负的编号序列: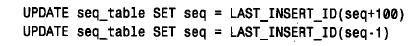
通过将seq 列设置为相应的初始值,可利用这个方法生成以任意值开始的序列。关于将此序列生成方法用于多个计数器的应用,可参阅第3章。
2.2.3 串列类型
mysql提供了几种存放字符数据的串类型。串常常用于如下这样的值:
在某种意义上,串实际是一种“通用”类型,因为可用它们来表示任意值。例如,可用串类型来存储二进制数据,如影像或声音,或者存储gzip 的输出结果,即存储压缩数据。对于所有串类型,都要剪裁过长的值使其适合于相应的串类型。但是串类型的取值范围很不同,有的取值范围很小,有的则很大。取值大的串类型能够存储近4gb 的数据。因此,应该使串足够长以免您的信息被切断(由于受客户机/服务器通信协议的最大块尺寸限制,列
值的最大限额为2 4 mb)。
表2 - 8给出了mysql定义串值列的类型,以及每种类型的最大尺寸和存储需求。对于可变长的列类型,各行的值所占的存储量是不同的,这取决于实际存放在列中的值的长度。这个长度在表中用l 表示。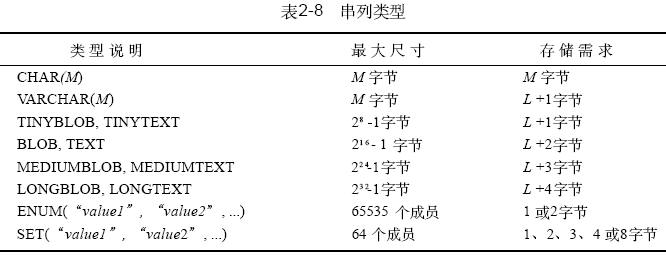
l 以外所需的额外字节为存放该值的长度所需的字节数。mysql通过存储值的内容及其长度来处理可变长度的值。这些额外的字节是无符号整数。请注意,可变长类型的最大长度、此类型所需的额外字节数以及占用相同字节数的无符号整数之间的对应关系。例如,
mediumblob 值可能最多22 4 - 1字节长并需要3 个字节记录其结果。3 个字节的整数类型mediumint 的最大无符号值为22 4 - 1。这并非偶然。
1. char 和varchar 列类型
char 和varchar 是最常使用的串类型。它们是有差异的, char 是定长类型而varchar 是可变长类型。char(m) 列中的每个值占m 个字节;短于m 个字节的值存储时在右边加空格(但右边的空格在检索时去掉)。varchar(m) 列的值只用所必需的字节数来存放(结尾的空格在存储时去掉,这与ansi sql 的varchar 值的标准不同),然后再加一个字节记录其长度。如果所需的值在长度上变化不大,则char 是一种比varchar 好的选择,因为处理行长度固定的表比处理行长度可变的表的效率更高。如果所有的值长度相同,由于需要额外的字节来记录值的长度,varchar 实际占用了更多的空间。在mysql3.23 以前,char 和varchar 列用最大长度为1到255 的m 来定义。从mysql3.23 开始,char(0) 也是合法的了。在希望定义一个列,但由于尚不知道其长度,所以不想给其分配空间的情况下, char(0) 列作为占位符很有用处。以后可以用alte rtable 来加宽这个列。如果允许其为null,则char(0) 列也可以用来表示o n / o ff 值。这样的列可能取两个值,null 和空串。char(0) 列在表中所占的空间很小,只占一位。除少数情况外,在同一个表中不能混用char 和varchar。mysql根据情况甚至会将列从一种类型转换为另一种类型。这样做的原因如下:
■ 行定长的表比行可变长的表容易处理(其理由请参阅2 . 3节“选择列的类型”)。
■ 表行只在表中所有行为定长类型时是定长的。即使表中只有一列是可变长的,该表的行也是可变长的。
■ 因为在行可变长时定长行的性能优点完全失去。所以为了节省存储空间,在这种情况下最好也将定长列转换为可变长列。这表示,如果表中有varchar 列,那么表中不可能同时有char 列;mysql会自动地将它们转换为varchar 列。例如创建如下一个表:
请注意,varchar 列的出现使mysql将c1也转换成了varchar 类型。如果试图用alter table 将c1转换为char,将不起作用。将varchar 列转换为char 的惟一办法是同时转换表中所有varchar 列: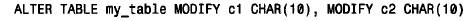
