PDF扫描件都是由图片组成的,文字是无法直接复制,想要制作一个双层pdf文件,有图片,还可以直接复制文字,该怎么实现呢?我们可以通过使用Acrobat软件,我们可以使用软件所带的OCR识别工具,为PDF文档增加一层透明文字层,从而制作出双层PDF。使得PDF看起来是扫描件,但可以直接复制文字,下面我们就来看看详细的教程。
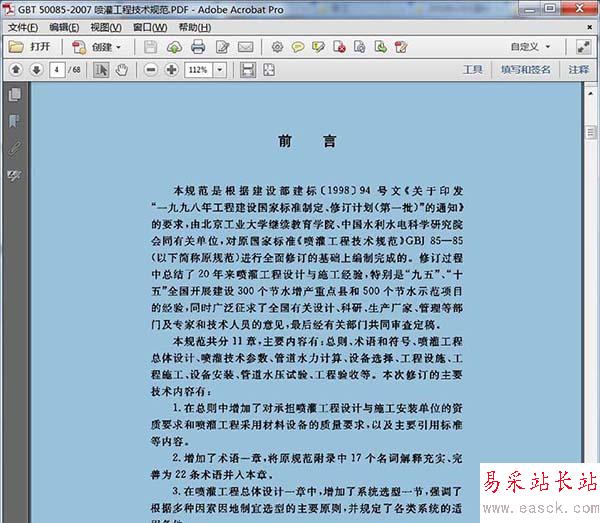
1、下面是扫描生成的PDF文档,可以看出,文字是无法直接复制的。
2、点击Acrobat软件工具栏右上角的“工具”选项,打开“文本识别“,然后点击“在本文件中”。
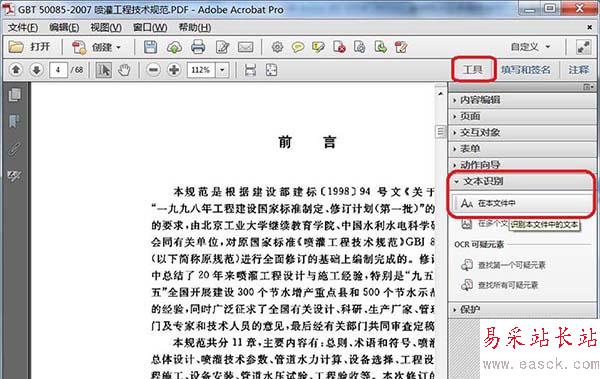
3、在弹出的“识别文本”对话框中,点击“编辑”进行文字识别参数的设置。
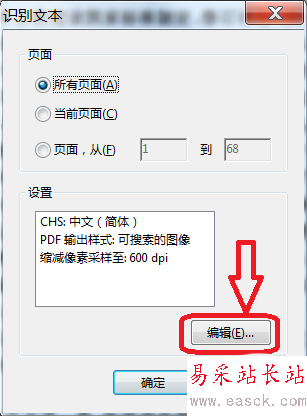
4、文字识别参数设置:OCR识别的主要语言(这里选择简体中文);
PDF输出样式:可搜索的图像、可搜索的图像(精确)、ClearScan(这里保持默认);
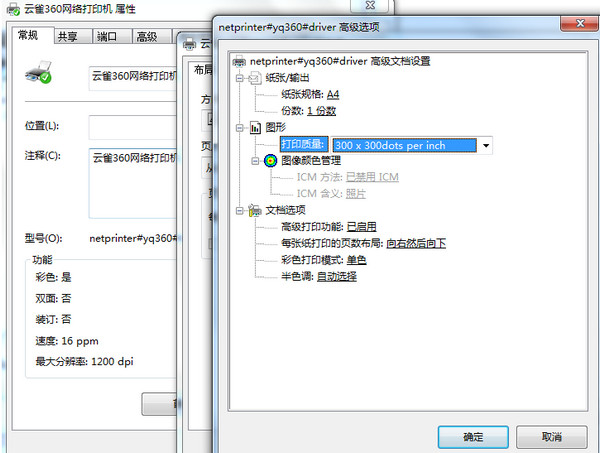
缩减像素采样至:600、300、150、72dpi(如果要打印建议不要小于150dpi)。
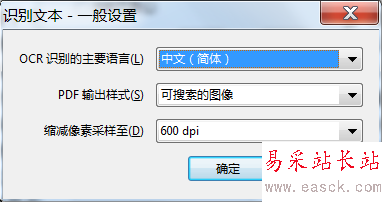
5、文字识别参数设置完成后,点击确认开始文字识别。
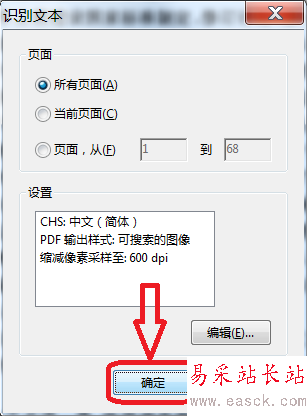
6、可以看到软件界面底部有个文字识别进度条,如果文件较大,识别时间将会比较长,这是我们可以做些其他事情。
7、文字识别完成,可以看到,可以通过文本选择工具进行选择了。可以看出,识别准确率还是比较高的,如果需要对文字进行校对,可以查阅相关教程。
8、对比可见,添加透明文字层后,对源文件大小影响不大。

以上就是PDF扫描件制作可复制文字的双层PDF的教程,希望大家喜欢,请继续关注错新站长站。
相关推荐:
Acrobat怎么给PDF添加用户签名?
Acrobat Pro怎么将PDF文件中的文字全部转曲?
Acrobat2018怎么使用OCR识别扫描版PDF中的文字?
新闻热点






疑难解答