hibernate synchronizer
迄今为止,在我找到的插件中,hibernate synchronizer最令我感兴趣,因为看起来它对以映射为中心的工作流提供了最好的支持,而我的developer's notebook一书中就采用了这种工作流。(hibernate可以用于多种用途,所以请查看可用的其他插件,如果您的环境需要其他方法,这些插件将更有帮助。)事实上,hibernate synchronizer插件让您在修改映射文档时,无需考虑更新java代码,它会在您进行编辑的时候以一种非常类似于eclipse的方式自动更新java代码。通过为每个被映射的对象创建一对类,它比hibernate的内置代码生成工具更为先进。它“拥有”一个基类,当您修改映射时,它可以随意重写这个基类。它还提供一个扩展了这个基类的子类,可以在这个子类中加入业务逻辑和其他代码,而无需担心它会在您眼皮底下消失。
因为要适用于以hibernate映射文档为中心的方法,hibernate synchronizer还包括一个用于eclipse的新编辑器组件,为此类文档提供智能辅助和代码自动完成功能。优秀的dtd驱动的xml编辑器(比如前面提到过的xmlbuddy)可以实现其中的一些功能,但是hibernate synchronizer利用对文档语义的理解做得更好。它还提供了一个映射中的属性和关系的图形化视图、创建新元素的“向导”界面,以及其他类似的优点。而且如前所述,在其默认配置中,编辑器会在用户编辑映射文档时自动重新生成数据访问类。
hibernate synchronizer还有其他的功能。它在eclipse的new菜单中加入了一个区域,为创建hibernate配置和映射文件提供向导,并在包的资源管理器和其他适当的位置中添加了上下文菜单项,使用户可以轻松访问相关的hibernate操作。
好了,现在已经有了足够多的抽象描述,是时候开始实践了!毕竟,您很可能对此产生了兴趣,要不您就不会阅读本文。那么,如何安装与使用hibernate synchronizer呢?
安装启动eclipse,选择help -> software updates -> update manager,便可以打开update manager。install/update透视图打开之后,在feature updates视图中右击(或者控件单击(control-click),如果您使用的是单按钮鼠标),选择new -> site bookmark,如图1所示。
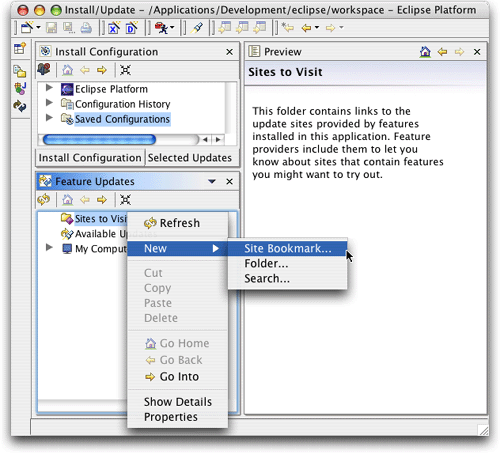
图1. 向update manager添加hibernate synchronizer插件站点