blob 和text 列类型像varchar 一样是可变长的,但是它们没有定长的等价类型,因此不能在同一表中与blob 或text 列一起使用char 列。这时任何char 列都将被转换为varchar 列。定长与可变长列混用的情形是在char 列短于4 个字符时,可以不对其进行转换。例如,mysql不会将下面所创建的表中的char 列转换为varchar 列:
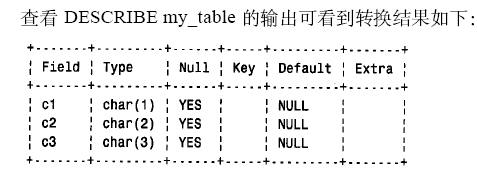
短于4个字符的列不转换的原因是,平均情况下,不存储尾空格所节省的空间被va r c ha r列中记录每个值的长度所需的额外字节所抵消了。实际上,如果所有列都短, mysql将会把所定义的所有列从varchar 转换为char。mysql这样做的原因是,这种转换平均来说不会增加存储需求,而且使表行定长,从而改善了性能。如果按如下创建一个表,varchar 列全都会转换为char 列:
2. blob 与text 列类型
blob 是一个二进制大对象,是一个可以存储大量数据的容器,可以使其任意大。在mysql中,blob 类型实际是一个类型系列( t i n y b l o b、b l o b、m e d i u mb l o b、l o n g b l o b),除了在可以存储的最大信息量上不同外(请参阅表2 - 8),它们是等同的。
mysql还有一个text 类型系列( t i n y t e x t、t e x t、m e d i u m t e x t、l o n g t e x t)。除了用于比较和排序外,它们在各个方面都与相应的blob 类型等同,blob 值是区分大小写的,而text 值不区分大小写。blob 和text 列对于存储可能有很大增长的值或各行大小有很大变化的值很有用,例如,字处理文档、图像和声音、混合数据以及新闻文章等等。blob 或text 列在mysql3.23 以上版本中可以进行索引,虽然在索引时必须指定一个用于索引的约束尺寸,以免建立出很大的索引项从而抵消索引所带来的好处。除此之外,一般不通过查找blob 或text 列来进行搜索,因为这样的列常常包含二进制数据(如图像)。常见的做法是用表中另外的列来记录有关blob 或text 值的某种标识信息,并用这些信息来确定想要哪些行。使用blob 和text 列需要特别注意以下几点:
■ 由于blob 和text 值的大小变化很大,如果进行的删除和更新很多,则存储它们的
表出现高碎片率会很高。应该定期地运行optimize table 减少碎片率以保持良好的
性能。要了解更详细的信息请参阅第4章。
■ 如果使用非常大的值,可能会需要调整服务器增加max_allowed_packet 参数的值。详细的信息请参阅第11章“常规的mysql管理”。如果需要增加希望使用非常大的值的客户机的块尺寸,可见附录e“mysql程序参考”,该附录介绍了怎样对mysql和mysqldump 客户机进行这种块尺寸的增加。
3. enum 和set 列类型
enum 和set 是一种特殊的串类型,其列值必须从一个固定的串集中选择。它们之间的主要差别是enum 列值必须确实是值集中的一个成员,而set 列值可以包括集合中任意或所有的成员。换句话说, enum 用于互相排斥的值,而s e t列可以从一个值的列表中选择多个值。
enum 列类型定义了一个枚举。可赋予enum 列一个在创建表时指定的值列表中选择的成员。枚举可具有最多65 536 个成员(其中之一为mysql保留)。枚举通常用来表示类别值。例如,定义为enum (“n”, “y”) 的列中的值可以是“n”或“y”。或者可将enum 用于诸如调查或问卷中的多项选择问题,或用于某个产品的可能尺寸或颜色等:
如果正在处理web 页中的选择,那么可以利用enum 来表示站点访问者在某页上的互相排斥的单选钮集合中进行的选择。例如,如果运行一个在线比萨饼订购服务系统,可用enum 来表示顾客订购的比萨饼形状: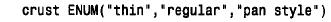
