Acrobat 2017/2018中不像之前的版本在编辑中能找到写有OCR功能的选项,那是因为ocr识别改名为“编辑文本和图像”了,下面我们就来看看详细的教程。
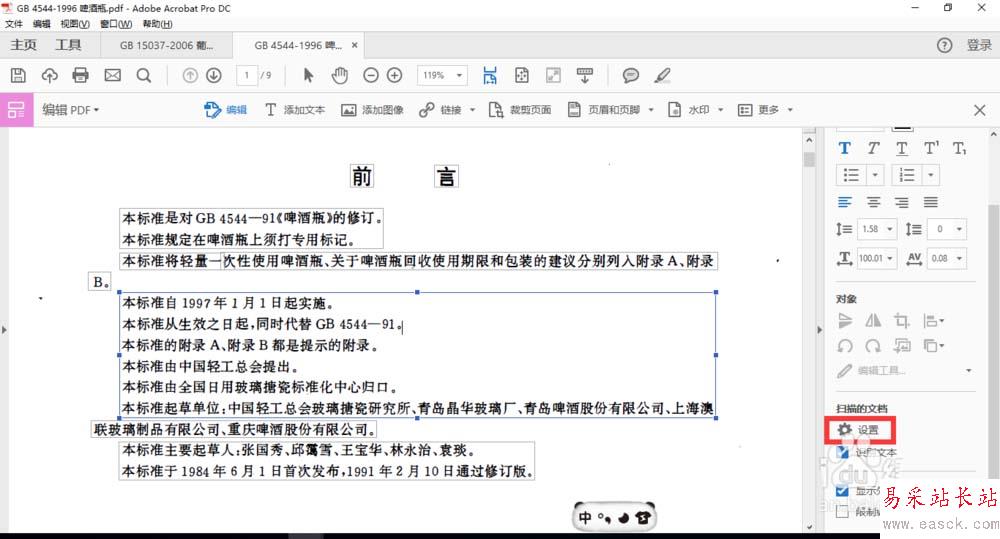
1、打开要识别的PDF,如果该PDF没有加密,那么点击“编辑-编辑文本和图像”或者在任意页面鼠标右击,选择“编辑图像”,就可以进行OCR识别了。
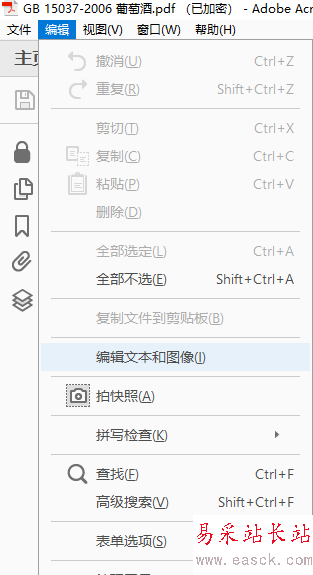

2、进行第一步之后,默认执行的单页的识别,但是如果你要识别整个PDF文件,怎么办?
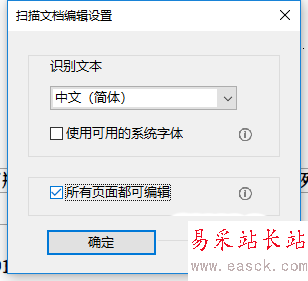
3、点击图中右下角扫描文档下的“设置”,在弹出的窗口中勾选“所有页面均可编辑”,点击确定,再点击编辑图像时,就可以全篇识别了。
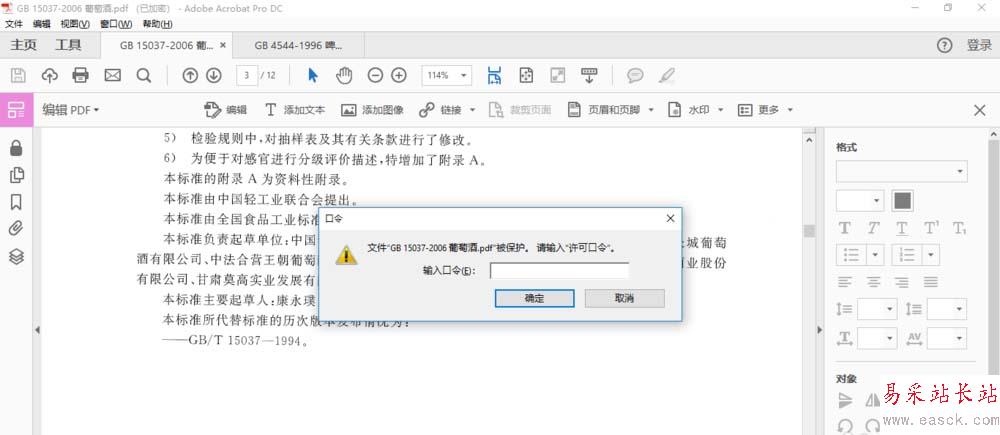
4、但是面对加密的文档,会提示需要“输入口令”,这个时候需要使用软件PDFPasswordRmover,移除PDF的密码,就可以按照上面的方法愉快的OCR识别了。有时也会出现,点了“编辑图像”,但是未能进行OCR识别,只是把当页识别成一整张图片,我也用PDFPasswordRmover处理了一下,然后再进行OCR识别,就没问题了。
以上就是Acrobat2018找不到OCR识别的原因,直接使用编辑文本和图像也是一样的功能,希望大家喜欢,请继续关注错新站长站。
相关推荐:
Acrobat编辑器怎么去除PDF签名?
Acrobat Pro怎么将PDF文件中的文字全部转曲?
Adobe Acrobat怎么将cmyk四色黑变成单色黑?
新闻热点






疑难解答