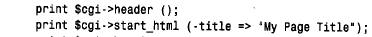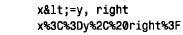,欢迎访问网页设计爱好者web开发。 迄今为止,我们编写的dbi 脚本用于命令行环境中的命令解释程序,但dbi 在其他环境下也是有用的,例如在基于web 的应用程序的开发中。当编写能从web 浏览器调用的dbi脚本时,就打开了新鲜而有趣的与数据库交互的性能。 例如,如果以表格的形式显示数据,则可以很容易地把每个列标题转换为可以选择的连接,以便将该列的数据重新排序。它允许单击一次就可以以不同的方式查看数据,而又不必键入任何查询。或者可以提供一种用户可以为数据库搜索而键入的标准格式,然后,显示含 有搜索结果的页面。像这种简单的能力能够特别地改变为访问数据库内容而提供的交互性的水平。除此之外,web 浏览器的显示能力比在终端窗口获得的能力要明显地更好一些,所以,输出也经常看起来更漂亮。 在这部分,我们将创建下面的基于web 的脚本: samp_db 数据库中表的通用浏览器。这与我们想对这个数据库完成的任何特定的任务无关,但是它举例说明了若干web 程序设计概念,并提供了一种查看这些表所含有的信息的方便方式。 允许我们查看任何给定的测验或测试分数的分数浏览器。它作为回顾评分事件结果的快速方式是很方便的,并且当我们需要创建测试的等级曲线时,它是有用的,所以我们可以以字母等级来标记试卷。 寻找分享共同兴趣的历史同盟成员的脚本。通过允许用户输入搜索短语来完成它,然后在member 表的interests 域来搜索短语。我们已经编写了一个行命令脚本来做这些,但是,基于web 的版本提供了有指导意义的参考观点,允许对同一任务比较两种方法。 我们将使用cgi.pm perl 模块来编写这些脚本,这个模块是将dbi 脚本连接到web 上最容易的方法(有关获得cgi.pm 模块的说明,请参阅附录a)。之所以称为c g i . p m,是因为它有助于编写使用公共网关协议的脚本,这个协议定义了web 服务器如何与其他程序通信。cgi.pm 处理涉及了许多通用内务处理的任务细节,如收集通过web 服务器传递到脚本的作为输出的参数值。cgi.pm 也提供了生成html 输出的便利方法,与编写自己原始的h t m l 标记相比,它减少了编写难看的html 的机会。 在本章中,您将学到足够有关cgi.pm 的知识来编写自己的web 应用程序,但是,当然不是它所包括的所有性能。要想学习有关这个模块的更多知识,请参阅lincoln stein (john wiley 1998 出版) 撰写的《o fficial guide to programming with cgi.pm》,或在以下网址查阅联机文档: http://stein.cshl.org/www/software/cgi/
设置cgi 脚本的apache
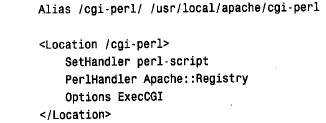
除了dbi 和cgi.pm 之外,编写基于web 的脚本还需要有一个以上的组件:web 服务器。这里的说明适合apache 服务器使用脚本,但是,如果愿意,稍微改编一点这些说明,就可以使用不同的服务器。 一般来说,apache 装置的各个部分位于/usr/local/apache 目录。对我们的目的来讲,这个目录中最重要的子目录为h t d o c s(html 文档树)、cgi-bin (可执行的脚本和we b服务器调用的程序),和c o n f(配置文件)。这些目录也可能放在系统中的其他地方。如果是这样,则要对下面的注意事项做适当的调整。 应该验证cgi-bin 目录不在apache 文档树的内部,以便它内部的这些脚本不能作为无格式文本来请求。这是个安全的防范方法。您也不愿意让怀有恶意的客户机程序检查您的脚本,通过提取这些脚本的文本并研究它们来作为安全的突破口。 