如果枚举类别表示计数,在建立该枚举时最重要的是选择合适的类别。例如,在记录实验室检验中白血球的数目时,可能会将计数分为如下的几组: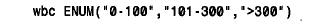
在某个测试结果以精确的计数到达时,要根据该值所属的类别来记录它。但如果想将列从基于类别的enum 转换为基于精确计数的整数时,不可能恢复原来的计数。在创建set 列时,要指定一个合法的集合成员列表。在这种意义上, set 类型与enum是类似的。但是set 与enum 不同,每个列值可由来自集合中任意数目的成员组成。集合中最多可有64 个成员。对于值之间互斥的固定集合,可使用set 列类型。例如,可利用set 来表示汽车的可用选件,如下所示:
然后,特定的set 值将表示顾客实际订购哪些选件,如下所示:
空串表示顾客未订购任何选件。这是一个合法的set 值。set 列值为单个串。如果某个值由多个集合成员组成,那么这些成员在串中用逗号分隔。显然,这表示不应该用含有逗号的串作为set 成员。set 列的其他用途是表示诸如病人的诊断或来自web 页的选择结果这样的信息。对于诊断,可能会有一个向病人提问的标准症状清单,而病人可能会表现出某些症状或所有的症状。对于在线比萨饼服务系统,用于订购的web 页应该具有一组复选框,用来表示顾客想在比萨饼上加的配料。对enum 或set 列的合法值列表的定义很重要,例如:
■ 正如上面所介绍的,此列表决定了列的可能合法值。
■ 可按任意的大小写字符插入enum 或set 值,但是列定义中指定的串的大小写字符决定了以后检索它们时的大小写。例如,如果有一个enum (“y”, “n”) 列,但您在其中存储了“ y”和“n”,当您检索出它们时显示的是“ y”和“n”。这并不影响比较或排序的状态,因为enum 和set 列是不区分大小写的。
■ 在enum 定义中的值顺序就是排序顺序。set 定义中的值顺序也决定了排序顺序,但是这个关系更为复杂,因为列值可能包括多个集合成员。
■ set 定义中的值顺序决定了在显示由多个集合成员组成的set 列值时,子串出现的顺序。
enum 和set 被归为串类型是由于在建立这些类型的列时,枚举和集合成员被指定为串。但是,这些成员在内部存放时作为数值,而且同样可作为数值来处理。这表示enum 和s e t类型比其他的串类型更为有效,因为通常可用数值运算而不是串运算来处理它们。而且这还表示enum 和set 值可用在串或数值的环境中。
列定义中的enum 成员是从1开始顺序编号的。(0 被mysql用作错误成员,如果以串的形式表示就是空串。)枚举值的数目决定了enum 列的存储大小。一个字节可表示256 个值,两个字节可表示65 536 个值。(可将其与一字节和两字节的整数类型t i n y i n t、
unsigned 和smallint unsigned 进行对比。)因此,枚举成员的最大数目为65 536(包括错误成员),并且存储大小依赖于成员数目是否多于256 个。在enum 定义中,可以最多指定65 535(而不是65 536)个成员,因为mysql保留了一个错误成员,它是每个枚举的隐含成员。在将一个非法值赋给enum 列时,mysql自动将其换成错误成员。下面有一个例子,可用mysql客户机程序测试一下。它给出枚举成员的数值顺序,而且还说明了null 值无顺序编号:
可对enum 成员按名或者按编号进行运算,例如: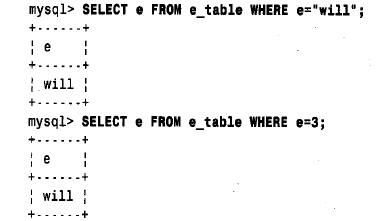
可以定义空串为一个合法的枚举成员。与列在定义中的其他成员一样,它将被赋予一个非零的数值。但是使用空串可能会引起某些混淆,因为该串也被作为数值为0 的错误成员。在下面的例子中,将非法的枚举值“ x”赋予enum 列引起了错误成员的赋值。仅在以数值
形式进行检索时,才能够与空串区分开:
