在开发过程中,收到这样一个问题反馈,在网站上传 100 MB 以上的文件经常失败,重试也要等老半天,这就难为需要上传大规格文件的用户了。那么应该怎么做才能快速上传,就算失败了再次发送也能从上次中断的地方继续上传呢?下文为你揭晓答案~
温馨提示:配合 Demo 源码一起阅读效果更佳
整体思路
第一步是结合项目背景,调研比较优化的解决方案。
文件上传失败是老生常谈的问题,常用方案是将一个大文件切片成多个小文件,并行请求接口进行上传,所有请求得到响应后,在服务器端合并所有的分片文件。当分片上传失败,可以在重新上传时进行判断,只上传上次失败的部分,减少用户的等待时间,缓解服务器压力。这就是分片上传文件。
大文件上传
那么如何实现大文件分片上传呢?
流程图如下:
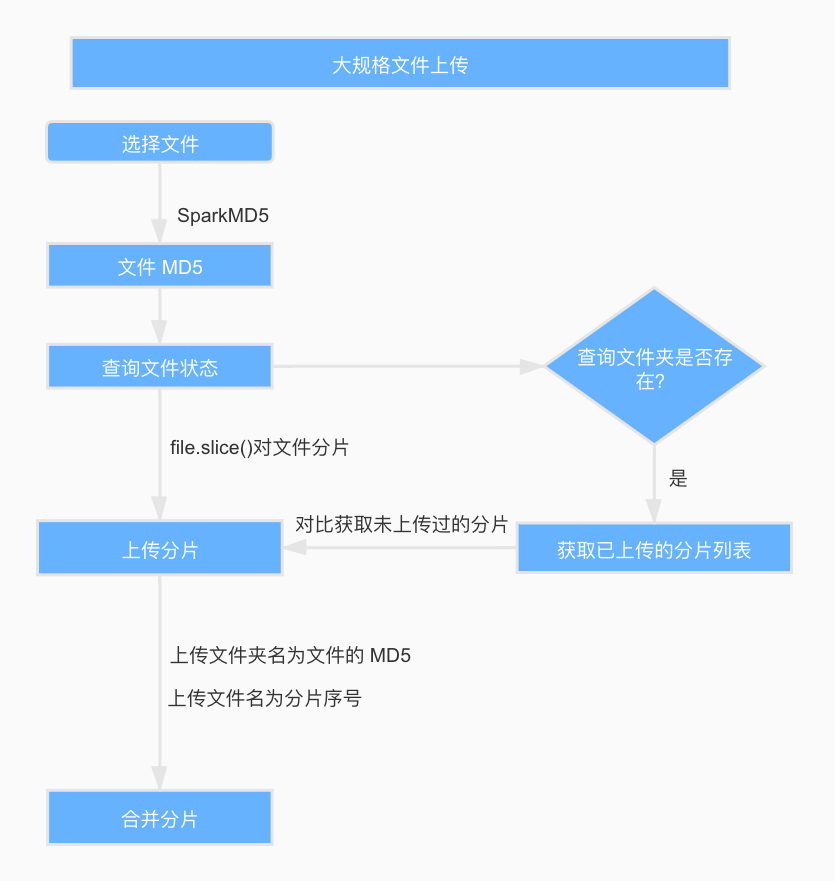
分为以下步骤实现:
1. 文件 MD5 加密
MD5 是文件的唯一标识,可以利用文件的 MD5 查询文件的上传状态。
根据文件的修改时间、文件名称、最后修改时间等信息,通过 spark-md5 生成文件的 MD5。需要注意的是,大规格文件需要分片读取文件,将读取的文件内容添加到 spark-md5 的 hash 计算中,直到文件读取完毕,最后返回最终的 hash 码到 callback 回调函数里面。这里可以根据需要添加文件读取的进度条。
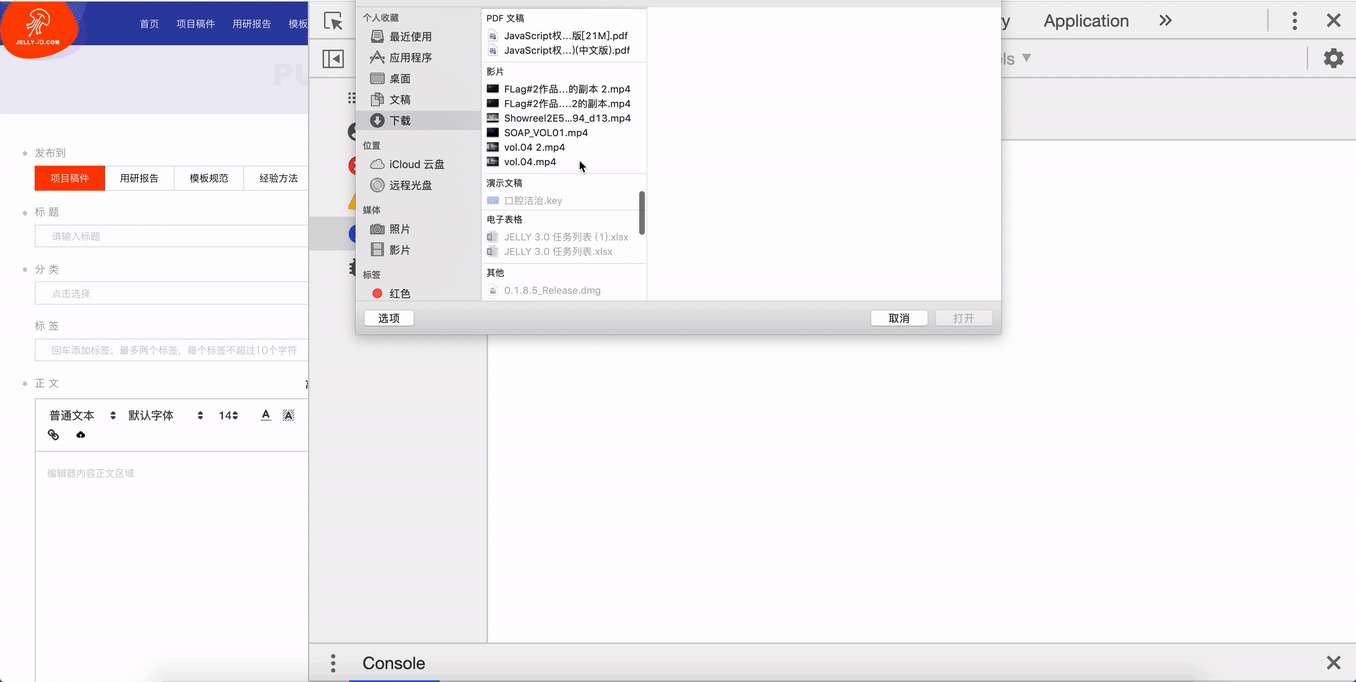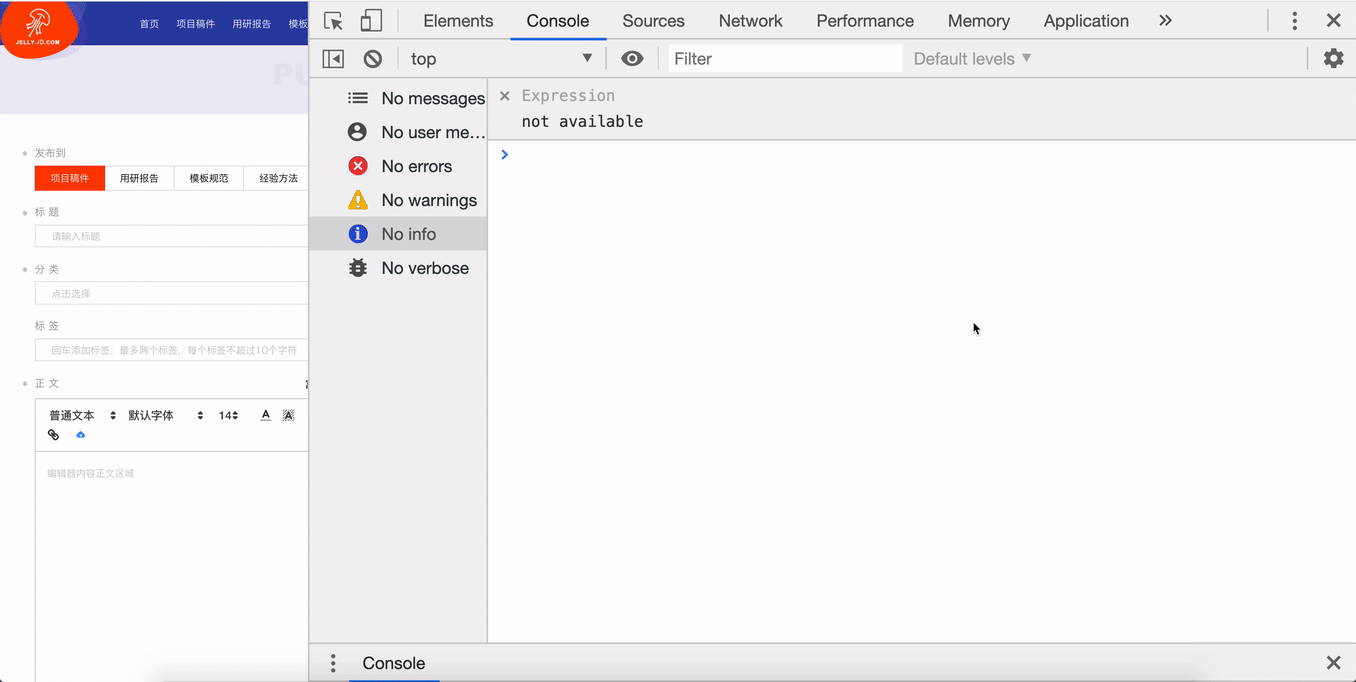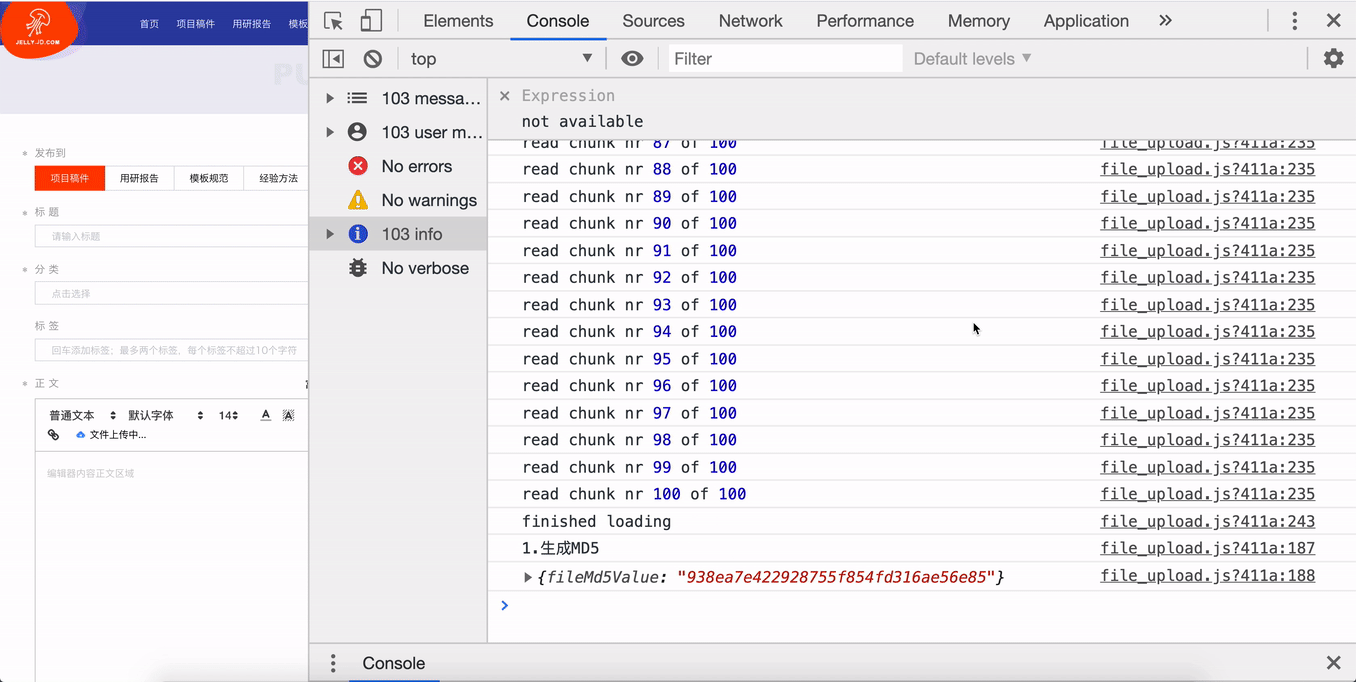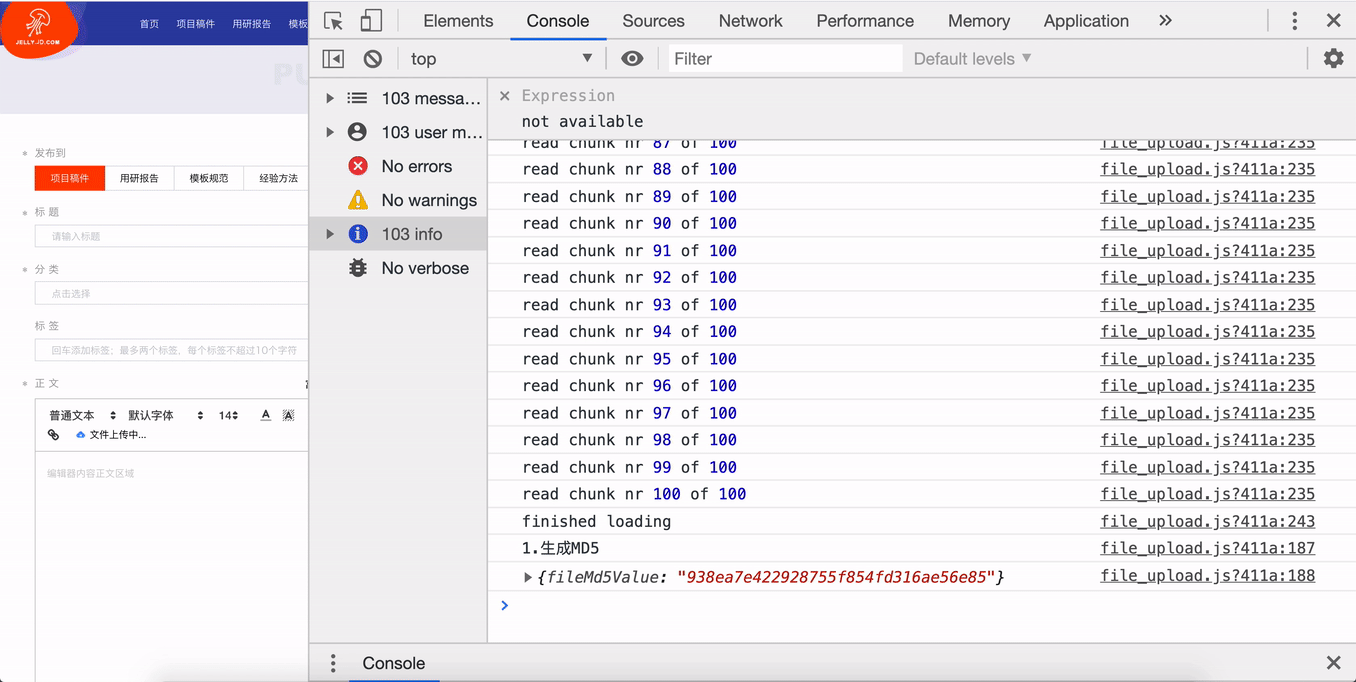
实现方法如下:
