Flink 的网络协议栈是组成 flink-runtime 模块的核心组件之一,是每个 Flink 作业的核心。它连接所有 TaskManager 的各个子任务(Subtask),因此,对于 Flink 作业的性能包括吞吐与延迟都至关重要。与 TaskManager 和 JobManager 之间通过基于 Akka 的 RPC 通信的控制通道不同,TaskManager 之间的网络协议栈依赖于更加底层的 Netty API。
本文将首先介绍 Flink 暴露给流算子(Stream operator)的高层抽象,然后详细介绍 Flink 网络协议栈的物理实现和各种优化、优化的效果以及 Flink 在吞吐量和延迟之间的权衡。
Apache Flink的网络协议栈详细介绍
1.逻辑视图
Flink 的网络协议栈为彼此通信的子任务提供以下逻辑视图,例如在 A 通过 keyBy() 操作进行数据 Shuffle :
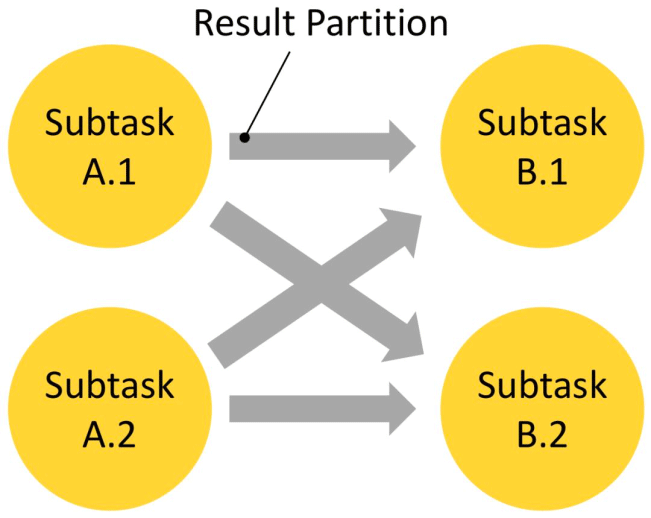
这一过程建立在以下三种基本概念的基础上:
� 子任务输出类型(ResultPartitionType):
Pipelined(有限的或无限的):一旦产生数据就可以持续向下游发送有限数据流或无限数据流。 Blocking:仅在生成完整结果后向下游发送数据。
� 调度策略:
同时调度所有任务(Eager):同时部署作业的所有子任务(用于流作业)。
上游产生第一条记录部署下游(Lazy):一旦任何生产者生成任何输出,就立即部署下游任务。
上游产生完整数据部署下游:当任何或所有生产者生成完整数据后,部署下游任务。
� 数据传输:
高吞吐:Flink 不是一个一个地发送每条记录,而是将若干记录缓冲到其网络缓冲区中并一次性发送它们。这降低了每条记录的发送成本因此提高了吞吐量。 低延迟:当网络缓冲区超过一定的时间未被填满时会触发超时发送,通过减小超时时间,可以通过牺牲一定的吞吐来获取更低的延迟。
我们将在下面深入 Flink 网络协议栈的物理实现时看到关于吞吐延迟的优化。对于这一部分,让我们详细说明输出类型与调度策略。首先,需要知道的是子任务的输出类型和调度策略是紧密关联的,只有两者的一些特定组合才是有效的。
Pipelined 结果是流式输出,需要目标 Subtask 正在运行以便接收数据。因此需要在上游 Task 产生数据之前或者产生第一条数据的时候调度下游目标 Task 运行。批处理作业生成有界结果数据,而流式处理作业产生无限结果数据。
批处理作业也可能以阻塞方式产生结果,具体取决于所使用的算子和连接模式。在这种情况下,必须等待上游 Task 先生成完整的结果,然后才能调度下游的接收 Task 运行。这能够提高批处理作业的效率并且占用更少的资源。
下表总结了 Task 输出类型以及调度策略的有效组合:
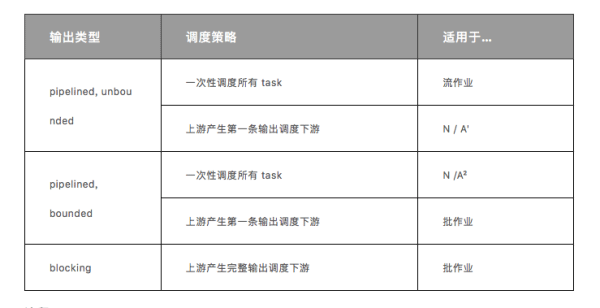
注释:
目前 Flink 未使用 批处理 / 流计算统一完成后,可能适用于流式作业
此外,对于具有多个输入的子任务,调度以两种方式启动:当所有或者任何上游任务产生第一条数据或者产生完整数据时调度任务运行。要调整批处理作业中的输出类型和调度策略,可以参考 ExecutionConfig#setExecutionMode()——尤其是 ExecutionMode,以及 ExecutionConfig#setDefaultInputDependencyConstraint()。
2.物理数据传输
为了理解物理数据连接,请回想一下,在 Flink 中,不同的任务可以通过 Slotsharing group 共享相同 Slot。TaskManager 还可以提供多个 Slot,以允许将同一任务的多个子任务调度到同一个 TaskManager 上。
对于下图所示的示例,我们假设 2 个并发为 4 的任务部署在 2 个 TaskManager 上,每个 TaskManager 有两个 Slot。TaskManager 1 执行子任务 A.1,A.2,B.1 和 B.2,TaskManager 2 执行子任务 A.3,A.4,B.3 和 B.4。在 A 和 B 之间是 Shuffle 连接类型,比如来自于 A 的 keyBy() 操作,在每个 TaskManager 上会有 2x4 个逻辑连接,其中一些是本地的,另一些是远程的:

不同任务(远程)之间的每个网络连接将在 Flink 的网络堆栈中获得自己的 TCP 通道。但是,如果同一任务的不同子任务被调度到同一个 TaskManager,则它们与同一个 TaskManager 的网络连接将多路复用并共享同一个 TCP 信道以减少资源使用。在我们的例子中,这适用于 A.1→B.3,A.1→B.4,以及 A.2→B.3 和 A.2→B.4,如下图所示:
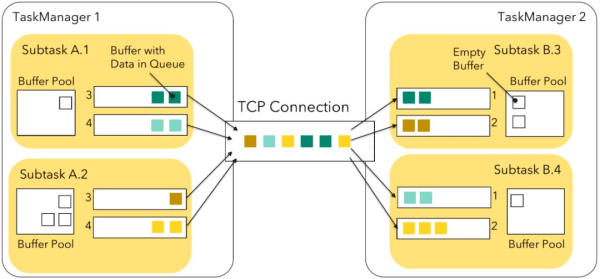
每个子任务的输出结果称为 ResultPartition,每个 ResultPartition 被分成多个单独的 ResultSubpartition- 每个逻辑通道一个。Flink 的网络协议栈在这一点的处理上,不再处理单个记录,而是将一组序列化的记录填充到网络缓冲区中进行处理。每个子任务本地缓冲区中最多可用 Buffer 数目为(每个发送方和接收方各一个):
#channels * buffers-per-channel + floating-buffers-per-gate
单个 TaskManager 上的网络层 Buffer 总数通常不需要配置。有关如何在需要时进行配置的详细信息,请参阅配置网络缓冲区的文档。
� 造成反压(1)
每当子任务的数据发送缓冲区耗尽时——数据驻留在 Subpartition 的缓冲区队列中或位于更底层的基于 Netty 的网络堆栈内,生产者就会被阻塞,无法继续发送数据,而受到反压。接收端以类似的方式工作:Netty 收到任何数据都需要通过网络 Buffer 传递给 Flink。如果相应子任务的网络缓冲区中没有足够可用的网络 Buffer,Flink 将停止从该通道读取,直到 Buffer 可用。这将反压该多路复用上的所有发送子任务,因此也限制了其他接收子任务。下图说明了过载的子任务 B.4,它会导致多路复用的反压,也会导致子任务 B.3 无法接受和处理数据,即使是 B.3 还有足够的处理能力。

为了防止这种情况发生,Flink 1.5 引入了自己的流量控制机制。
3.Credit-based 流量控制
Credit-based 流量控制可确保发送端已经发送的任何数据,接收端都具有足够的能力(Buffer)来接收。新的流量控制机制基于网络缓冲区的可用性,作为 Flink 之前机制的自然延伸。每个远程输入通道(RemoteInputChannel)现在都有自己的一组独占缓冲区(Exclusive buffer),而不是只有一个共享的本地缓冲池(LocalBufferPool)。与之前不同,本地缓冲池中的缓冲区称为流动缓冲区(Floating buffer),因为它们会在输出通道间流动并且可用于每个输入通道。
数据接收方会将自身的可用 Buffer 作为 Credit 告知数据发送方(1 buffer = 1 credit)。每个 Subpartition 会跟踪下游接收端的 Credit(也就是可用于接收数据的 Buffer 数目)。只有在相应的通道(Channel)有 Credit 的时候 Flink 才会向更底层的网络协议栈发送数据(以 Buffer 为粒度),并且每发送一个 Buffer 的数据,相应的通道上的 Credit 会减 1。除了发送数据本身外,数据发送端还会发送相应 Subpartition 中有多少正在排队发送的 Buffer 数(称之为 Backlog)给下游。数据接收端会利用这一信息(Backlog)去申请合适数量的 Floating buffer 用于接收发送端的数据,这可以加快发送端堆积数据的处理。接收端会首先申请和 Backlog 数量相等的 Buffer,但可能无法申请到全部,甚至一个都申请不到,这时接收端会利用已经申请到的 Buffer 进行数据接收,并监听是否有新的 Buffer 可用。
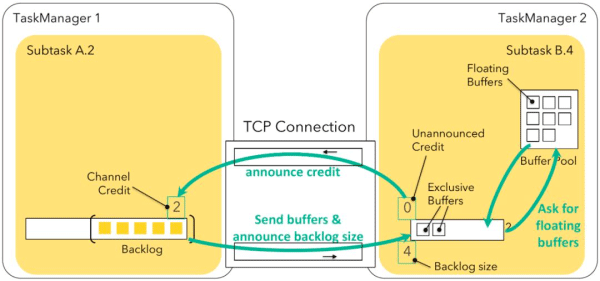
Credit-based 的流控使用 Buffers-per-channel 来指定每个 Channel 有多少独占的 Buffer,使用 Floating-buffers-per-gate 来指定共享的本地缓冲池(Local buffer pool)大小(可选3),通过共享本地缓冲池,Credit-based 流控可以使用的 Buffer 数目可以达到与原来非 Credit-based 流控同样的大小。这两个参数的默认值是被精心选取的,以保证新的 Credit-based 流控在网络健康延迟正常的情况下至少可以达到与原策略相同的吞吐。可以根据实际的网络 RRT (round-trip-time)和带宽对这两个参数进行调整。
注释3:如果没有足够的 Buffer 可用,则每个缓冲池将获得全局可用 Buffer 的相同份额(±1)。
新闻热点






疑难解答