set 列的数值表示与enum 列的表示有所不同,集合成员不是顺序编号的。每个成员对应set 值中的一个二进制位。第一个集合成员对应于0 位,第二个成员对应于1位,如此等等。数值set 值0 对应于空串。set 成员以位值保存。每个字节的8 个集合值可按此方式存
放,因此set 列的存储大小是由集合成员的数目决定的,最多64 个成员。对于大小为1到8、9 到16、17 到2 4、25 到3 2、33 到64 个成员的集合,其set 值分别占用1、2、3、4 或8个字节。
用一组二进制位来表示set 正是允许set 值由多个集合成员组成的原因。值中二进制位的任意组合都可以得到,因此,相应的值可由对应于这些二进制位的set 定义中的串组合构成。下面给出一个说明set 列的串形式与数值形式之间关系的样例;数值以十进制形式和二
进制形式分别给出: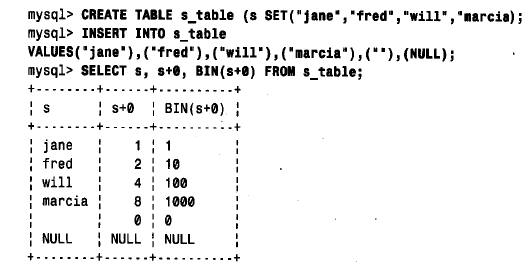
如果给set 列赋予一个含有未作为集合成员列出的子串的值,那么这些子串被删除,并将包含其余子串的值赋予该列。在赋值给set 列时,子串不需要按定义该列时的顺序给出。但是,在以后检索该值时,各成员将按定义时的顺序列出。假如用下面的定义定义一个s e t列来表示家具: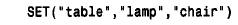
如果给这个列赋予“ c h a i r, couch, table”值,那么,“c o uc h”被放弃,因为它不是集合的成员。其次,以后检索这个值时,显示为“ table, chair”。之所以这样是因为mysql针对所赋的值的每个子串决定各个二进制位并在存储值时将它们置为1。“c o uc h”不对应二进制位,则忽略。在检索时,mysql按顺序扫描各二进制位,通过数值值构造出串值,它自动地将子串排成定义列时给出的顺序。这个举动还表示,如果在一个值中不止一次地指定某个成员,但在检索时它也只会出现一次。如果将“ lamp, lamp,lamp”赋予某个set 列,检索时也只会得出“l a m p”。mysql重新对set 值中的成员进行排序这个事实表示,如果用一个串来搜索值,则必须以正确的顺序列出各成员。如果插入“ c h a i r, table”,然后搜索“c h a i r, table”,那么将找不到相应的记录;必须查找“ table, chair”才能找到。enum 和set 列的排序和索引是根据列值的内部值(数值值)进行的。下面的例子可能会显示不正确,因为各个值并不是按字母顺序存储的:

null 值排在其他值前(如果是降序,将排在其他值之后)。如果有一个固定的值集,并且希望按特殊的次序进行排序,可利用enum 的排序顺序。在创建表时做一个enum 列,并在该列的定义中以所想要的次序给出各枚举值即可。如果希望enum 按正常的字典顺序排序,可使用c o n c at( ) 和排序结果将列转换成一个非enum 串,如下所示:
4. 串列类型属性
可对char 和varchar 类型指定b i n a ry 属性使列值作为二进制串处理(即,在比较和排序操作区分大小写)。
可对任何串类型指定通用属性null 和not null。如果两者都不指定,缺省值为null。但是定义某个串列为not null 并不阻止其取空串。空值不同于遗漏的值,因此,不要错误地认为可以通过定义not null 来强制某个串列只包含非空的值。如果要求串值非
空,那么这是一个在应用程序中必须强制实施的约束条件。
还可以对除blob 和text 类型外的所有串列类型用d e fa u lt 属性指定一个缺省值。如果不指定缺省值, mysql会自动选择一个。对于可以包含null 的列,其缺省值为null。对于不能包含null 的列,除enum 列外都为空串,在enum 列中,缺省值为第一个枚举成员(对于set 类型,在相应的列不能包含null 时其缺省值实际上是空集,不过这里空集等价于空串)。
2.2.4 日期和时间列类型