在出现的对话框中,输入所需插件版本的url。输入的url取决于您的eclipse版本:
还需为新的书签指定一个名称,“hibernate synchronizer”就很好。图2显示的对话框包括了我的eclipse 2.1.2环境中的所有必需信息。
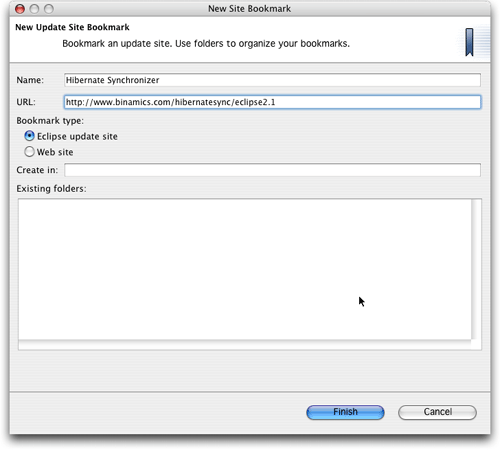
图2. hibernate synchronizer插件更新站点的书签
单击finish之后,新的书签将出现在feature updates视图中,如图3所示。
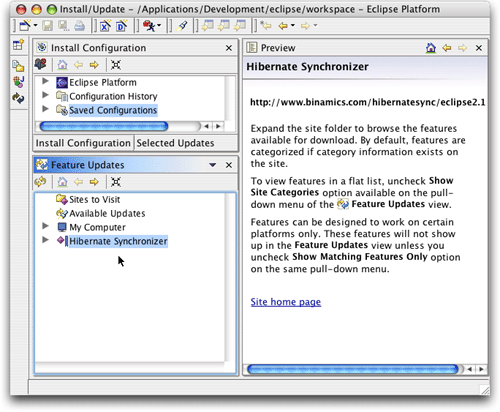
图3. hibernate synchronizer站点现在可用了
为了实际安装插件,单击书签左侧的三角形展开符号,然后单击其中的下一个三角形展开符号,重复这个过程,直到出现插件的图标为止。单击该图标,preview视图就会更新,从而显示一个允许安装插件的界面,如图4所示。
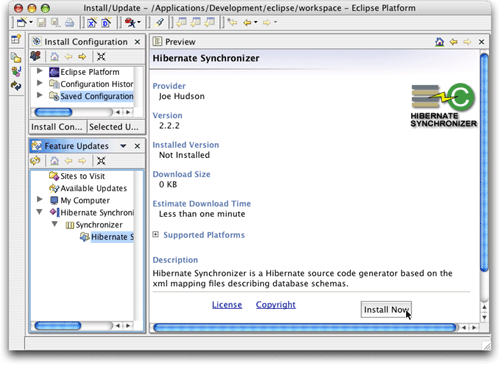
图4. 准备安装插件
单击install now,实际安装插件,让eclipse引领您完成整个过程(图5-10)。
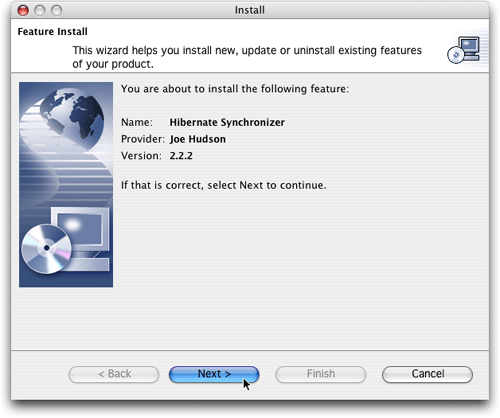
图5.安装hibernate synchronizer
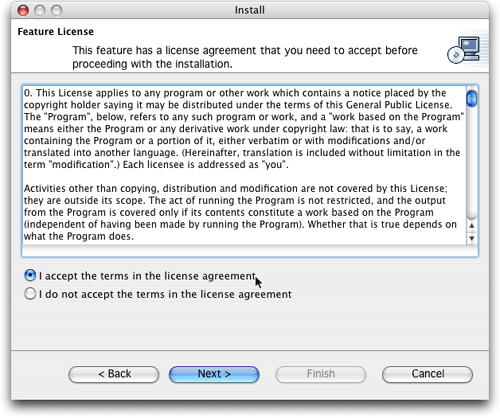
图6. 插件许可证协议
可参见下面的权衡部分,其中有关于许可证协议的一些讨论。在决定在自己的项目中使用hibernate synchronizer之前,您可能想仔细阅读一下它。我认为这是很好的做法,但是令人困惑的是,它基于gpl,实际上并非是开源的。
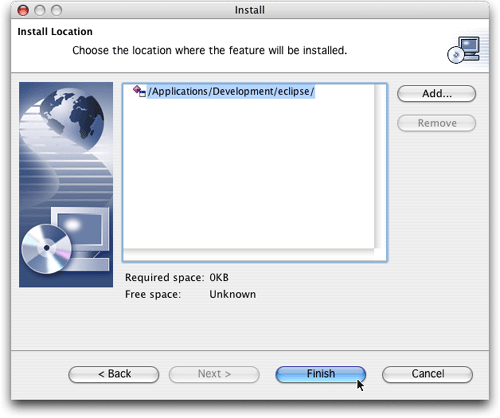
图7. 选择安装插件的位置,使用默认的就可以
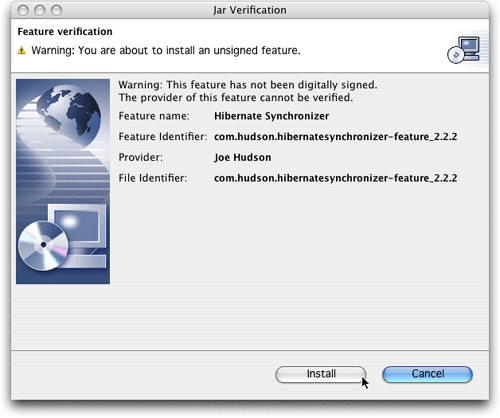
图8.对没有签名的插件发出的标准警告
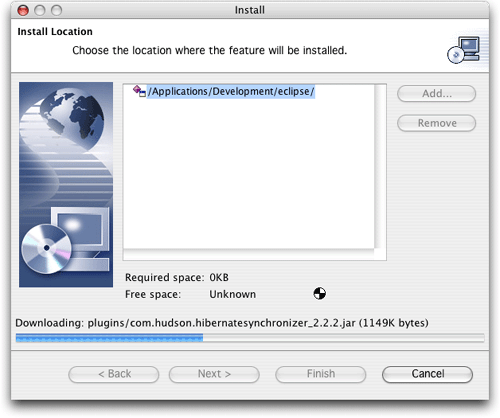
图9.正在安装
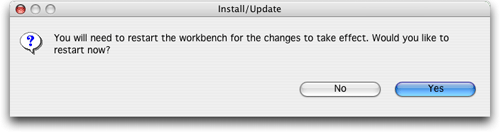
图10.安装完毕
现在插件已经安装完毕,需要退出并重新运行eclipse,以便使其生效。出现的对话框似乎暗示eclipse将自动重启,但是根据我的经验,单击yes只会退出环境,必须手动重启。这可能是eclipse 2.1的mac os x实现的一个局限性;eclipse 3将成为首个承诺对os x提供一流支持的版本。不管怎么说,这是一个小问题。如果需要重启eclipse,现在就重启吧,因为应该开始配置插件了!