要想安装以apache 方式使用的cgi 脚本,则将它放在cgi-bin 目录下,然后将这个脚本的所有权更改为运行apache 的用户,并将它的模式更改为对该用户为可执行的和只读的模式。例如,如果apache 以名称为www 的用户方式运行,则使用下面的命令: % chown www script_name % chmod 500 script_name 可能需要用www 或root 运行这些命令。如果不允许在cgi-bin 目录下安装脚本,则可以请求系统管理员代表您来这样做。 安装这个脚本之后,通过向web 服务器发送适当的u r l,可以请求浏览器上的这个脚本。典型的url 是这样的: http://your.host.name/cgi-bin/script_name 从web 浏览器请求脚本会导致web 服务器执行它。返回脚本的输出,结果作为we b 页面出现在浏览器中。 如果为寻求更好的性能而使用具有mod_perl 的cgi 脚本,则可以这样做: 1) 确保至少有以下版本的必需软件: perl 5.004、cgi.pm 2.36和mod_perl 1.07。 2) 确保将mod_perl 编译为apache 可执行的文件。 3) 建立一个存储脚本的目录。我使用了/usr/local/apache/cgi-perl。cgi-bin 不应该位于apache文档树的内部,出于同样的安全原因, cgi-perl目录也不应该在那里。 4) 告知apache,与位于cgi-perl 目录中的脚本mod_perl 相关联: 如果正在使用apache 的当前版本,这个版本使用单个的配置文件,则将所有这些指示放在httpd.conf 中。如果apache 的版本使用三个旧文件的方法来配置信息,则将a l i a s指示放入srm.conf 中,将location 行放入access.conf 中。对于cgi-perl 目录,不要启用m o d _ per l、perlsendheader 或perlsetupenv 指示。这些由cgi.pm 自动地处理,启用它们可能导致处理冲突。 mod_perl 脚本的url 与标准的cgi 脚本的url 相类似。唯一的不同之处在于指定cgi - perl 而不是cgi - bin。 http://your.host.name/cgi-perl/script_name 有关的详细信息,请参阅下面地址的apache web 站点的mod_perl 区域: http://perl.apache.org/
cgi.pm 的简要介绍
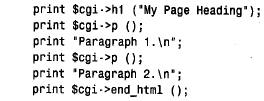
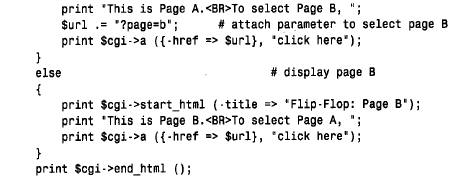
为了编写使用cgi.pm 模块的perl 脚本,将use 行放在这个脚本的开头附近,然后创建让您访问cgi.pm 方法和变量的cgi对象: use cgi; my($cgi)=new cgi; 我们的cgi 脚本使用了cgi.pm 的性能,它通过使用$cgi 变量调用方法来实现。例如,为了生成级别1标题,我们将这样使用h1( ) 方法: print $cgi->h1("my heading"); cgi.pm 也支持允许以函数调用它的方法的使用风格,而不用前导的‘ $ c g i - >’。在这里,我没有使用这个语法,是因为‘ $ c g i - >’符号更类似于使用dbi 的方式,还因为它防止c g i . p m函数名与可以定义的任何函数名产生冲突。 1. 检查输入参数,并编写输出 cgi.pm 所做的事情之一就是照看所有丑陋的细节,这些细节涉及到收集由we b服务器向脚本提供的输入信息。为了获得那些信息,所需做的就是调用param( ) 方法。