去年的年末写了篇关于如何简单使用jprobe发现和定位j2ee应用中的性能瓶颈,jprobe是quest公司的一个针对开发过程中应用程序的性能优化工具,但这不能满足上面提出的对于系统全面的性能监控和管理要求。针对这种要求,结合目前市场上的性能分析,调优和管理工具,比如ibm tivoli、hp openview等,这类工具的主要功能是对整个系统进行管理;另外一些,比如wily,veritas i3等,这类工具也具备一定的管理和对整个系统进行监控的能力,同时对某一技术层次拥有非常出色的调优和监控能力;其他的工具如quest jprobe就如上面介绍的一样主要是针对开发过程中程序级别的性能优化。
本文将结合wily和weblogic,以目前流行的应用架构来描述如何使用wily这个工具对分布式系统进行全方位的性能监控和管理。以往针对j2ee的调优很多都是依靠开发人员或者是厂商技术人员根据经验来对问题进行定位和调优,不能做到对系统全方位的了解。借助于wily之后,可以从客户体验出发到具体的一个sql语句进行深入细致的分析,来完成对系统的性能的监控和管理。
wily公司成立于1998年,其第一个投资方是bea,对weblogic有很好的支持。
wily的核心产品是interscope,包括introscopeenterprise manager, introscope agent, introscopeworkstation.通过introscope可以明确的显示出在j2ee应用程序的什么为止出现了什么问题,比如在应用性能下降时,查明j2ee应用系统的什么位置导致问题是一个非常麻烦的工作,借助introscope将会变的非常简单。
wily introscope的系统架构如下图
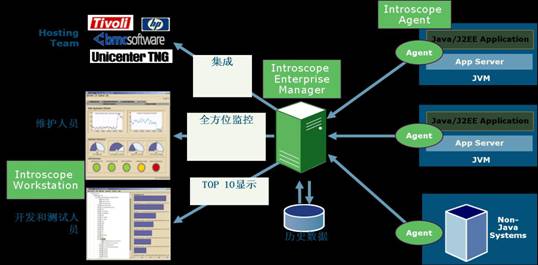
wily introscope特点
通过introscope的结构图可以看到,核心部分为introscope的enterprise manager,通过部署在应用中的各种不同agent来收集系统运行中的各项性能指标数据,汇总到em进行分析,并能利用对历史数据的分析对系统未来的性能表现进行评估;分析的结构可以具体的定位到什么位置除了什么问题,并将问题进行分类反馈到相应的系统维护人员,比如网络,系统硬件维护人员,或者是开发和测试人员,对出现的问题进行调整。
wily与weblogic的集成