mysql提供了几种时间值的列类型,它们分别是: date、date time、time、times tamp 和year。表2-9 给出了mysql为定义存储日期和时间值所提供的这些类型,并给出了每种类型的合法取值范围。year 类型是在mysql3.22版本中引入的。其他类型在所有mysql版本中都可用。每种时间类型的存储需求见表2 - 10。每个日期和时间类型都有一个“零”值,在插入该类型的一个非法值时替换成此值,见表2 - 11。这个值也是定义为not null 的日期和时间列的缺省值。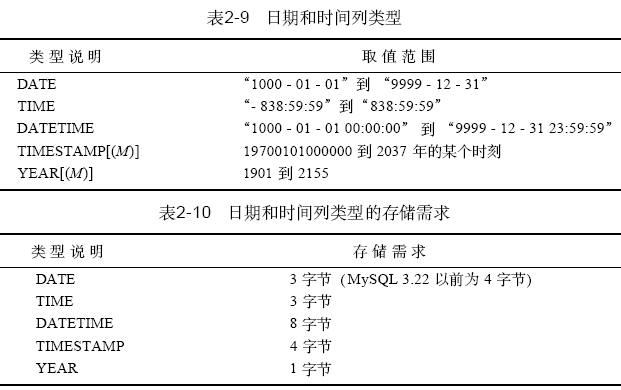
mysql表示日期时根据ansi 规范首先给出年份。例如,1999 年12 月3 日表示为“1999 - 12 - 0 3”。mysql允许在输入日期
时有某些活动的余地。如能将两个数字的年份转换成四位数字的年份,而且在输入小于10 的月份和日期时不用输入前面的那位数字。但是必须首先给出年份。平常经常使用的那些格式,如“ 12 / 3 / 9 9”或“3 / 12 / 9 9”,都是不正确的。mysql使用的日期表示规则请参阅“处理日期和时间列”小节。时间值按本地时区返回给服务器; mysql对返回给客户机的值不作任何时区调整。
1. date、time 和datetime 列类型date、time 和datetime 类型存储日期、时间以及日期和时间值的组合。其格式为“yyyy - mm - dd”、“h h : m m : s s”和“yyyy - mm - dd hh:mm:ss”。对于datetime 类型,日期和时间部分都需要;如果将date 值赋给datetime 列,mysql会自动地追加一个为“0 0 : 0 0 : 0 0”的时间部分。mysql对datetime 和time 表示的时间在处理上稍有不同。对于datetime ,时间部分表示某天的时间。而time 值表示占用的时间(这也就是为什么其取值范围如此之大而且允许取负值的原因)。用time 值的最右边部分表示秒,因此,如果插入一个“短”(不完全)的时间值,如“12 : 3 0”到time 列,则存储的值为“ 0 0 : 12 : 3 0”,即被认为是“12 分30 秒”。如果愿意,也可用time 列来表示天的时间,但是要记住这个转换规则以免出问题。为了插入一个“12 小时30 分钟”的值,必须将其表示为“ 12 : 3 0 : 0 0”。
2. timestamp 列类型
times tamp 列以yyyymmddhhmmss 的格式表示值,其取值范围从19700101000000到2037 年的某个时间。此取值范围与unix 的时间相联系,在unix 的时间中,1970 年的第一天为“零天”,也就是所谓的“新纪元”。因此1970 年的开始决定了t i m e s tamp 取值范围的低端。其取值范围的上端对应于unix 时间上的四字节界限,它可以表示到2037年的值。(times tamp 值的上限将会随着操作系统为扩充unix 的时间值所进行的修改而增加。这是在系统库一级必须提及的。mysql也将利用这些更改。)times tamp 类型之所以得到这样的名称是因为它在创建或修改某个记录时,有特殊的记录作用。如果在一个times tamp 列中插入null,则该列值将自动设置为当前的日期和时间。在建立或更新一行但不明确给times tamp 列赋值时也会自动设置该列的值为当前的日期和时间。但是,仅行中的第一个times tamp 列按此方式处理,即使是行中第一个timestamp列,也可以通过插入一个明确的日期和时间值到该列(而不是null)使该处理失效。
times tamp 列的定义可包含对最大显示宽度m 的说明。表2 - 12给出了所允许的m 值的显示格式。如果times tamp 定义中省略了m 或者其值为0或大于14,则该列按times tamp(14) 处理。取值范围从1到13的m 奇数值作为下一个更大的偶数值处理。t i m e s tamp 列的显示宽度与存储大小或存储在内部的值无关。times tamp 值总是以4 字节存放并按14 位精度进行计算,与显示宽度无关。为了明白这一点,按如下定义一个表,然后插入一些行,进行检索: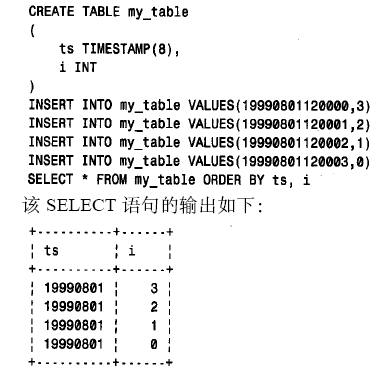