可以如下获得所有可用的参数名: my (@param)=$cgi->param(); 为了检索特定参数的值,只命名感兴趣的参数: cgi.pm还提供生成传送给客户机浏览器的输出方法。考虑下面的html文档: 这个代码使用$cgi来产生等价的文档: 使用cgi.pm 生成输出,而不是编写自己原始的h t m l,这样做的一些优点是,可以按逻辑单元考虑,而不是按单独的组成标识来考虑,而且html 不太可能含有错误(我说“不太可能”的原因是cgi.pm 不禁止做古怪的事情,如含有一列内部的标题)。除此之外,对于 编写的非标记文本,cgi.pm 提供自动的字符转义,如html 中指定的‘<’和‘>’。 如果愿意,cgi.pm 生成输出方法的使用并不排斥编写自己原始的h t m l。可以将这两种方法混合起来,组合调用具有生成文字标识的显示语句的cgi.pm 方法。 2. 转义的html 和url 文本 如果经cgi.pm 方法,如start_html( ) 或h1( ),编写非标记的文本,则自动地转义文本中的特定字符。例如,如果使用下面的语句生成标题,则标题文本中的‘ &’字符将由c g i . p m 转换为‘& a m p ;’: print $cgi->start_html (-title=>"a,b&c"); 如果不使用cgi.pm 生成输出的方法编写非标记的文本,则可能应该先让它经过escapehtml( ) ,以便确保可以正确地转义任何指定的字符。当构造可能含有特定字符的url 时也是这样,尽管在那种情况下应该使用escape( ) 方法来代替它。使用适当的编码方法是很重要的,因为每种方法都将不同的字符集作为特殊的字符来对待,并使用彼此不同的格式来对待特殊的字符编码。考虑下面简短的perl 脚本: 如果运行这个脚本,则它生成下面的输出,从这里可以看到html 文本的编码不同于url 的编码: 3. 编写多目的页面 编写基于web 的脚本来生成h t m l,而不是编写静态的html 文档的主要原因之一是,根据调用方式,脚本可以产生不同类型的页面。我们将要编写的所有cgi 脚本都有这种特性。每一个都像下面这样操作: 1) 当从浏览器第一次请求这个脚本时,它生成一个初始页面,允许选择想要的信息类型。 2) 当做了选择以后,重新调用这个脚本,但是,这次它在第二页检索,并显示请求的特定信息。 这里的主要问题是想从第一页的选择中确定第二页的内容,但是,通常web 页面是彼此独立的,除非安排某些特定排列的次序。这个窍门是让脚本生成页面,这个页面给参数设置一个值,告诉这个脚本的下一个调用想要的内容。当第一次调用这个脚本时,这个参数没有 值;告诉这个脚本给出它的初始页面。当指出想看的信息内容时,这个页面再一次调用这个脚本,但是,将参数设为指示这个脚本做什么的一个值。 将说明从页面传送回脚本有不同的方式。一种方式是提供一种用户填写的表格。当用户提交这张表格时,将它的内容提交给web 服务器。服务器将信息传递给脚本,这个脚本通过调用param( ) 方法,能够找出提交的内容。这就是我们对第三个cgi 脚本所做的事情(允许用户输入搜索历史同盟目录的关键字)。 对脚本指定说明的另外一种方法是,当请求脚本时,将信息作为发送到we b服务器的u r l的一部分来传递。这就是我们对于samp_db 表浏览器和分数浏览器脚本要做的事情。这种工作方式是脚本生成含有超链接的页面。选择一个连接,再次调用这个脚本,但是,这次 指定参数值,这个参数值指示这个脚本做什么。实际上,这个脚本以不同的方式调用它本身,来提供不同类型的结果,这取决于用户所选择的连接。 脚本可以允许通过向浏览器向它自己的url 传送一个含有超链接的页面来调用它本身。例如,脚本my_script 可以编写含有如下这样连接的页面: <a href="/cgi-bin/my_script">click me!</a> 当用户敲入文本“ click me!”