wily有专门针对weblogic的性能监控模板,为powerpack,有效监控最为关键的weblogic资源,包括线程池,jdbc连接池等,并且第一个实现了对portal(bea portal,ibm portal等)的性能管理和监控。通过powerpack可以看到部署在weblogic上的应用的各种性能指标,以weblogic自带的medical records例子来说,如下图:
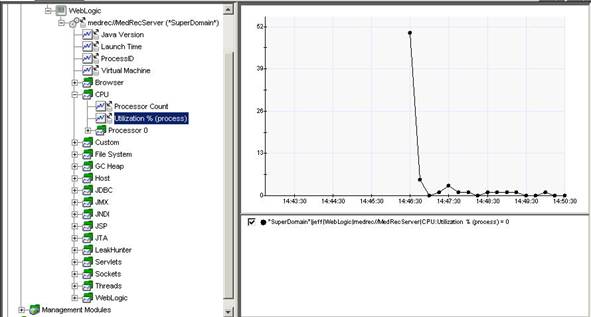
可以看到包括系统资源在内的各种性能指标,和j2ee应用中各种组件的性能指标,通过配置可以跟踪到某一个具体的jsp或者是servlet的性能情况,并且可以配置在某一性能指标达到指定的阀值后进行报警操作。
通过提供的transaction trace功能来分析超过指定时间的某一具体transaction的内部情况。
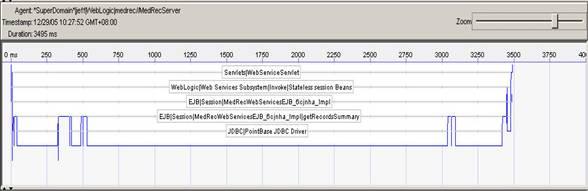
通过树状结构可以看到事务内部的调用情况并且快速的定位到某一有问题的操作,通过该技术可实时跟踪生产系统中的某个具体事务问题,提供事务的执行路径和组件响应时间的详细信息,如上图。并能及时修正事务的性能问题。
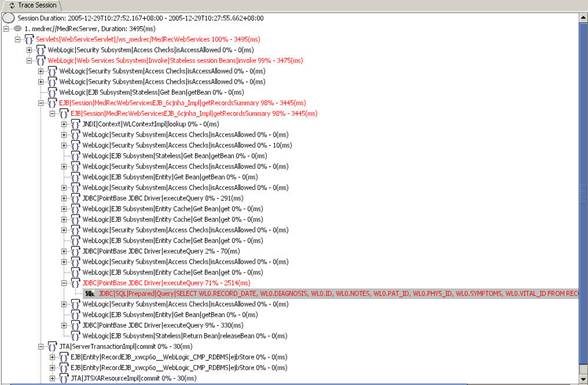
除此之外该powerpack包还提供了针对weblogic系统运行的一个性能查看控制台,通过该控制台可以直观的监控系统的那一部分出了问题,并且通过控制台可以方便的定制所关心的各种性能指标,定制后能通过浏览器的方式查看整个系统的运行情况。
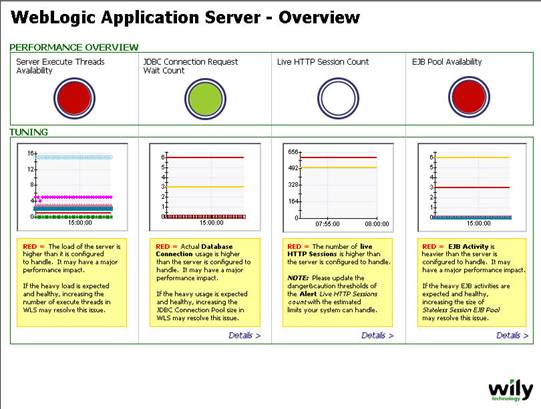
配置启动步骤
安装步骤,只需解压缩powerpack包到bea的安装目录内即可(其他目录也可以,在配置的时候进行指定即可);
set java_options = -xbootclasspath/p:c:/bea/weblogic81/wily/connectors/autoprobeconnector.jar; c:/bea/weblogic81/wily/agent.jar -dcom.wily.introscope.agentprofile= c:/bea/weblogic81/wily/introscopeagent.profile
配置启动完成后,通过设置相应的监控性能项,在控制台中可以通过各种不同类型的图表来观察系统的运行状态。
如何发现系统性能问题?