配置
eclipse重新启动之后,可以关闭install/update透视图。打开一个使用hibernate的java项目。如果您读过developer's notebook一书中的例子,那么有几个目录可供选择。我将选用第3章中的例子,因为这一章是可以在线阅读的样章。您还可以从该书的站点下载所有例子的源代码。
如果您准备创建一个新的eclipse项目,以便使用示例源代码目录中的一个,只需选择file -> new -> project。选择创建一个java项目,然后单击next,为其命名(我使用的是“hibernate ch3”,如图11所示),取消对use default复选框的选择,以便可以告诉eclipse现有项目目录的位置,然后单击browse按钮,定位它在驱动器上的具体位置。现在可以单击finish,创建该项目,但是我一般喜欢单击next,然后再次检查eclipse的选择。(当然,如果有什么出错,您始终可以返回并修改项目属性,但是我发现,如果存在库丢失之类的错误,马上就会面对大量的错误和警告,这实在是一件麻烦的事情。)
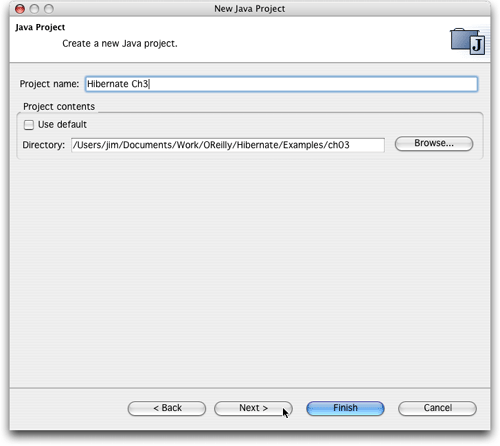
图11. 创建一个使用hibernate的新项目
此处我的警告是多余的。eclipse清楚目录的架构及用法,还找出了我曾下载和安装过的所有第三方库,以便让hibernate和hsqldb数据库引擎能够运行。这种智能适应性是eclipse的重要特性之一。图12显示我们的新项目已经打开并准备好用于实验了。它还显示,eclipse不喜欢把窗口缩到足够小以适应适当的屏幕快照。从现在起,我只能捕捉窗口的一部分。
图12. 第3章中的示例项目
接下来要创建一个hibernate synchronizer可以使用的hibernate配置文件。src目录中已经存在一个hibernate.properties文件,它说明了书中例子的配置,但是hibernate synchronizer只能使用hibernate的基于xml的配置方法。所以,我们需要把hibernate.properties文件的内容复制到一个新的hibernate.cfg.xml文件中去。从好的方面来说,这使我们可以见识hibernate synchronizer的一项特性,即配置文件向导。选择file -> new -> other,单击新可用的hibernate类别,选中hibernate configuration file,然后单击next。
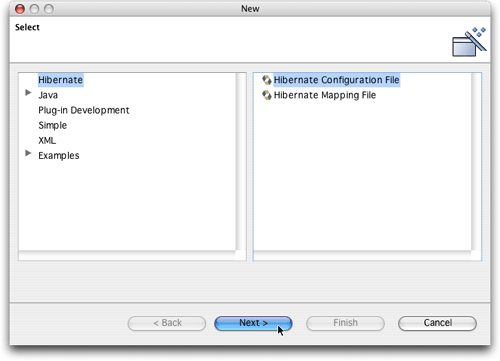
图13. 启动hibernate configuration file向导
当向导启动后,它所提供的用于放置文件的目录取决于当前在eclipse中选中的文件。出于一致性方面的考虑,一定要把它和properties版本一起放在顶级的src目录中。填入向导所需的其余信息,匹配配置的properties版本,如图14所示。注意,与使用ant控制hibernate的执行(这是developer's notebook一书中所使用的方法)不同,当调用hibernate时,我们无法控制当前的工作目录,所以需要在url中使用一条到数据库文件的完全限定路径。我使用的值是(有点难看):jdbc:hsqldb:/users/jim/documents/work/oreilly/hibernate/examples/ch03/data/music。(如果有人能告诉我如何让eclipse或hibernate synchironizer对一个项目使用特定的工作目录,我肯定会很感兴趣。我在eclipse方面还是一个新手,所以如果知道这种情况是可能的,只是我不知道如何去做,我肯定不会感到吃惊。)
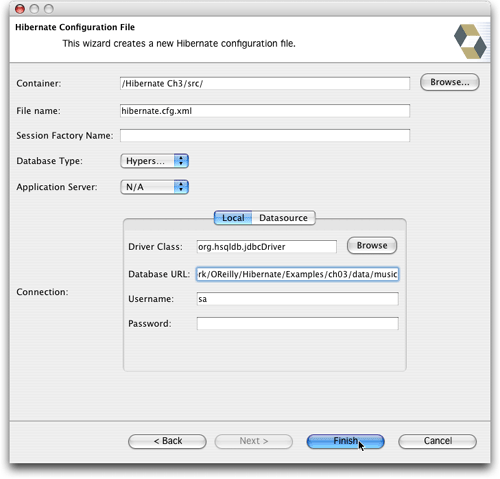
图14. 填写配置文件的详细信息
填写driver class时有一点奇怪:需要单击browse按钮,并开始输入驱动程序的类名。如果输入“jdbcd”,窗口将只会给出两个选择,很容易就可以找出正确的选择,如图15所示。
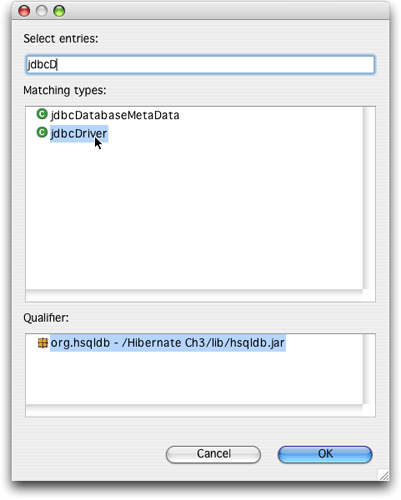
图15. 指定hsqldb驱动程序类
