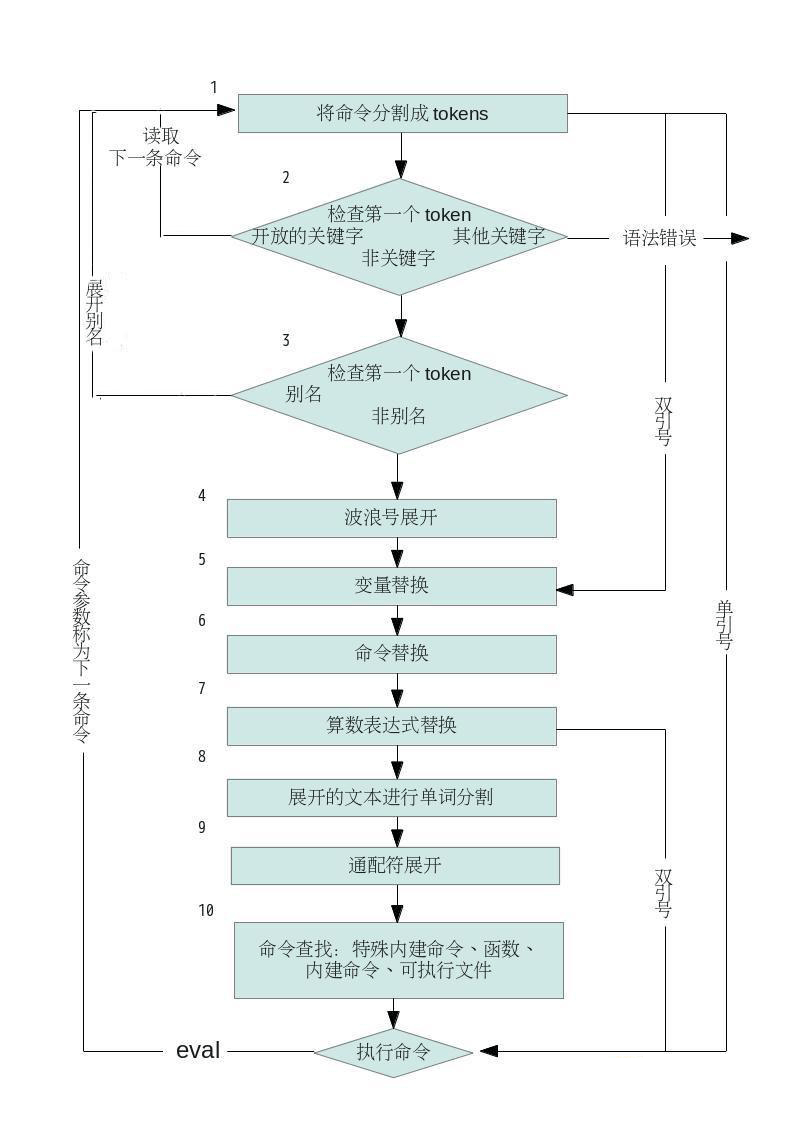
该进入第四章了,刚才看到一个帖子标题:我空有一身泡妞的好本领,但可惜自己是个妞。汗~这个。。。音乐无国界嘛,这个不应该也没性别界么?
