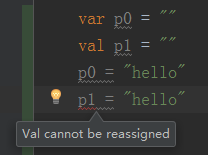
如下所示:
package com.lyt.base.util;import java.util.regex.Pattern;public class FilterHtmlUtil {public static String Html2Text(String inputString){ String htmlStr = inputString; //含html标签的字符串 String textStr =""; java.util.regex.Pattern p_script; java.util.regex.Matcher m_script; java.util.regex.Pattern p_style; java.util.regex.Matcher m_style; java.util.regex.Pattern p_html; java.util.regex.Matcher m_html; try{ String regEx_script = "<[//s]*?script[^>]*?>[//s//S]*?<[//s]*?///[//s]*?script[//s]*?>"; //定义script的正则表达式{或<script[^>]*?>[//s//S]*?<///script> } String regEx_style = "<[//s]*?style[^>]*?>[//s//S]*?<[//s]*?///[//s]*?style[//s]*?>"; //定义style的正则表达式{或<style[^>]*?>[//s//S]*?<///style> } String regEx_html = "<[^>]+>"; //定义HTML标签的正则表达式 p_script = Pattern.compile(regEx_script,Pattern.CASE_INSENSITIVE); m_script = p_script.matcher(htmlStr); htmlStr = m_script.replaceAll(""); //过滤script标签 p_style = Pattern.compile(regEx_style,Pattern.CASE_INSENSITIVE); m_style = p_style.matcher(htmlStr); htmlStr = m_style.replaceAll(""); //过滤style标签 p_html = Pattern.compile(regEx_html,Pattern.CASE_INSENSITIVE); m_html = p_html.matcher(htmlStr); htmlStr = m_html.replaceAll(""); //过滤html标签 textStr = htmlStr; }catch(Exception e){ e.printStackTrace(); } return textStr;//返回文本字符串} }以上这篇java过滤html标签获取纯文本信息的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持VeVb武林网。
新闻热点






疑难解答
图片精选