按照图14所示设置适用于您自己的安装的值之后,就可以单击finish来创建配置文件。hibernate synchronizer现在已经可以使用了。它打开了创建的文件,所以可以看到一个hibernate的xml配置文件的结构和详细信息。
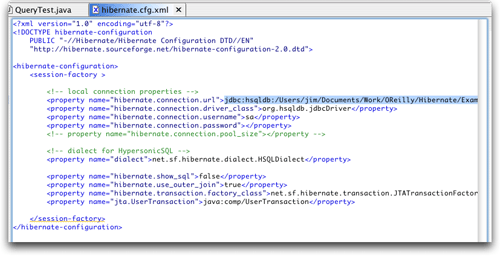
图16. 生成的配置文件
一种快速测试该配置是否生效的方式是使用其他的向导界面。选择file -> new -> other,单击新可用的hibernate类别,选中hibernate mapping file,然后单击next。当向导出现时,它应该填充了刚才输入的所有设置信息,可以单击refresh按钮来确定它可以与数据库通信,它还会显示找到了一个track表。第一次这样做的时候,由于某种原因,您可能必须确认包含hsqldb驱动程序的.jar文件的位置,但是这种情况只会发生一次。不管怎样,确认了一切正常之后,单击cancel,而不是实际创建映射,因为我们想使用手动创建的已有映射文件。
生成代码
这很可能是您一直期待的部分。我们可以做些什么特别的呢?马上就有一个可用于hibernate映射文档的新上下文菜单项。
如果右击(或控制单击)任意一项,将会看到很多与hibernate相关的选项(图17),其中包括一个同步选项。这是一种手动让hibernate synchronizer生成与映射文档相关的数据访问对象的方式。
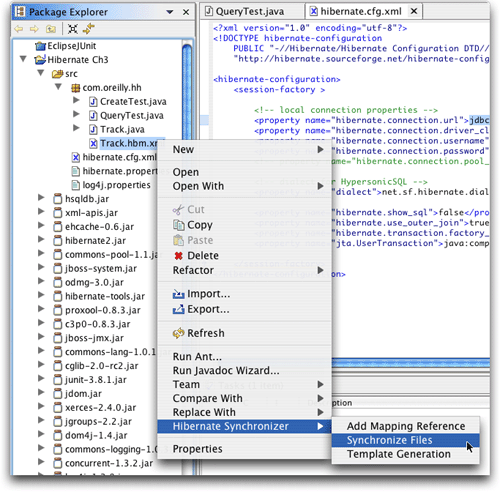
图17.映射文档的同步选项
add mapping reference选项也很有用:它在主hibernate配置文件中添加了一项,告知有关该映射文档的信息,所以无需在源代码中加入任何内容来要求配置相应的映射。现在我们来看看选择synchronize files的结果。
到这里事情开始变得有趣了。出现了两个新的子包,一个用于hibernate synchronizer“拥有的”“基”数据访问对象,可以在任何时候进行改写,而另一个用于为这些dao生成子类的业务对象,它不会被重写,这为我们提供了一个向数据类添加业务逻辑的机会(如图18所示)。
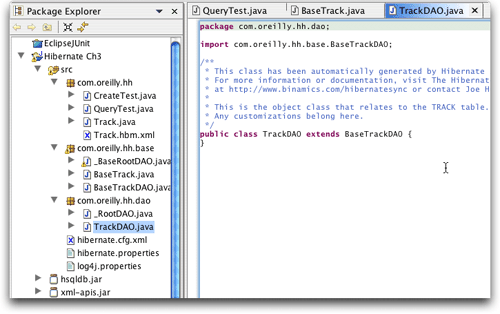
图18. 经过同步的数据访问对象,显示了可编辑的子类
这样生成的类比使用常规的hibernate代码生成工具生成的类要多很多,这有一些优点以及一些潜在的缺点,在稍后的权衡部分中我们将讨论这些。还要注意,可以在项目的属性配置中选择生成其中的哪些类,以及生成它们的包结构。我本来应该演示一下的,但是当前的插件版本有一个bug,它阻止了在mac os x上对这个配置界面进行访问。补丁已经开发出来了,但尚未发布。
基于hibernate synchronizer页面上的例子与下面的类,我试图使用这些新的数据访问对象插入一些数据到音乐数据库中。这十分类似于使用标准hibernate代码生成器的版本(在hibernate: a developer's notebook一书的39-40页),甚至更为简单,因为hibernate synchronizer生成的类针对每项数据库操作都创建并提交了一个新事务,所以在像这样简单的场境中,您不需要编写代码来设置事务。(当然了,要让一组操作作为单个事务运行,有很多种方法。)下面是新版本的代码:
package com.oreilly.hh;import java.sql.time;import java.util.date;import net.sf.hibernate.hibernateexception;import com.oreilly.hh.dao.trackdao;import com.oreilly.hh.dao._rootdao;/** * try creating some data using the hibernate synchronizer approach. */public class createtest2 { public static void main(string[] args) throws hibernateexception { // load the configuration file _rootdao.initialize(); // create