// 修改时间+文件名称+最后修改时间-->MD5md5File (file) { return new Promise((resolve, reject) => { let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice let chunkSize = file.size / 100 let chunks = 100 let currentChunk = 0 let spark = new SparkMD5.ArrayBuffer() let fileReader = new FileReader() fileReader.onload = function (e) { console.log('read chunk nr', currentChunk + 1, 'of', chunks) spark.append(e.target.result) // Append array buffer currentChunk++ if (currentChunk < chunks) { loadNext() } else { let cur = +new Date() console.log('finished loading') // alert(spark.end() + '---' + (cur - pre)); // Compute hash let result = spark.end() resolve(result) } } fileReader.onerror = function (err) { console.warn('oops, something went wrong.') reject(err) } function loadNext () { let start = currentChunk * chunkSize let end = start + chunkSize >= file.size ? file.size : start + chunkSize fileReader.readAsArrayBuffer(blobSlice.call(file, start, end)) } loadNext() })}2. 查询文件状态
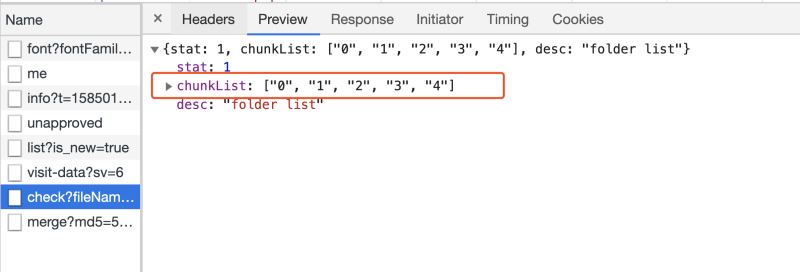
前端得到文件的 MD5 后,从后台查询是否存在名称为 MD5 的文件夹,如果存在,列出文件夹下所有文件,得到已上传的切片列表,如果不存在,则已上传的切片列表为空。
// 校验文件的MD5checkFileMD5 (file, fileName, fileMd5Value, onError) { const fileSize = file.size const { chunkSize, uploadProgress } = this this.chunks = Math.ceil(fileSize / chunkSize) return new Promise(async (resolve, reject) => { const params = { fileName: fileName, fileMd5Value: fileMd5Value, } const { ok, data } = await services.checkFile(params) if (ok) { this.hasUploaded = data.chunkList.length uploadProgress(file) resolve(data) } else { reject(ok) onError() } })}3. 文件分片