时,用户浏览器就请求将my_script 发送回web 服务器。当然,所有这些会导致脚本再次发送出同一个页面,因为它不支持其他信息。然而,如果将一个参数附加到url 上,则当用户选择这个连接时,将这个参数送回web 浏览器。服务器 调用这个脚本,这个脚本可以调用param ( ) 来侦测设置的参数,并根据它的值采取行动。 为了把参数附到url 的末尾,加一个“?”字符放到名称/值的前面。为了附上多个参数,用字符“&”分隔。例如: /cgi-bin/my_script?name=value /cgi-bin/my_script?name=value&name2=value2 为了构造带有附加参数的自引用的u r l,c g i脚本应该通过调用script_name ( ) 方法获得自己的u r l来开始,然后像按照如下方法添加参数: 在构造u r l之后,通过使用cgi.pm 的a( ) 方法,可以生成一个包括它的超链接<a> 标记: print $cgi->a ({.href=>$url},"click me!); 通过检查一个简短的cgi 脚本来查看如何工作会更容易。第一次调用时,下面的脚本f l i p _ f l o p,给出了一个含有单个超链接的称为页面a 的页面。选择这个连接再次调用这个脚本,但是设置page 参数,告诉它显示页面b。页面b也包括对脚本的连接,但是page 参数没有值。因此,在页面b中选择这个连接导致重新显示原始页面。随后的脚本调用将页面在脚本a和脚本b之间来回切换: 如果另一个客户机程序出现并请求f l i p _ f l o p,就给出初始页面,因为不同客户机的浏览器并不互相影响。 实际上,$url 的值被前面的样例设置成漂亮的风格。在把它们放在url 之后以免包括特殊字符时,使用escape( ) 方法对参数名和值进行编码是比较好的。这里有一个较好的方法来用附加的参数值来构造u r l:
从web 脚本连接到mysql服务器
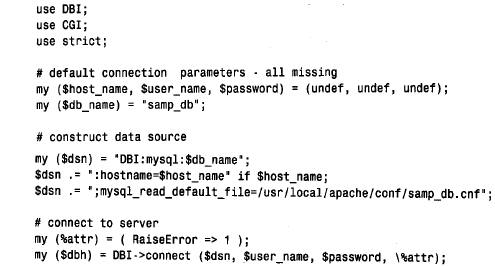
我们在前一节“运行dbi”中开发的命令行脚本,为建立到mysql服务器的连接共享了一个通用的前文。cgi 脚本也共享了一些代码,但是有一些不同: 这个前文与命令行脚本使用的前文的不同之处在于以下几个方面: 第一部分现在含有一条use cgi 语句。 不再分析命令行的参数。 代码仍然在可选文件中寻找连接参数,但是,在用户执行脚本的主目录中不使用.my.cnf 文件(也就web 服务器用户的主目录)。web 服务器可能运行访问其他数据库的脚本,没有理由假设所有脚本会使用同一连接参数。相反,我们寻找不同位置存放的可选文件( / us r / l o c a l / a p a c h e / c o n f / samp_db . c n f)。如果想使用不同的文件,应该修改可选文件的路径名。 通过web 服务器调用的脚本作为web 服务器用户,而不是作为您来运行。这就提出了一些安全问题,因为在web 服务器接管之后您就不再控制了。应该把可选文件的所有权交给运行web 服务器的用户(可能是www 或者nobody 或者一些类似的用户),并将模式设置为4 0 0 或6 0 0,以便其他用户不能读取。不幸的是,可以安装这个web 服务器的脚本来执行的任何人仍然能够读取这个文件。他们要做的所有事情就是编写一个脚本,显式地打开可选文件,并在we b页面上显示它的内容。因为他们的脚本作为we b服务器用户来运行,所以它将有足够的权利来读取这个文件。 由于这个原因,创建一个对samp_db 数据库具有只读( s e l e c t)权限的mysql用户,然后在samp_db.cnf 文件中列出这个用户的名称和口令,而不是您自己的名称和口令,这种行为是很谨慎的。作为有权修改数据库的表的用户,这种方式不会冒险允许脚本连接到数据库。