some sample data trackdao dao = new trackdao(); track track = new track("russian trance", "vol2/album610/track02.mp3", time.valueof("00:03:30"), new date(), (short)0); dao.save(track); track = new track("video killed the radio star", "vol2/album611/track12.mp3", time.valueof("00:03:49"), new date(), (short)0); dao.save(track); // we don't even need a track variable, of course: dao.save(new track("gravity's angel", "/vol2/album175/track03.mp3", time.valueof("00:06:06"), new date(), (short)0)); }}当我编写这些代码时,可以使用eclipse是一件十分惬意的事情。我已经忘了当我为书籍编写例子时,我多么希望可以使用智能代码完成功能,而且jdt在其他方面也同样能帮上忙。
为了在eclipse中运行这个简单的程序,我们需要设置一个新的run配置。选择run -> run...,把createtest2.java作为当前的活动编辑器文件。单击new,eclipse就会知道我们想要在当前项目中运行这个类,因为我们使用main()方法创建它。它指定的默认名称是createtest2。界面应该如图19所示。单击run,试着创建一些数据。
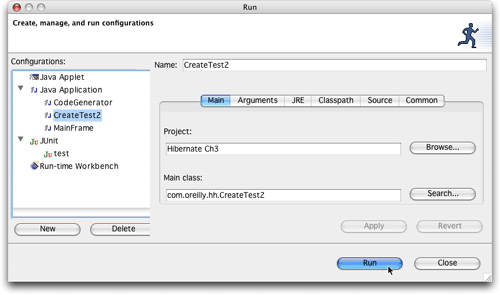
图19.准备好在eclipse中运行我们的创建测试
如果您确实遵照了这些步骤,您就会发现执行时首次尝试将会失败:hibernate抱怨说配置文件没有包含映射引用,而按要求至少要有一个。啊哈!所以,这就是图16底部xmlbuddy出现黄色下划线警告的原因。我们可以很容易地解决这个问题,具体方法是在package explorer视图中的track.hbm.xml映射文档上右击,然后在新的hibernate synchronizer子菜单中选择add mapping reference。这对xmlbuddy来说是正确的做法,可以让运行继续。遗憾的是,运行没有继续多久。下一个错误是无法在jndi中找到jta usertransaction初始上下文。显然我并非惟一遇到这种问题的人,在一个论坛主题中相关的讨论如火如荼,但是还没有人找到解决方案。
因为知道我不需要使用jta,所以我想知道为什么hibernate要尝试找到jta。我打开了hibernate配置文件(图16),然后寻找hibernate synchronizer中的任何可疑之处。无疑有几行是最有嫌疑的:
<property name="hibernate.transaction.factory_class"> net.sf.hibernate.transaction.jtatransactionfactory </property> <property name="jta.usertransaction"> java:comp/usertransaction </property>
我试着把上述内容注释掉并再次运行,这第三次运行成功了。运行没有出现错误,我的数据出现在数据库中。哇!运行可以信赖的antdb目标(developer's notebook一书的第1章中对此有说明)便可以看到所有数据(确实很简单),如图20所示。如果您要这样做,要确保从一个antschema开始创建数据库模式,或者清空来自前面实验中的任何测试数据。
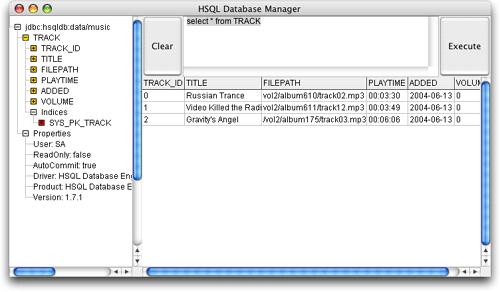
图20.测试程序所创建的数据
注意,可以在eclipse中运行ant目标,具体方法是右击(或控制单击)package explorer中的build.xml文件,选择run an,然后使用eclipse对话框选择目标。酷吧?