文件上传优化的核心就是文件分片,Blob 对象中的 slice 方法可以对文件进行切割,File 对象是继承 Blob 对象的,因此 File 对象也有 slice 方法。
定义每一个分片文件的大小变量为 chunkSize,通过文件大小 FileSize 和分片大小 chunkSize 得到分片数量 chunks,使用 for 循环和 file.slice() 方法对文件进行分片,序号为 0 - n,和已上传的切片列表做比对,得到所有未上传的分片,push 到请求列表 requestList。
async checkAndUploadChunk (file, fileMd5Value, chunkList) { let { chunks, upload } = this const requestList = [] for (let i = 0; i < chunks; i++) { let exit = chunkList.indexOf(i + '') > -1 // 如果已经存在, 则不用再上传当前块 if (!exit) { requestList.push(upload(i, fileMd5Value, file)) } } console.log({ requestList }) const result = requestList.length > 0 ? await Promise.all(requestList) .then(result => { console.log({ result }) return result.every(i => i.ok) }) .catch(err => { return err }) : true console.log({ result }) return result === true}4. 上传分片
调用 Promise.all 并发上传所有的切片,将切片序号、切片文件、文件 MD5 传给后台。
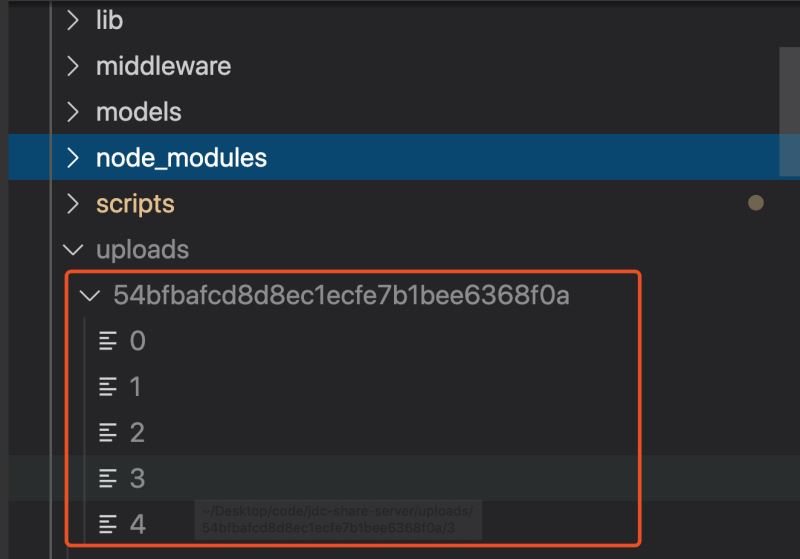
后台接收到上传请求后,首先查看名称为文件 MD5 的文件夹是否存在,不存在则创建文件夹,然后通过 fs-extra 的 rename 方法,将切片从临时路径移动切片文件夹中,结果如下:
当全部分片上传成功,通知服务端进行合并,当有一个分片上传失败时,提示“上传失败”。在重新上传时,通过文件 MD5 得到文件的上传状态,当服务器已经有该 MD5 对应的切片时,代表该切片已经上传过,无需再次上传,当服务器找不到该 MD5 对应的切片时,代表该切片需要上传,用户只需上传这部分切片,就可以完整上传整个文件,这就是文件的断点续传。
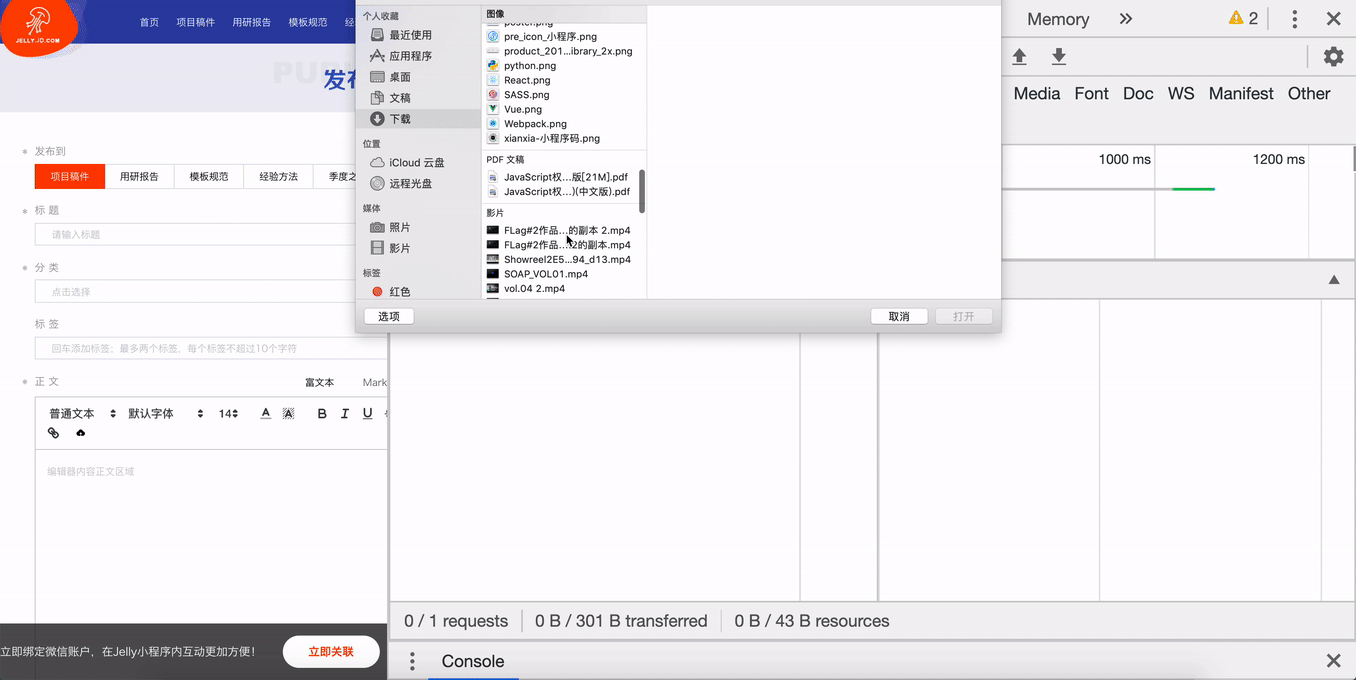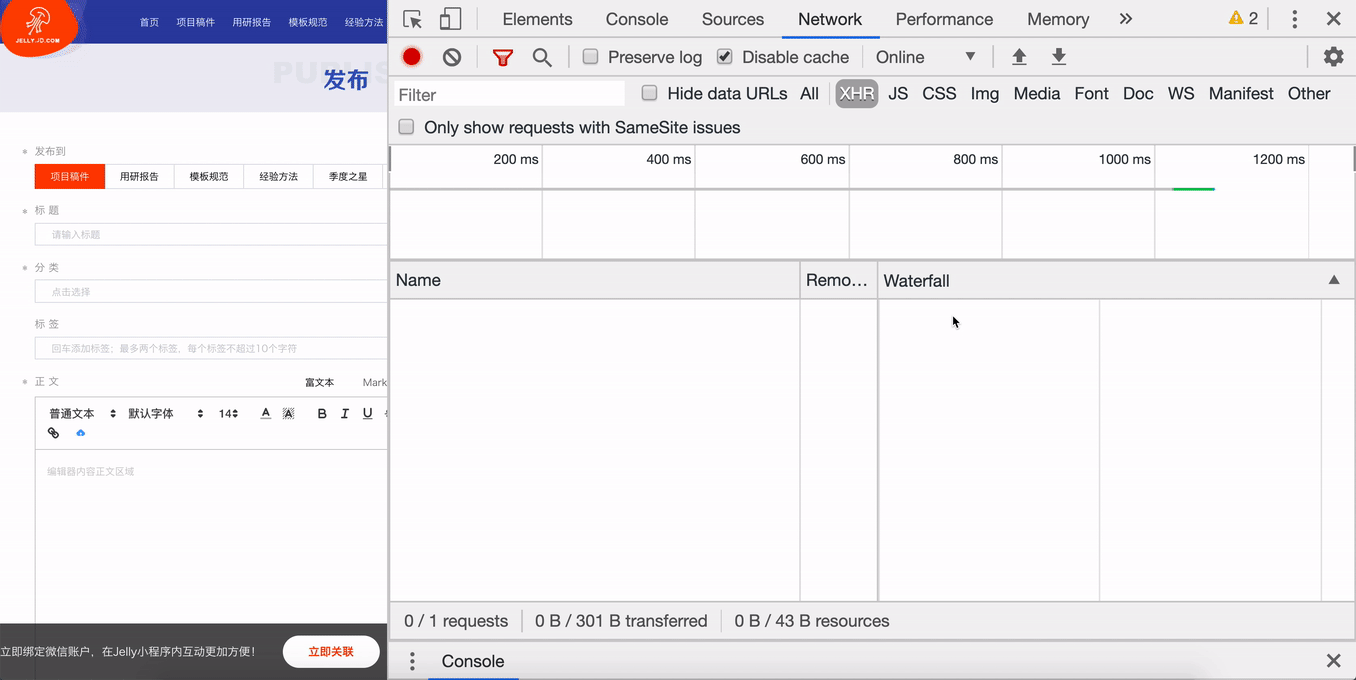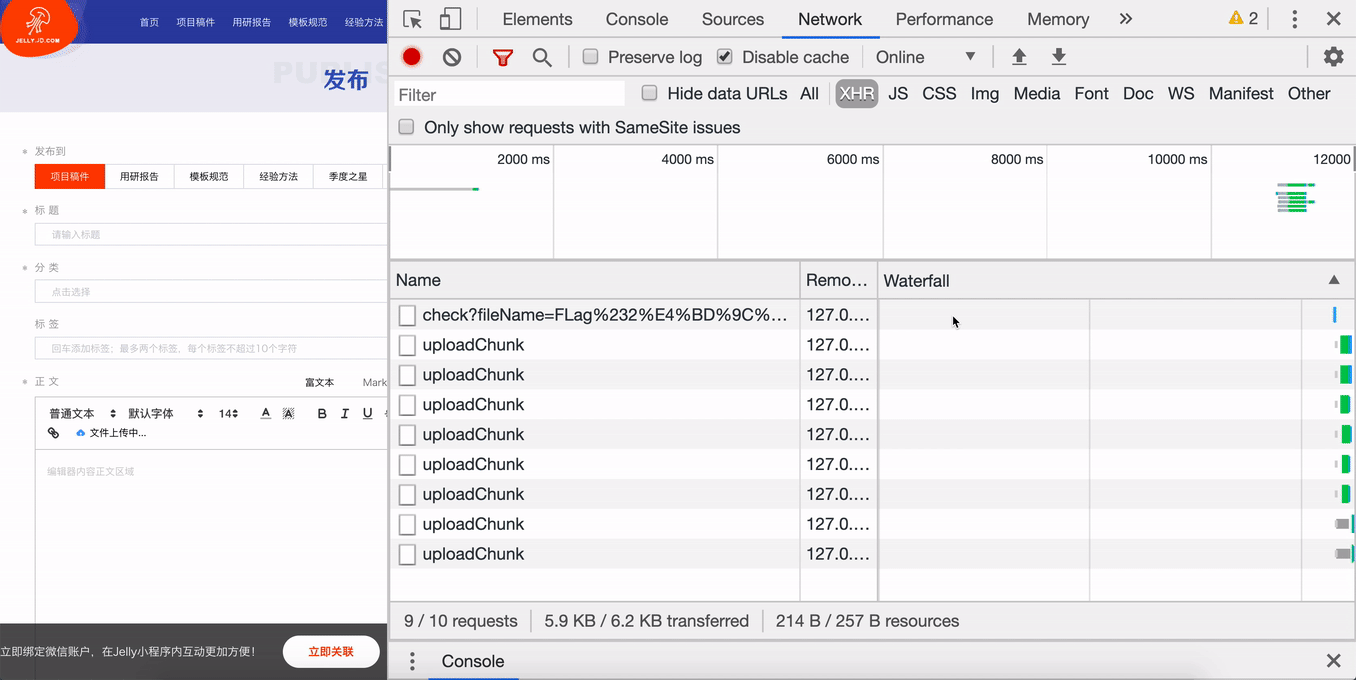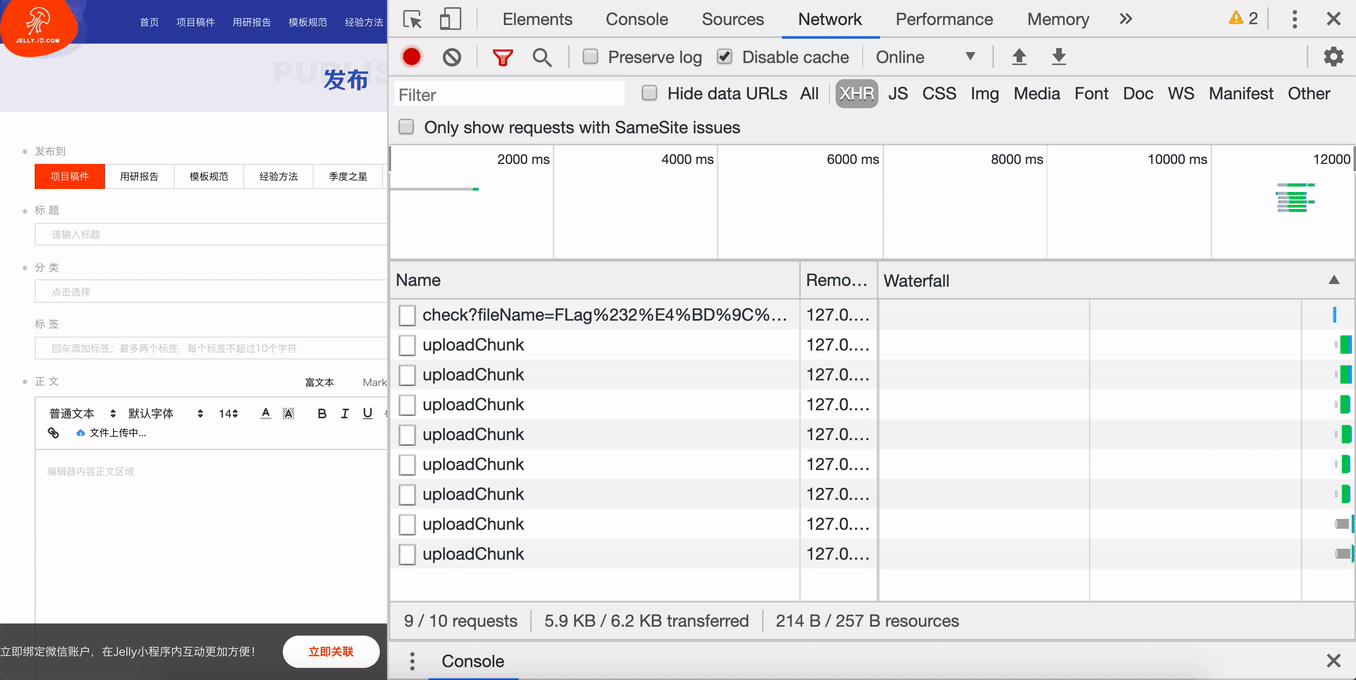
// 上传chunkupload (i, fileMd5Value, file) { const { uploadProgress, chunks } = this return new Promise((resolve, reject) => { let { chunkSize } = this // 构造一个表单,FormData是HTML5新增的 let end = (i + 1) * chunkSize >= file.size ? file.size : (i + 1) * chunkSize let form = new