从表面上看,出现的行排序有误,第一列中的值全都相同,所以似乎排序是根据第二列中的值进行的。这个表面反常的结果是由于事实上, mysql是根据插入t i m e s tamp 列的全部14 位值进行排序的。mysql没有可在记录建立时设置为当前日期和时间、并从此以后保持不变的列类型。如果要实现这一点,可用两种方法来完成:
■ 使用t i m e s tamp 列。在最初建立一个记录时,设置该列为null,将其初始化为当前日期和时间: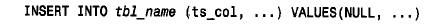
在以后无论何时更改此记录,都要明确地设置此列为其原有的值。赋予一个明确的值使时间戳机制失效,因为它阻止了该列的值自动更新: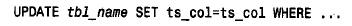
■ 使用datetime 列。在建立记录时,将该列的值初始化为now( ):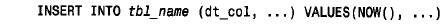
无论以后何时更新此记录,都不能动该列:updatetbl_name set /* angthing but dt_col here */ where ...如果想利用t i m e s tamp 列既保存建立的时间值又保存最后修改的时间值,那么可用一个t i m e s tamp 列来保存修改时间值,用另一个t i m e s tamp 列保存建立时间值。要保证保存修改时间值的列为第一个t i m e s ta m p,从而在记录建立或更改时自动对其进行设置。使保存建立时间值的列为第二个t i m e s ta m p,并在建立新记录时将其初始化为now( )。这样第二个t i m e s tamp 的值将反映记录建立时间,而且以后将不再更改。
3. year 列类型
year 是一个用来有效地表示年份值的1个字节的列类型。其取值范围为从1901到2 15 5。在想保存日期信息但又只需要日期的年份时可使用year 类型,如出生年份、政府机关选举年份等等。在不需要完全的日期值时, year 比其他日期类型在空间利用上更为有效。
year 列的定义可包括显示宽度m 的说明,显示宽度应该为4 或2。如果year 定义中省略了m,其缺省值为4。tinyint 与year 具有相同的存储大小(一个字节),但取值范围不同。要使用一个整数类型且覆盖与year 相同的取值范围,可能需要smallint 类型,此类型要占两倍的空间。在所要表示的年份取值范围与year 类型的取值范围相同的情况下, year 的空间利用率比smallint 更为有效。year 相对整数列的另一个优点是mysql将会利用mysql的年份推测规则把2 位值转换为4 位值。例如,97 与14 将转换为1997 和2 0 14。但要认识到,插入数值00 将得到0000 而不是2 0 0 0。如果希望零值转换为2 0 0 0,必须指定其为串“0 0”。
4. 日期和时间列类型的属性没有专门针对日期和时间列类型的属性。通用属性null 和not null 可用于任意日期和时间类型。如果null 和not null 两者都不指定,则缺省值为null。也可以用defa ult 属性指定一个缺省值。如果不指定缺省值,将自动选择一个缺
省值。含有null 的列的缺省值为null 。否则,缺省值为该类型的“零”值。
5. 处理日期和时间列mysql可以理解各种格式的日期和时间值。date 值可按后面的任何一种格式指定,其中包括串和数值形式。表2 - 13为每种日期和时间类型所允许的格式。两位数字的年度值的格式用“歧义年份值的解释”中所描述的规则来解释。对于有分隔