图21.在eclipse中运行ant
使用查询取回数据相当简单,尽管这次的代码很接近于常规的使用hibernate生成的普通数据访问类所使用的代码。即使hibernate synchronizer为处理指定查询生成了大量帮助器方法,我还是认为它们中间没有哪一个方法特别有用,因为它们都坚持运行查询后返回结果列表,而不是提供可以直接使用的query对象。这使您无法使用query的方便的类型安全的参数设置方法。因为这一点,我决定一定要让rootdao对象为我提供一个hibernate session,以便使用老式的方法。我认为我可以编辑hibernate synchronizer使用的任何模板来生成我想要的任何方法,如果我要使用它来开发一个项目,我几乎肯定我会这么做。
实际上,进一步考虑的话,因为当获得一个活动的session时,您只能处理query,dao所提供的方法已经达到了最佳效果。如果您想像我在这个例子中所做的那样处理查询,您必须总是自己进行会话管理。可以把会话管理嵌入到“您自己的”那一半dao所提供的业务逻辑中,这就可以同时利用两方面的好处了。这正是hibernate synchronizer提供的拆分类模型如此有用的另一个原因。我将在下面对此进行深入探讨。
不管怎样,下面是我第一次想出的代码,基本上等同于书中48-49页上给出的代码:
package com.oreilly.hh;import java.sql.time;import java.util.listiterator;import net.sf.hibernate.hibernateexception;import net.sf.hibernate.query;import net.sf.hibernate.session;import com.oreilly.hh.dao.trackdao;import com.oreilly.hh.dao._rootdao;/** * use hibernate synchronizer's daos to run a query */public class querytest3 { public static void main(string[] args) throws hibernateexception { // load the configuration file and get a session _rootdao.initialize(); session session = _rootdao.createsession(); try { // print the tracks that will fit in five minutes query query = session.getnamedquery( trackdao.query_com_oreilly_hh_tracks_no_longer_than); query.settime("length", time.valueof("00:05:00")); for (listiterator iter = query.list().listiterator() ; iter.hasnext() ; ) { track atrack = (track)iter.next(); system.out.println("track: /"" + atrack.gettitle() + "/", " + atrack.getplaytime()); } } finally { // no matter what, close the session session.close(); } }}trackdao提供的一个优秀特性是静态常量,通过它,我们可以请求指定查询,消除任何由于字符串输入错误而引起运行时错误的可能性。我喜欢这一点!为这个测试类设置和执行run配置,将会生成预期的输出,如图22所示。
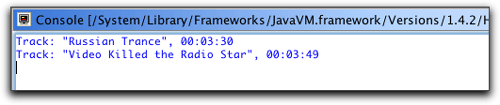
图22. eclipse控制台视图中的查询结果
我前面提到过,运行这个类之后,我意识到,借助于hibernate synchronizer所提供的模型,可以用一种更好的方法来实现它。因为指定查询是与该数据访问对象相关的映射文件的一项特性,所以如果我们将查询放入trackdao对象中(这才是它真正属于的地方),那么这个对象看起来应该是下面这个样子:
package com.oreilly.hh.dao;import java.sql.time;import java.util.list;import net.sf.hibernate.hibernateexception;import net.sf.hibernate.query;import net.sf.hibernate.session;import com.oreilly.hh.base.basetrackdao;/** * this class has been automatically generated by hibernate synchronizer. * for more information or documentation, visit the hibernate synchronizer page * at http://www.binamics.com/hibernatesync or contact joe hudson at [email