最大的网站源码资源下载站,
一、弄清结构再动手
要想轻松的抽取rss信息,自然先要了解它的结构,所谓“知己知彼,百战不殆”嘛。
1、rss的结构
我们先打开百度新闻一个rss链接,如果你再多打开几个别的网站的rss链接,会发现他们都有大致相同的结构。而我们在揭秘rss(上)中为大家讲解的其实就是编成实现这样的一个xml文件。
为了能够方便地对这样的xml文档进行处理,在本文里,我们使用c#作为开发的语言。
分析整个rss链接后,我们知道rss大致的结构入图1。
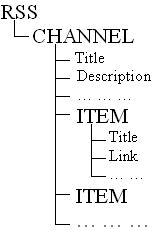
2、抽取的原理
知道了结构,我们还要知道结构中各部分的含义。在图1中rss节点表示当前是一个rss文件,它由一个channel节点及其子节点组成,其中一些子节点提供关于频道本身的信息,比如title表示频道的名称(“百度互联网新闻”)。
channel节点又包含多个item子节点,而item节点就是程序需要处理的部分,因为它对应着每条实际的新闻项信息, 每个item节点又通过其子节点提供关于这条新闻的详细信息,比如title表示新闻的标题(“微软im称王”),link对应新闻实际的链接。
rss具体规范可查看http://blogs.law.harvard.edu/tech/rss
知道了这些后,要编程就不困难啦。我们只需提取并显示出channel和item下的各条信息就可以了。现在来看看具体的实现方法吧。
二.做个程序读新闻
对rss有一定了解后,我们开始编写程序。先还是需要一个最简单的界面。新建一个win form 工程,在form上放置一个label,一个文本框txturl用来输入rss链接(就是各网站rss链接中包含的地址),一个按钮bnread用来执行读取新闻, 一个treeview树形控件treerss显示读出的新闻项。
1、定义装载结构
根据上面分析的rss结构,我们首先来建立一个rss类,用它来装载rss链接中channel和item的各条信息。代码如下:
public class rss
{
public struct channel
{
public string title;
public hashtable items;
}
public struct item
{
public string title;
public string description;
public string link;
}
}
channel结构将存储channel节点包含的所有子节点信息,其中items成员字段是一个hashtable集合,程序会将item结构作为对象加入集合,用来存储channel下的所有item节点。这里我只读取了有限的几个节点,读者可以根据实际需要扩展整个结构定义。 2、从rss链接中获取新闻信息
现在我们就可以开始编写读取函数,将抽取出的rss信息放入上面设计好的结构中。
c#提供了专门的类来访问xml, 使我们能够轻松地读出rss的内容。代码如下:
xmltextreader reader = new xmltextreader(url);
xmlvalidatingreader valid = new xmlvalidatingreader(reader);
valid.validationtype = validationtype.none;
xmldocument xmldoc= new xmldocument();
xmldoc.load(reader);
使用xmldocument类将txturl中输入的rss链接加载后,首先通过foundchildnode函数,找到channel节点。
private xmlnode foundchildnode(xmlnode node,string name)
{
xmlnode childlnode = null;
for (int i=0;i < node.childnodes.count;i++)
{
if ( node.childnodes[i].name == name && node.childnodes[i].childnodes.count > 0 )
{
childlnode = node.childnodes[i];
return childlnode;
}
}
return childlnode;
}
xmlnode rssnode = foundchildnode(xmldoc,"rss");
xmlnode channelnode = foundchildnode(rssnode,"channel");
然后我们就可以遍历它的子节点,根据子节点的name属性,读取我们需要的信息。
rss.channel channel=new rss.channel();
channel.items=new hashtable();
{
switch ( channelnode.childnodes[i].name )
{
case "title":
{
channel.title = channelnode.childnodes[i].innertext;
break;
}
case "item":
{
rss.item item=this.getrssitem(channelnode.childnodes[i]);
channel.items.add(channel.items.count,item );
break;
}
}
}
如果发现是item子节点,就调用getrssitem函数,同样通过遍历子节点的方法,将其子节点内容填入item结构中,然后再添加到channel结构的items集合中。因为本程序并不关心添加到集合的键值,只需要它是不重复的值,所以我传入了count属性。
3.将读出的信息显示在程序中
将rss内容读出后,就需要把信息展示给用户了。我们这里用的是基本的treeview方法,通过遍历channel结构的items集合,将其标题添加到treeview中。
private void viewrss(rss.channel channel)
{
treerss.beginupdate();
treerss.nodes.clear();
treenode channelnode=treerss.nodes.add(channel.title );
channelnode.tag="";
for (int i=0;i <channel.items.count ;i++)
{
rss.item item=(rss.item)channel.items[i];
treenode itemnode=channelnode.nodes.add(item.title );
itemnode.tag=item.link;
}
treerss.expandall();
treerss.endupdate();
}
同时我们还可以设置treeview的每个子节点的tag属性为它对应的链接。以便当选中子节点时就可以通过读取tag属性访问具体的信息。
private void treerss_afterselect(object sender, system.windows.forms.treevieweventargs e)
{
treenode itemnode=e.node ;
string url=itemnode.tag.tostring();
if (url.length!=0)
system.diagnostics.process.start( url);
}
程序运行效果如图2。
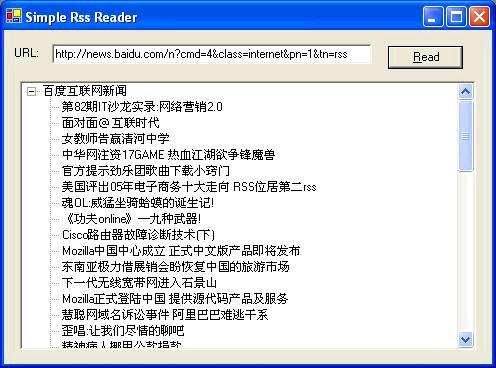
三.小结
怎么样,一个简单的rss新闻阅读器就按前面所说轻松完成了,容易吧。虽然它还有很多不足,但如果大家通过这个例子学会了抽取rss链接信息的基本方法,那就足够了!



