由于例子程序在运行中并没有很大的压力,通过控制台能看到系统的负载情况,为了模拟出和生产系统中相同的运行情况,这里借助于segue公司的silkperformer来对weblogic的例子程序进行加压(silkperformer也能监控到系统的各项性能指标,这里把采集的数据与wily进行大概的比较),通过在不同负载下收集到的性能数据,来分析系统中可能存在的性能问题。
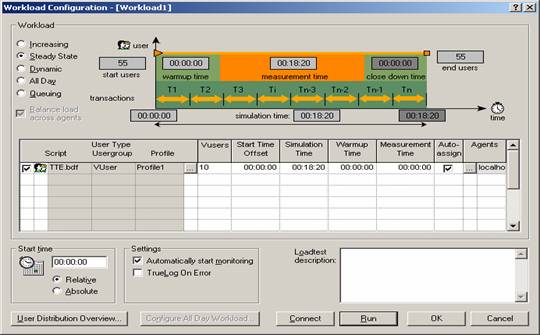
模拟运行步骤
| 并发用户数 | 测试时间 |
|---|---|
| 10 | 10分钟 |
| 20 | 10分钟 |
压力模式设置
可能出现的性能问题和观察到的性能指标特征描述
| 性能问题 | 性能指标特征 | 问题描述 |
|---|---|---|
| 系统性能随负载增加逐渐下降 | weblogic配置的线程数随负载的增加出现匮乏。 | 资源瓶颈 |
| 可预见的死锁,系统性能随运行时间的增加逐渐下降 | jdbc连接等资源无法回收,从性能指标图上可以看出可使用的该资源为0,并有大量等待。 | 资源泄漏等 |
10个并发系统的线程使用情况,通过wily获取
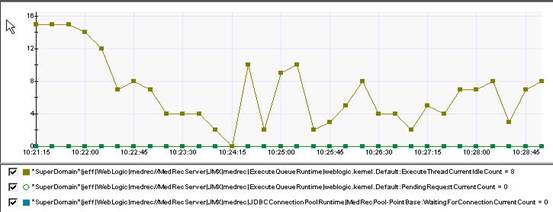
pendingrequestcurrentcount=0,waitingconnectioncurrentcount=0,表明没有等待的request,系统响应很快。
10个并发系统的jdbc使用情况,通过wily获取
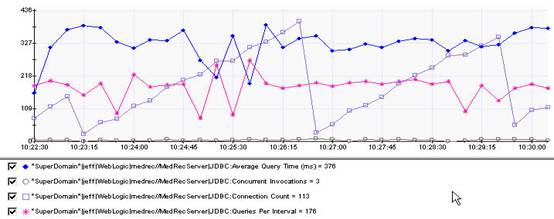
concurrent invocations 最大值为8,并且平均查询的时间曲线表现也比较平稳。
20个并发系统的线程使用情况,通过wily获取
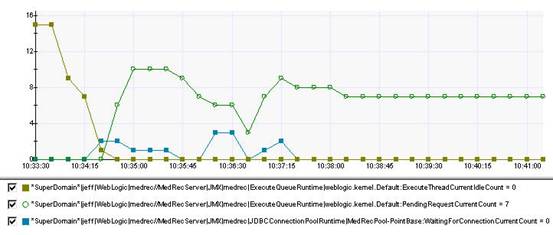
executethreadcurrentidlecount=0,pendingrequestcurrentcount开始有变化,对比10个并发用户的线程使用情况,很明显可以看出在20个并发的压力下,系统的线程资源开始不足。
20个并发系统的jdbc使用情况,通过wily获取
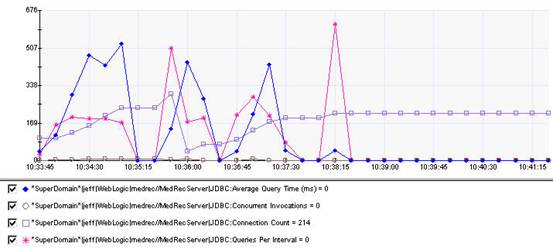
平均查询时间有比较大的起伏,运行一段时间后可以看到该值为0,connection count的值也保持不变,基本不响应获取连接请求。这个时候访问系统页面,无法进入。
结论
以上例子只是通过简单的性能指标来观察系统运行状态,对于一个复杂的系统还需要更多的性能指标数据来分析系统是否运行良好,比如可以检查系统是否存在内存泄漏,网络速度是否够快等。一般的系统调优很多都是在出了问题后,凭经验对照系统的性能表现来进行,很多时候可能会花费很多的时间才能定位的真正的性能瓶颈,借助工具之后,可以直观的对整个系统的各个部分进行监控,一旦出现问题,可以及时的报警并能迅速定位问题解决问题。
新闻热点






疑难解答