protected] * * this is the object class that relates to the track table. * any customizations belong here. */public class trackdao extends basetrackdao { // return the tracks that fit within a particular length of time public static list gettracksnolongerthan(time time) throws hibernateexception { session session = _rootdao.createsession(); try { // print the tracks that will fit in five minutes query query = session.getnamedquery( query_com_oreilly_hh_tracks_no_longer_than); query.settime("length", time); return query.list(); } finally { // no matter what, close the session session.close(); } }}这样做更好更清晰,还进一步简化了querytest3中的main()方法:
public static void main(string[] args) throws hibernateexception { // load the configuration file and get a session _rootdao.initialize(); // print the tracks that fit in five minutes list tracks = trackdao.gettracksnolongerthan(time.valueof("00:05:00")); for (listiterator iter = tracks.listiterator() ; iter.hasnext() ; ) { track atrack = (track)iter.next(); system.out.println("track: /"" + atrack.gettitle() + "/", " + atrack.getplaytime()); } }显然,这是一种在使用hibernate synchronizer时处理指定查询的方法。做一次快速测试就可以确认它生成同样的输出,而且它的代码也要好很多。
您是否想使用hibernate synchronizer来生成它自己的数据访问对象类型暂且放下,我们还有最后一项重要特性要探讨。
编辑映射
hibernate synchronizer的一个主要吸引力就在于它为映射文档提供的专业化的编辑器。可以配置这个编辑器,以便只要保存文件就自动重新生成相关数据对象,但是这只是一个锦上添花的功能;即使不打算使用该插件的代码生成器,您也可能希望使用这个编辑器。它为您提供映射文档元素的智能完成功能,以及一个图形化的大纲视图,可以在这个视图中操纵这些元素。
但是,如果从developer's notebook一书中的下载源代码开始,就至少得有一项技巧才可以让编辑器工作。在下载的文件中,映射文档的扩展名为“.hbm.xml”,而只有以“.hbm”结尾的文件才能调用编辑器。理论上,可以在eclipse中配置扩展名映射,以便使具有这两种扩展名的文件都能使用插件的映射文档编辑器,但是我无法使其生效,而且我注意到支持论坛上有人面临着与我相同的问题。所以,至少目前最好的做法就是重命名文件。(如果您坚持使用基于ant的标准代码生成,请确保更新build.xml中的codegen目标以使用新的扩展名。)
在我把track.hbm.xml重命名为track.hbm之后,它在package explorer中的图标就更新为hibernate徽标,而默认的编辑器则变为插件的编辑器,如图23所示。由于某种原因,其他的hibernate synchronizer选项(如图17所示)对于其中任意一种扩展名都是可用的,但是编辑器只对较短的版本可用。
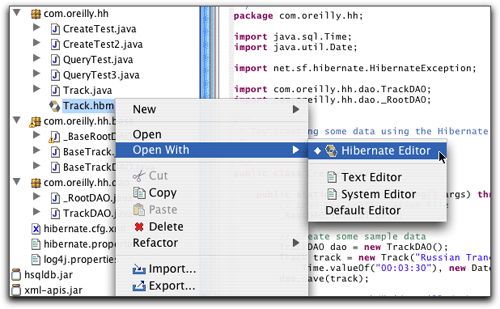
图23. hibernate映射文档(扩展名为“.hbm”)的上下文菜单
编辑器为映射文档中添加的所有元素都提供上下文相关的自动完成支持。图24显示了一些例子,但是屏幕截图无法真正捕捉到该特性的深度和有效性。我强烈建议您安装插件并使用它。您很快就会看到它在处理映射文档方面是多么有用。
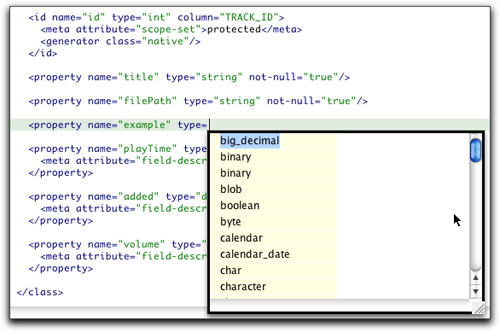

图24和25.映射文档编辑器中的完成辅助功能
如图26所示,大纲视图提供了一个关于类层次结构、被映射的元素、指定查询以及映射文档中的各种元素的图形化视图,还提供一个菜单,其中有一些向导可以帮助创建新的属性。
| |
图26和27. 映射编辑器的大纲视图和“add property”向导
编辑器中的上下文菜单还提供一个format source code选项,可以使用它来整理和重新构造文档。这个编辑器中已经有了很多灵巧和有用的特性,看它们如何发展也是一件有趣的事情。惟一使我感到不满的是(并不是什么大问题),当完成xml属性时,这个编辑器用来帮助管理引号的方法与jdt在java代码中使用的方法完全不同。在它们之间来回切换会把人弄迷糊。(您需要一些时间适应jdt的工作方式,但是一旦您开始信任它,它就会变得魔力无穷。)