符的串格式,不一定非要用日期的“ -”符号和时间的“ :”符号来分隔,任何标点符号都可用作分隔符,因为值的解释取决于上下文,而不是取决于分隔符。例如,虽然时间一般是用分隔符“:”指定的,但mysql并不会在一个需要日期的上下文中将含有“ :”号的值理解成时间。此外,对于有分隔符的串格式,不需要为小于10 的月、日、小时、分钟或秒值指定两个数值。下列值是完全等同的: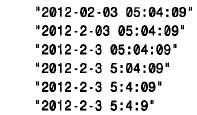
请注意,有前导零的值根据它们被指定为串或数有不同的解释。串“ 0 0 12 3 1”将视为一个六位数字的值并解释为date 的“2 0 0 0 - 12 - 3 1”和datetime 的“2000-12-3100:00:00”。而数0 0 12 3 1被认为12 3 1,这样的解释就有问题了。这种情形最好使用串值,或者如果要使用数值的话,应该用完全限定的值(即, date 用2 0 0 0 12 3 1,datetime 用2 0 0 0 12 3 10 0 0 0)。通常,在date、datetime 和t i m e s tamp 类型之间可以自由地赋值,但是应该记住以下一些限制:
■ 如果将datetime 或t i m e s tamp 值赋给date,则时间部分被删除。
■ 如果将date 值赋给datetime 或t i m e s ta m p,结果值的时间部分被设置为零。
■ 各种类型具有不同的取值范围。t i m e s tamp 的取值范围更受限制( 1970 到2 0 3 7),因此,比方说,不能将1970 年以前的datetime 值赋给t i m e s tamp 并得到合理的结果。也不能将2037 以后的值赋给times tamp。mysql提供了许多处理日期和时间值的函数。要了解更详细的信息请参阅附录c。
6. 歧义年份值的理解
对于所有包括年份部分的日期和时间类型( date、date time、time stamp、year),mysql将两位数字的年份转换为四位数字的年份。这个转换根据下列规则进行(在mysql4.0 中,这些规则稍有改动,其中69 将转换为1969 而不是2069。这是根据x/open unix 标准规定的规则作出的改动):
■ 00 到69 的年份值转换为2000 到2069。
■ 70 到99 的年份值转换为1970 到1999。
通过将不同的两位数字值赋给一个year 列然后进行检索,可很容易地看到这些规则的效果。下面是检索程序: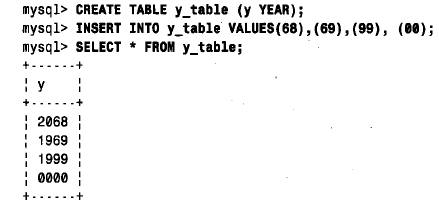
请注意,00 转换为0000 而不是2 0 0 0。这是因为0 是year 类型的一个完全合法的值;如果插入一个数值,得到的就是这个结果。要得到2 0 0 0,应该插入串“ 0”或“0 0”。可通过c o n c at( ) 插入year 值来保证mysql得到一个串而不是数。c o n c at( ) 函数不管其参数是串或数值,都返回一个串结果。请记住,将两位数字的年份值转换为四位数字的年份值的规则只产生一种结果。在未给
定世纪的情况下,mysql没有办法肯定两位数字的年份的含义。如果mysql的转换规则不能得出您所希望的值,解决的方法很简单:即用四位数字输入年份值。mysql有千年虫问题吗?mysql自身是没有2000 年问题的,因为它在内部是按四位数年份存储日期值的,并且由用户负责提供恰当的日期值。两位数字年份解释的实际问题不是mysql带来的,而是由于有的人想省事,输入歧义数据所引起的问题。如果您愿意冒险,可以继续这样做。在您冒险的时候,mysql的猜测规则是可以使用的。但要意识到,很多时候您确实需要输入四位数字的年份。例如, p r e s i d e n t表列出了1700 年以来的美国总统,所以在此表中录入出生与死亡日期需要四位的年份值。这些列中的年份值跨了好几个世纪,因此,让mysql从两位数字的年份去猜测是哪个世纪是不可能的。
新闻热点






疑难解答