第11章“常规的mysql管理”,讨论了如何创建具有严格权限的mysql用户账户。 另一种选择,可以在apache 的suexec 机制下安排执行脚本。这就允许作为特殊权限的用户执行脚本,然后编写脚本,从只对那个用户为只读的可选文件中获得连接参数。例如,需要编写访问数据库的脚本,就可以这样做。 还有另外一种方法就是编写脚本,从客户机用户请求用户姓名和口令,并使用这些值建立到mysql服务器的连接。这种方法对于为管理目的而创建脚本比对于为一般使用提供脚本更适合。无论如何,应该警惕用户名和口令请求的一些方法受到一些人的攻击,这些人可 能在您和服务器之间的网络上安放窃听器。 因为可以从前面的段落中搜集,所以web 脚本的安全性是个棘手的问题。很明显,应该多读一些有关安全的主题,因为它是一个大的主题,所以在这里我不能真正做得很全面。查看apache 手册中有关安全性的资料是一种好的方法。您也可以查找www 安全性的faq 说 明,例如可以使用下面的网址: http://www.w3.org/security/faq/
samp_db数据库浏览器
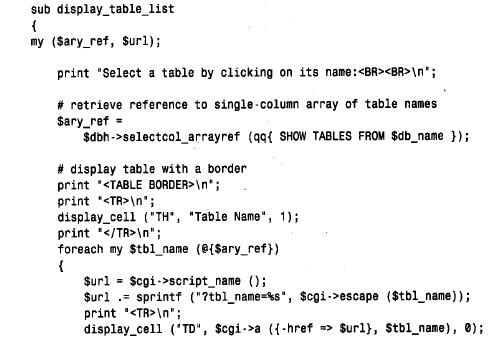
对于第一个基于web 的应用程序,我们将开发一个简单的脚本— samp_db — 允许查看samp_db 数据库中存在的表,并从web 浏览器中交互式地检查这些表中的内容。samp_db的工作方式如下: 当首次从浏览器中请求samp_db 时,它连接到mysql服务器,在samp_db 数据库中检索一列表,并向浏览器发送一个页面,在这个页面中出现的每个表都作为可选择的连接。当选择这个页面中的一个表名时,榔骶拖騑eb 服务器发送一个请求,请求samp_browse 显示那个表的内容。 当调用samp_browse 时,如果它收到从web 服务器发来的一个表名,则它就检索这个表的内容,并将信息显示在web 浏览器上。数据每列的标题就是表中列的名称。标题作为连接出现;如果选择它们中的一个,则浏览器就向web 服务器发送一个请求,显示同样的表,但按选择的列排序。 注意,这里有个警告: samp_db 表中的这些表相对较小,因此向浏览器发送表的全部内容并不是大问题。如果编辑samp_db,显示包含大型表的不同数据库中的表,则应该考虑向行检索语句中增加一个l i m i t子句。 在samp_browse 脚本的主体中,我们创建了cgi 对象,并取消了web 页面的初始部分。然后检查是否按我们的假设,根据tbl_name 参数值显示了一些特定的表: 很容易找出参数的值,因为cgi.pm 做了找出web 服务器传递给这个脚本信息的全部工作。我们只需调用具有我们感兴趣的参数名的param( ),在s a m p _ b r o w s e的主体中,这个参数为tbl_name。如果它没有定义或者为空,则它就是这个脚本的初始调用,我们显示这个表列。否则,就显示由tbl_name 参数命名的表的内容,由sort_column 参数命名的列值排序。显示适当的信息之后,我们调用end_html( ) 消除结束的html 标志。 display_table_list( ) 函数生成初始页面。display_table_list( ) 检索这个表列并写出在每个单元中都含有一个数据库表名的单列的h t m l表: display_table_list( ) 生成的页面含有如下连接: 当调用samp_browse 时,如果tbl_name 参数有值,则这个脚本将这个值传递给display_table( ),连同按名称排序后的列名。如果没有命名的列,则我们按第一列排序(我们可以通过位置引用列,因而很容易地使用order by 1子句来完成): 表显示了与重新显示该表的连接相关的列标题的页面;这些连接包括sort _ c o l um n参数,它显式地指定排序的列。