生成数据库模式
尽管我的第一印象是所有内容都来自映射文档,但是hibernate synchronizer目前不支持从映射文档创建或更新数据库模式。支持论坛上已经提出了相关的请求,所以如果将来看到这些特性,我肯定不会吃惊,因为提供这类支持并不很困难。目前来说,如果要从映射文档开发数据库,就必须使用像hibernate: a developer's notebook书中这种ant驱动之类的方法。此外,下面描述的hibernator插件支持在eclipse中进行模式更新。我可能要研究一下是否可以同时安装这两种插件。
我希望本文能够让您清楚地了解该插件所提供的功能。无论如何,我没有涵盖它的所有功能,所以如果您有兴趣,可以去下载它然后自己进行探索。
权衡
毫无疑问,可以使用hibernate synchronizer来完成一些灵巧的工作。是否要在我自己的hibernate项目中使用它呢?这样做有优点也有缺点,很可能直到实际采用hibernate来代替我们正在使用的自己开发的(且过分简单的)轻量级o/r工具时,我才会做出决定。这是一次意义相当重大的改动,而我们把这次改动推迟到了由于其他原因进行架构变换的时候。下面是对我的决定起着重要作用的一些因素。
正如我们在安装小节中所谈到的那样,在许可证方面还存在着一点问题。插件的论坛中有此方面的讨论。当前的许可证基于对gnu gpl的定制修改,这次修改删除了所有源代码共享方面的条款,但是试图保留“copyleft”保护的其他方面。关于这样做的合法性仍然存在一些问题,而作者正在寻求另一种解决办法。很清楚,目的是要保护插件,而不是阻止其他任何项目使用该插件生成代码,但是有必要仔细阅读当前的许可证,看一看其目的是否已经达到,或者您是否仍然冒着很大的风险。
同一讨论表明,作者原来是以开源的形式发布插件的,但是又临时收回了这一决定,因为他觉得它还不够完美以用作一个优秀的范例。接着,他与一些莽撞的人通过一些非常不愉快的邮件,这使他不愿再共享源代码。当然,他有权决定是否与我们共享源代码。该插件对于整个世界来说是一份大礼,而作者并不欠我们什么。但是我希望他能与其他用户进行足够的正面交流,这样就能坚定他原来共享源代码的想法。我真的认为能够看到我使用的工具的源代码是一件很有价值的事情,不仅因为这是一个很好的学习机会,还因为这意味着,如果需要的话我可以立刻修复一些小问题。作者在解决用户的问题方面始终很热心,响应也很快,但是一个人无法维持一个社区,因为我们都有繁忙、筋疲力尽和心烦意乱的时候。
hibernate synchronizer使用它自己的模板和机制来生成数据访问类,这既有优点也有缺点。优点是可以获得比hibernate的“标准”代码生成工具更多的功能。可以使用数据对象的一个自动生成的子类,并在该数据对象中嵌入业务逻辑,而无需担心重新生成访问代码时这些业务逻辑会被改写,这也是一个不错的特性。插件生成的使很多简单的场景更简单的类还提供了其他的优点。
另一方面,这还意味着,当hibernate平台增加一些新的特性或者做了改动之后,hibernate synchronizer生成的代码就有些滞后于hibernate了。在对hibernate不常使用的模式的支持方面,插件代码也存在bug:它的用户群很小,一个人就可以让它保持更新。您可以在讨论论坛上找到这种现象的证据。
和很多事情一样,潜在的优点是否超过风险要由您来决定。即使不使用代码生成器,您也会发现映射编辑器非常有用。如果您只想使用编辑器的自动完成和辅助功能,可以关掉自动同步选项。
如果您使用过该插件,并且发现它很有用,我建议您联系其作者,表达您的谢意,并考虑捐出一些资金来帮助支持它的未来发展。
其他插件
迄今为止,我还找到了另外两个也提供eclipse中的hibernate支持的插件。(如果您还知道有其他的插件,或者将来遇到了这样的插件,我很愿意知道它们。)或许将来我还会撰写有关这些插件的文章。
hiberclipse
hiberclipse插件看起来也是一种非常有用的工具。它似乎适用于数据库驱动的工作流,在这个工作流中,已经有了一个数据库模式,而您想构建一个hibernate映射文件和java类来使用该模式。这是一种很常见的场景,如果您发现自己面临着这样的难题,我强烈推荐您使用这个插件。它提供了一项非常酷的特性:在eclipse中为所使用的数据库提供图形化的“关系视图”。(我应该指出,如果您想从一个现有的数据库模式开始,hibernate synchronizer也会有所帮助的。它的new mapping file wizard可以连接到您的数据库,并基于所发现的内容构建映射文件。)
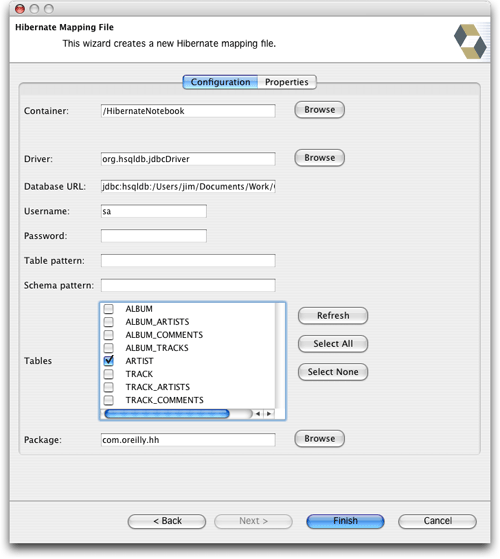
图28. hibernate synchronizer的映射向导
hibernator
最后一个,hibernator似乎倾向于另一个方向,即,从java代码开始生成简单的hibernate映射文档,然后让您从映射文档构建(或更新)数据库模式。它还提供在eclipse中运行数据库查询的能力。在这3种插件中,它所处的开发阶段似乎最早,但是已经值得关注了,特别是因为它的开发者是hibernate开发团队的成员。
新闻热点






疑难解答