FormData() form.append('data', file.slice(i * chunkSize, end)) // file对象的slice方法用于切出文件的一部分 form.append('total', chunks) // 总片数 form.append('index', i) // 当前是第几片 form.append('fileMd5Value', fileMd5Value) services .uploadLarge(form) .then(data => { if (data.ok) { this.hasUploaded++ uploadProgress(file) } console.log({ data }) resolve(data) }) .catch(err => { reject(err) }) })}5. 上传进度
虽然分片批量上传比大文件单次上传会快很多,也还是有一段加载时间,这时应该加上上传进度的提示,实时显示文件上传进度。
原生 Javascript 的 XMLHttpRequest 有提供 progress 事件,这个事件会返回文件已上传的大小和总大小。项目使用 axios 对 ajax 进行封装,可以在 config 中增加 onUploadProgress 方法,监听文件上传进度。
const config = { onUploadProgress: progressEvent => { var complete = (progressEvent.loaded / progressEvent.total * 100 | 0) + '%' }}services.uploadChunk(form, config)6. 合并分片
上传完所有文件分片后,前端主动通知服务端进行合并,服务端接受到这个请求时主动合并切片,通过文件 MD5 在服务器的文件上传路径中找到同名文件夹。从上文可知,文件分片是按照分片序号命名的,而分片上传接口是异步的,无法保证服务器接收到的切片是按照请求顺序拼接。所以应该在合并文件夹里的分片文件前,根据文件名进行排序,然后再通过 concat-files 合并分片文件,得到用户上传的文件。至此大文件上传就完成了。
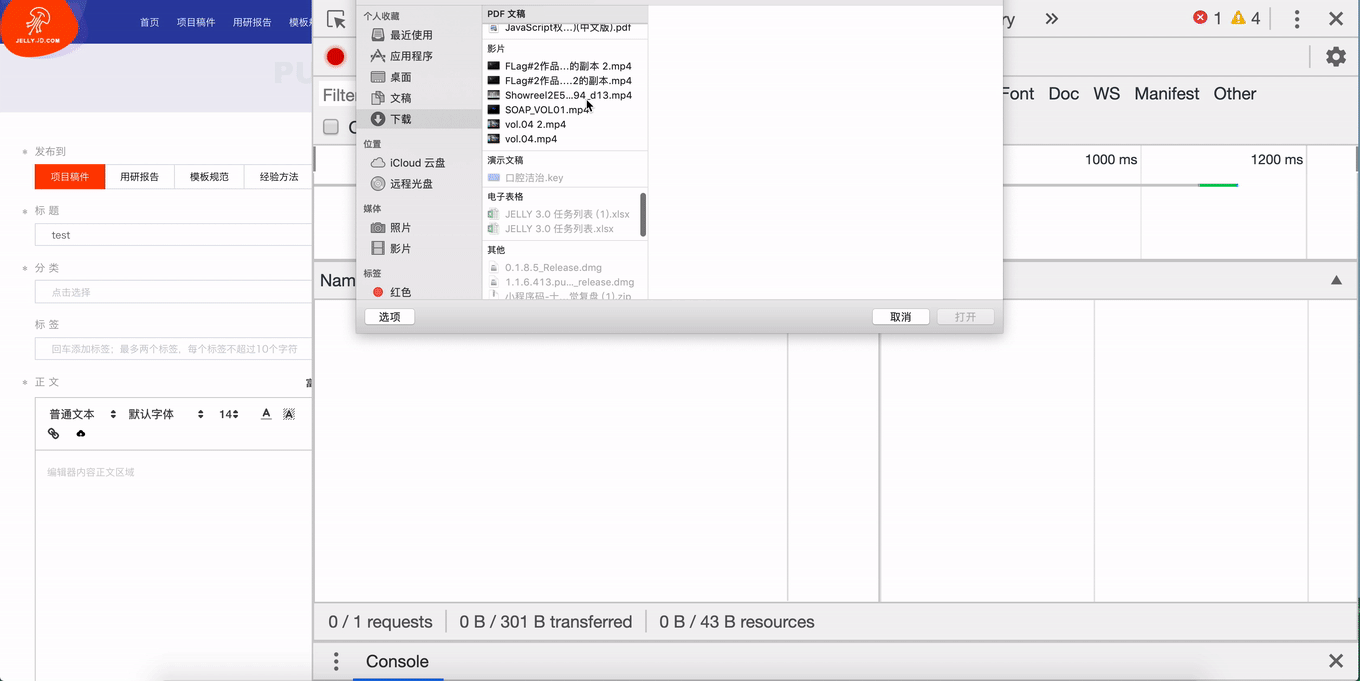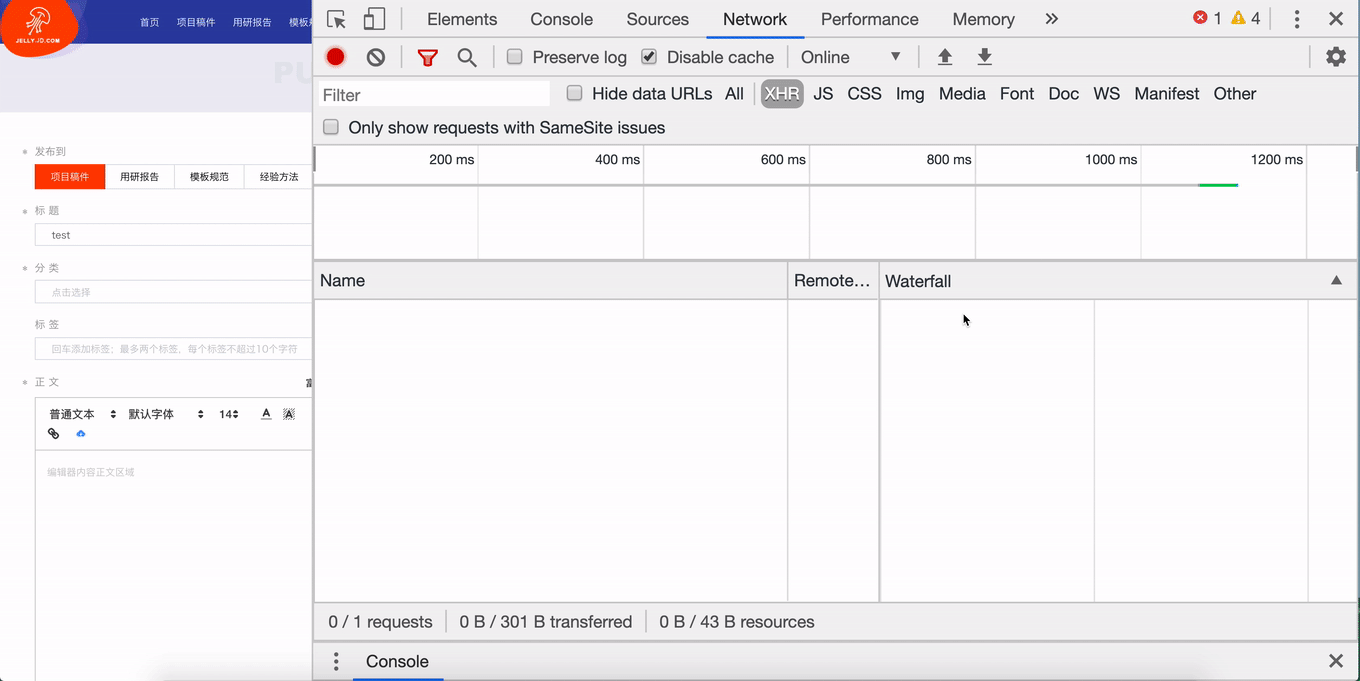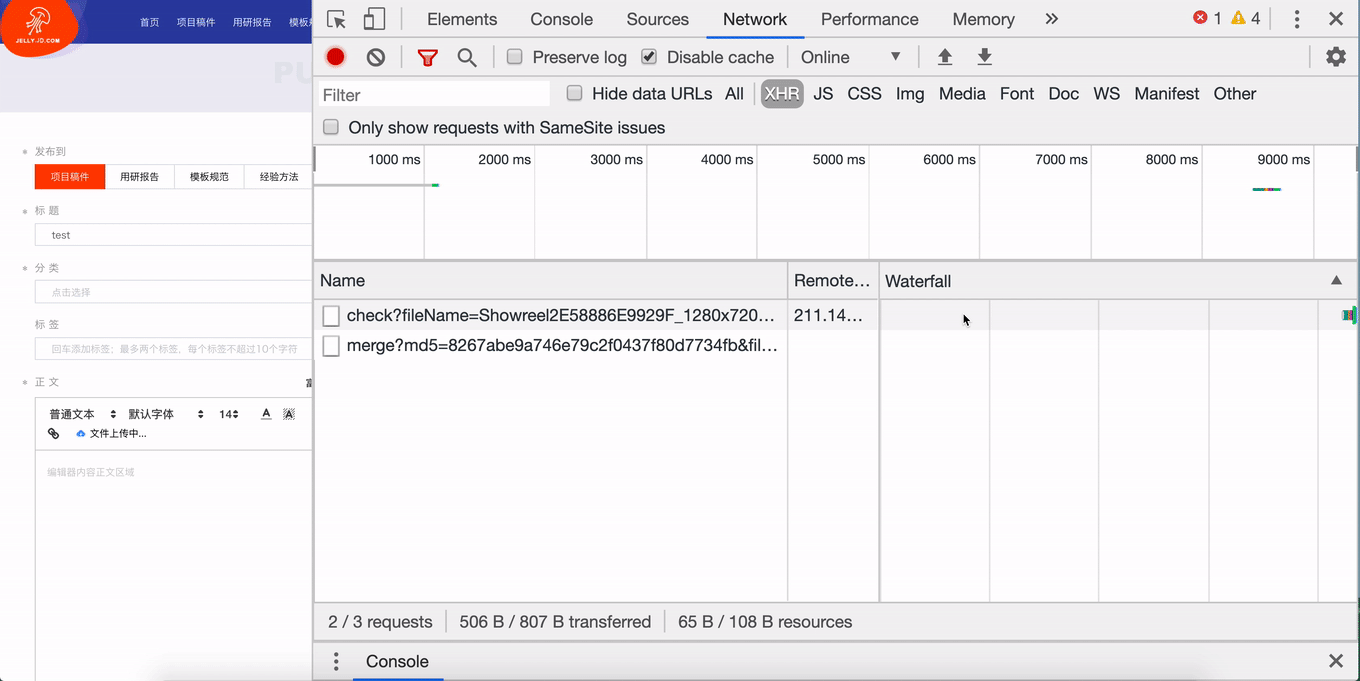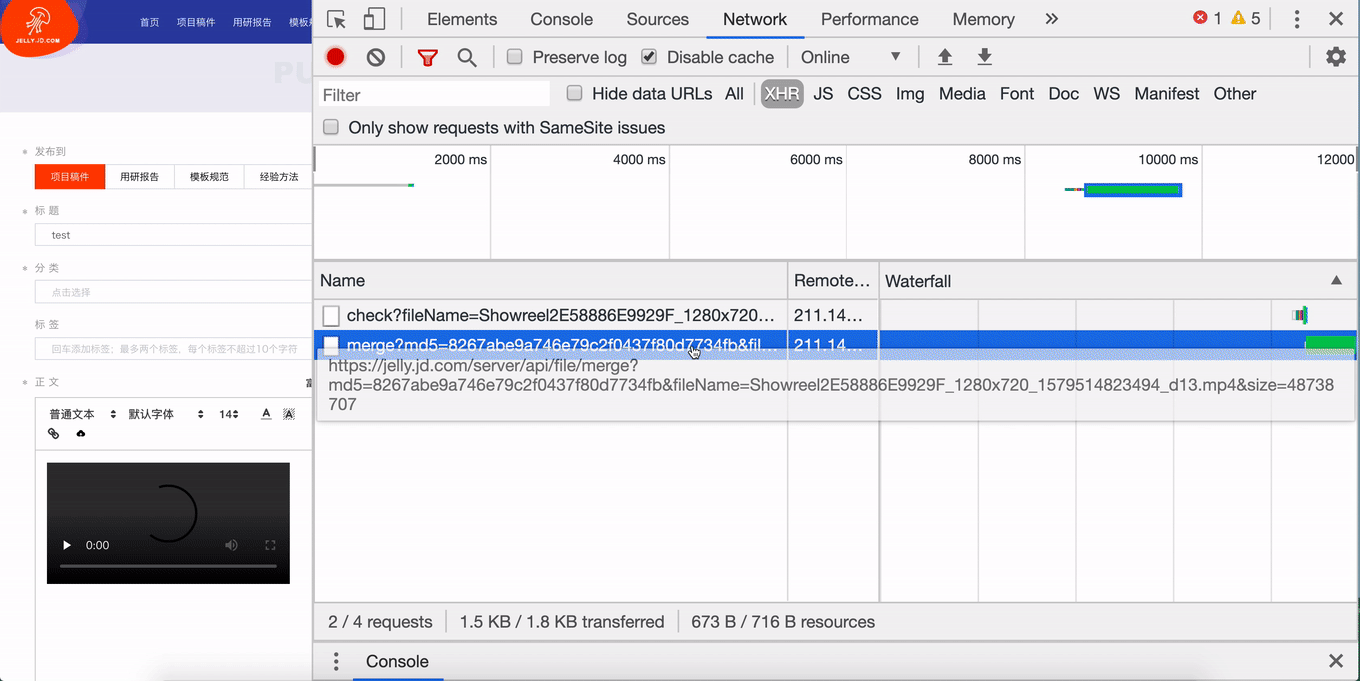
Node 端代码:
// 合并文件exports.merge = { validate: { query: { fileName: Joi.string() .trim() .required() .description('文件名称'), md5: Joi.string() .trim() .required() .description('文件md5'), size: Joi.string() .trim() .required() .description('文件大小'), }, }, permission: { roles: ['user'], }, async handler (ctx) { const { fileName, md5, size } = ctx.request.query let { name, base: filename, ext } = path.parse(fileName) const newFileName = randomFilename(name, ext) await mergeFiles(path.join(uploadDir, md5), uploadDir, newFileName, size) .then(async () => { const file = { key: newFileName, name: filename, mime_type: mime.getType(`${uploadDir}/${newFileName}`), ext, path: `${uploadDir}/${newFileName}`, provider: 'oss', size, owner: ctx.state.user.id, } const key = encodeURIComponent(file.key) .replace(/%/g, '') .slice(-100) file.url = await uploadLocalFileToOss(file.path, key) file.url = getFileUrl(file) const f = await File.create(omit(file, 'path')) const files = [] files.push(f) ctx.body = invokeMap(files, 'toJSON') }) .catch(() => { throw Boom.badData('大文件分片合并失败,请稍候重试~') }) },}总结
本文讲述了大规格文件上传优化的一些做法,总结为以下 4 点:
参照 Demo 源码 可快速上手上述功能
到此这篇关于大规格文件的上传优化思路详解的文章就介绍到这了,更多相关大文件上传优化内容请搜索武林网以前的文章或继续浏览下面的相关文章希望大家以后多多支持武林网!
新闻热点






疑难解答