例如,对于显示event 表内容的页面,列标题连接看起来如下所示: display_table_list( ) 和display_table( ) 都使用了display_cell( ),h t m l表中作为单元显示值的实用程序函数。这个函数使用了一个小窍门,就是将空值转换为不可分的空格(‘& n b s p ;’),因为在带有边框的表中,空单元不会正确地显示边框。将不可分的空格放入这个单元中解决了这个问题。display_cell( ) 还具有控制是否将单元值编码的第三个参数。这是必需的,因为调用display_cell( ),显示了一些已经编码的单元值,如含有url 信息的列标题: 如果想编写更通用的脚本,可以将samp_browse 更改为浏览多个数据库。例如,在脚本开始时,可以显示服务器上的一列数据库,而不是一个特定数据库中的一列表。然后,选出一个数据库,获得它的一列表,再从那里继续。
学分保存方案分数浏览器
每当我们输入测试的分数时,都需要生成一个有序的分数列表,以便确定等级曲线,并分配字母等级。请注意,对于这个列表我们将做的所有事情就是显示它,以便能确定每个字母等级终止的位置。然后在返回给学生之前,在测试卷上标出等级分数。我们不在数据库中 继续记录这个字母等级,因为在等级周期末尾的等级取决于数字分数,而不是字母等级。再请注意,严格地说,在创建检索分数的方法之前,就应该有一个输入分数的方法。我将输入分数的脚本一直保存到下一章。在这期间,在数据库中,我们已经从早期的等级周期部分中 得到了几组分数。即使没有方便的分数输入方法,我们也可以使用具有那些分数的脚本。 我们浏览分数的脚本score_browse 与samp_browse 有些类似,但是希望查看给定测试或测验的分数这种更特定的目标。初始页面给出一列可以从中选择的可能的等级事件,允许用户选择它们中的任何一个,来查看与事件相关的分数。给定事件的分数按照高分在前的顺序按分数排序,因此可以显示出结果,并用它确定等级曲线。 score _ b r o w s e只需要检查一个参数e v e n t _ i d,查看是否指定了特定事件。如果不是,则score_browse 就显示event 表中的行,以便用户可以选择其中的一个。否则,就显示与所选事件相关的分数: 使用请求表列标题的列名,函数display_events( ) 从event 表中抽取信息,并以表格形式显示它。在每行的内部,显示event_id 值,作为可以选择的连接,以触发检索相应事件分数的查询。每个事件的url 都只是到具有附加参数score _ b r o w s e的路径,这个参数指定事件号码: /cgi-bin/score_browse?event_id=number display_events( ) 函数编写如下: 当用户选择事件时,浏览器发送一个具有附加事件id 值的score_browse 请求。score_browse 找到event_id 参数集,并调用display_scores( ) 列出所有特定事件的分数。这个页面也显示了文本“ show event list”,作为返回初始页面的连接,以便用户能很容易地返回事件列表页面。这个连接的url 引用了score_browse 脚本,但不指定event_id 参数的任何值。display_scores( )子程序如下所示: display_scores( ) 运行的查询与我们以前在第1章的1. 4 . 8节中的“从多个表中检索信息”小节中开发的说明如何编写连接的查询极为类似。在那一章中,我们请求给定日期的分数,因为日期比事件的id值更有意义。相反,当我们使用score_browse 时,知道了精确的事件id。那不是因为我们按照事件id 考虑(我们没有),而是因为脚本给了我们一列可从中选择的事件id。可以看到这种类型的接口减少了了解特定细节的需要。我们不必了解事件的id;只需要识别出想要的事件。