第四章文本处理工具
书中先说明了以下排序的规则,数值的就不用说了,该大就大该小就小,但是字符型很多时候是区分声调或者重音的。在命令行中输入locale查看自己系统的编码配置。默认的是系统配置里的,但是可以自己设置排序的编码。如:
下边介绍以下排序命令sort:
语法: sort [ options ] [ file(s} ]
主要选项: -b 忽略开头的空白
-c 检查输入是否已正确地排序。如果未排序,则退出码为非零值,不会有任何输出
-d 字典顺序,仅文字数字和空白才有意义。
-g 一般数值:以浮点数字类型比较字段。仅GNU版本提供此选项功能
-f 将混用的字母都看作相同大小写,即忽略大小写。
-i 忽略无法打印的字符。
-k 定义排序键值字段
-m 将已排序的输入文件,合并为一个排序后的输出数据流
-n 以整数类型比较字段
-o outfile 将输出写到指定文件
-r 倒置排序由大到小,默认由小到大
-t char 使用单个字符char作为默认的字段分隔符取代空白字符
-u 只有唯一记录,丢弃所有具有相同键值的记录只留第一条。
另外排序键值字段类型标识,即-k一个字段之后的修饰符字母:
b 忽略开头的空白
d 字典顺序
f 不区分大小写
g 以一般的浮点数进行比较,只适用GNU版本
i 忽略无法打印的字符
n 以整数数字比较
r 倒置排序顺序
字段以及字段里的字符是由1开始编号的。如果仅指定一个字段编号,则排序键值会自该字段的起始处开始,一直继续到记录的结尾(而非字段结尾)。
如果给的是一对用逗号隔开的字段数字,则排序键值将由第一个字段值起开始,到第二个指定字段结尾结束。可能出现多个-k,会从第一个开始。
例子:
有时候我们还十分关心排序的稳定性,默认情况下是不稳定的,但是GNU实现了coreutils包弥补了不足,可以通过--stable选项来解决稳定性问题。(不懂稳定性的简单说一下:意思就是排序键值等同的时候需要以输入顺序来输出,即排序不打乱输入顺序)
有时候我们还需要解决输入数据的重复问题,sort -u能够解决一些,但是它消除的操作依据的是匹配的键值,而非匹配的记录。uniq命令提供另一种过滤数据的方式:它常用于管道中,用来删除已适用sort排序完成的重复记录。uniq有3个好用的选项:-c 可在每个输出行之前加上该行的重复次数。 -d选项则用于仅显示重复的行。 -u仅显示未重复的行。这里需要注意一点,uniq处理数据前是需要sort对数据进行排序的!
另外我们处理大量这样的数据的时候,我们需要重新格式化段落以方便我们使用或阅读。这时候可以使用fmt命令,有两个常用的选项:-s 仅切割较长的行,短行不会合并 ; -w n 则设置输出行宽度为n个字符(默认75个左右)。要考虑fmt移植性的请另行查询文档。
这里对可能使用到的统计行数、字数、字符数的wc命令做一个介绍,选项有-c 字节数 -l行数 -w 字数 。默认情况下给出行数 字数 字节数。
好了,处理了那么多文本,我们可能要打印出来看看,unix里支持的打印功能包括两类不同的命令,但拥有相同的功能,商用的unix系统与GNU/linux通常两种都支持,不过BSD系统仅支持Berkeley风格,POSIX则只定义了lp命令。
两套命令的例子:
然后是System V风格的:
有时需打印数据需要加上页码或者时间戳,可以使用pr预处理要打印的数据。
语法:pr [ options ] [ file(s) ]
主要选项:
-cn 产生n栏的输出,可以简化成-n
-f 在首页之后的每一页标题前置一个ASCII分页字符标题,(有的环境下是-F)
-h althdr 将页标题内的文件名称,改用字符串althdr取代。
-ln 产生n行的页面
-on 输出位移n个空白
-t 不显示标题
-wn 每行至多n个字符。以单栏输出而言,如有需要会将较长的行切分绕回至另外一行;否则,在多栏输出的情况下,会截去长的行以符合指定。样例:
pr -f -l60 -o10 -w65 file(s) | lp 。
还有其他打印工具,这里说的比较简单,有这方面需求可以再搜些文档看看。
第五章管道的神奇魔力
在linux下的管理性文件,大部分都是文本文件,可以直接编辑阅读的,这些文件大部分放在标准目录:/etc下。我们写shell脚本的时候大部分时候都是在处理文本信息,而管道是可以一直顺序着连着使用的 如 .... | ... | ... 这样,书中举了个连着使用5个管道的处理passwd文件的例子说很厉害,大致就是这样。然后又写了一个脚本把文本转化成HTML文件。然后又弄了一个根据正则匹配的脚本来帮助玩文字解密游戏。再然后通过管道计算出了各种莎士比亚基本的单词出现频率等。管道的神奇就不罗嗦了。
第六章变量、判断、重复动作
有两个相似命令提供变量的管理,一个是readonly,可以将变量设置为只读模式,就是成为符号常量。export用于修改或者打印环境变量。他们都由一个-p选项,意思是打印命令的名称以及所有被导出(只读)变量的名称和值,这种方式可使得shell重新读取输出以便重新建立环境(只读设置)。
export -p可以显示所有当前的环境变量,如果要从程序的环境中删除变量,则要用env命令,也可以临时的改变环境变量值:
env -i PATH=$PATH HOME=$HOME LC_ALL=C .....
