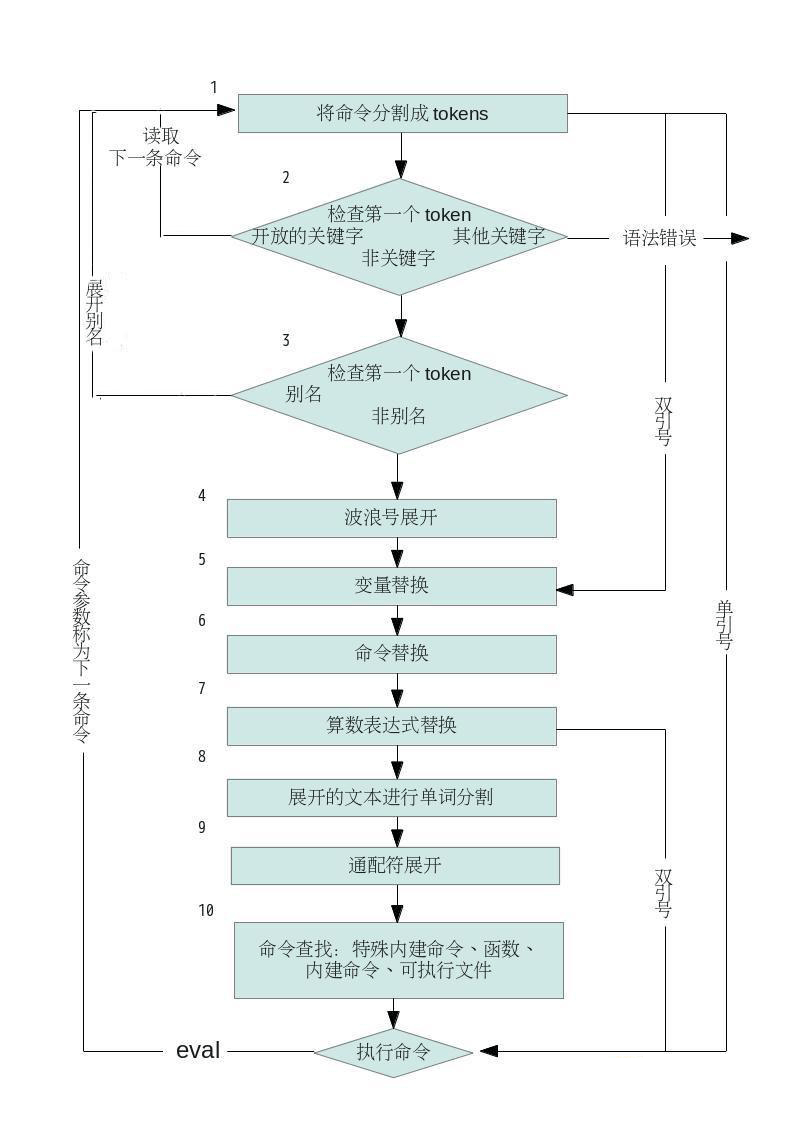
批量执行spark-shell命令,并指定提交参数
#!/bin/bashsource /etc/profileexec $SPARK_HOME/bin/spark-shell --queue tv --name spark-sql-test --executor-cores 8 --executor-memory 8g --num-executors 8 --conf spark.cleaner.ttl=240000 <<!EOFimport org.apache.spark.sql.SaveModesql("set hive.exec.dynamic.partition=true")sql("set hive.exec.dynamic.partition.mode=nonstrict")sql("use hr")sql("SELECT * FROM t_abc ").rdd.saveAsTextFile("/tmp/out") sql("SELECT * FROM t_abc").rdd.map(_.toString).intersection(sc.textFile("/user/hdfs/t2_abc").map(_.toString).distinct).count!EOF以上这篇Spark-shell批量命令执行脚本的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持武林网。
新闻热点






疑难解答