-i选项用来初始化(initializes)环境变量的,也就是丢弃任何的继承值,仅传递命令行上指定的变量给程序使用。
unset命令从执行中的shell中删除变量和函数,默认情况下,它会解除变量设置,也可以加上-v完成:
unset full_name #删除full_name变量
unset -v firest middle last #删除多个变量
unset -f full_function #删除函数
这里我尝试用unset删除readonly变量,发现无法删除。然后查询了以下,发现常量声明之后就无法更改包括删除,只有注销当前shell。
有时候输出某个变量时,希望连接别的字符,可以在变量名左右添加花括号如:
echo _${myvar}_ #这样会输出myvar变量并在前后增加下划线。
这样叫做参数的展开。如果变量未定义,展开后是null。
还有一种替换运算符:
${varname:-word} #如果varname存在且非null,则返回其值,否则返回word。
${varname:=word} #如果varname存在且非null,则返回其值,否则设置它为word然后再返回其值。
${varname:?message} #如果varname存在且非null,则返回它的值,否则显示varname:message,并退出当前的命令或脚本,如果省略message会出现默认信息parameter null or net set。
${varname:+word} #如果varname存在且非null,则返回word,否则返回null。
以上每个运算符内的冒号(:)都是可选的。如果省略冒号,则将每个定义中的“存在且非null”部分改为“存在”,也就是说,运算符仅用于测试变量是否存在。
还有模式匹配运算符#:
${variable#pattern} #如果模式匹配于变量值的开头处,则删除匹配的最短部分,并返回剩下的部分。
${variable##pattern} #如果模式匹配于变量值的开头处,则删除匹配的最长部分,并返回剩下的部分。
${variable%pattern} #如果模式匹配于变量的结尾处,则删除匹配的最短部分,并返回剩下的部分。
${variable%%pattern} #如果模式匹配于变量值的结尾处,则删除匹配的最长部分,并返回剩下的部分。
最后,POSIX标准化字符串长度运算符:${#variable}返回$variable值的字符长度。
学到这里我们就可以结合之前用到的位置参数来进行一些脚本程序的容错处理了,比如:filename=${1:-/dev/tty} #如果参数1为空则返回/dev/tty
之前我们没有介绍如何访问传递的参数的总数,这里说明一下,用的是 $# 符合。比如:
另外还有$* ,$@ ,它们一次表示所有的命令行参数。这两个参数可用来把命令行参数传递给脚本或函数所执行的程序。
"$*" 表示将所有命令行参数视为单个字符串,等同于”$1 $2 ..."。$IFS的第一个字符用来作为分隔字符,以分隔不同的值来建立字符串。
“$@" 将所有命令行参数视为单独的个体,也就是单独字符串。等同于"$1" "$2" ...。这是将参数传递给其他程序的最佳方式,因为它会保留所有内嵌在每个参数里的任何空白。
shift命令是用来“截去(lops off)”来自列表的位置参数,由左开始。一旦执行shift,$1的初始值会永远消失,取而代之的是$2的旧值。$2的值变成$3的旧值,以此类推。$#值则会逐次减一。以上几个要多实验,不再赘述。
类似的还有很多特殊变量:(所有引用特殊变量前边加$符号)
# 目前进程的参数个数
@传递给当前进程的命令行参数。置于双引号内,会展开为个别的参数。
* 当前进程的命令行参数。置于双引号内,则展开为一单独参数。
- 在引用时给予shell的选项。
? 前一个命令的退出状态
$ shell进程的进程编号 process ID
0(零) shell程序的名称
! 最近一个后台命令的进程编号
ENV 一旦引用,则仅用于交互式shell中。$ENV的值是可展开的参数。
HOME 根目录
IFS 内部的字段分隔器,想想awk吧。
LANG 当前locale的默认名称;其他的LC_*变量会覆盖其值
LC_ALL 当前locale的名称,会覆盖LANG与其他LC_*变量
LC_COLLATE 用来排序字符的当前locale名称
LC_CTYPE 再模式匹配期间,用来确定字符类别的当前locale的名称
LC_MESSAGES 输出信息的当前语言的名称
LINENO 刚执行过的行再脚本或函数内的行编号
NLSPATH 再$LC_MESSAGES(XSI)所给定的信息语言里信息目录位置。
PATH 命令的查找路径
PPID 父进程的进程编号
PS1 主要的命令提示字符串,默认为“$”
PS2 行继续的提示字符串,默认为"> "
PS4 以set -x设置的执行跟踪的提示字符串。默认为“+ ”。
PWD 当前工作目录。
shell的算数运算符基本跟C语言一样,想直接在命令行测试算数运算符的需要这样加双括号:echo $(( 3&4 )) 之类的。
有一个要知道的地方,每一条命令,不管是内置的、shell函数,还是外部的,当它退出时,都会返回一个小的整数值给引用它的程序,这就是大家所熟悉的程序的退出状态(exit statu)。在shell下执行进程时,有许多方式可取用程序的退出状态。惯例来讲,退出状态为0表示成功执行完成,其他状态都是失败的。可以用ls命令执行对一次错一次分别看看返回状态是多少(上边有讲特殊变量 $? 可查看上一条命令的返回状态)。
POSIX的结束状态:
0 命令成功地退出
>0 在重定向或单词展开期间(~,变量,命令,算符展开,单词切割)失败。
1-125 命令不成功地退出,具体含义由各个单独的命令定义。
126 命令找到了,但文件无法执行。
127 命令找不到。
>128 命令因收到信号而死亡。
令人好奇的是,POSIX留下退出状态128未定义,仅要求它表示某种失败。因为只有低位的8个位会返回给父进程,所以大于255的退出状态都会替换成该值除以256之后的余数。返回值命令:exit value_number 。
关于判断语句 if-then-elif-else-fi 语句给个语法不再赘述:
if判断力你可以使用 !、&&、|| 等C语言里的这些逻辑判断符号。
这里介绍一个test命令,它为了测试shell脚本里的条件,通过退出状态返回其结果,它有第二种形式即 [...] ,单要注意的是方括号根据字面意义逐字地输入,且必须与括号起来的expression以空白隔开。如:test "$str1" = "$str2" 等同于 [ "$str1" = "$str2" ] 。test有好多参数啊,好多。。。自己man吧(敢不敢把26个字母都用完?!!! TT)。这里给出之前的finduser脚本的改良版:
关于case语句,给出例子不再赘述,都十分雷同C语言的。
这个循环将每个原始文件备份为副文件名为.old的文件,之后再使用sed处理文件建立新文件。同时有输出文件名,作为进度的一种提示。另外for循环里的in列表(list)是可选的,如果省略则遍历整个命令行参数,就好像输入了 for i in "$@" 。
while和until循环也都类似,语法为:
until condition
do
statements
done
两者不同之处在于如何对待condition的退出状态,只要condition成功,while就继续循环。只要condition不成功,until则一直循环。
在以上循环里,你仍然可以使用break和continue,功能同C语言一样。
shift之前提到过,它还可以接受一个可选参数,也就是要移动几位。
针对参数的处理有一个getopts命令简化了选项处理,它能理解POSIX选项中将多个选项字母组织到一起的用法,也可以用来遍历整个命令行参数,一次一个参数。该命令会自动过滤掉参数里的-,--等符号。如果得到不合法选项字母,该命令会返回一个?符号。
shell脚本里的函数,一般可以定义在程序的最前部,也可以放在另一个独立文件里,并且以点号(.)命令来取用(source)它们。给出一个简单实例:
调用直接 wait_for_user admin ,还可以接受第二个等待时间参数。在shell函数里,return与exit工作方式相同,可返回一个值,但是需要注意的是在shell函数里使用exit会终止整个shell命令。
新闻热点






疑难解答