一、需求
需求很简单,就是需要查询一个报表,只有1个表,数据量大约60万左右,但是中间有些逻辑。
先说明一下服务器配置情况:1核CPU、2GB内存、机械硬盘、Sqlserver 2008 R2、Windows Server2008 R2 SP1和阿里云的服务器,简单说就是阿里云最差的服务器。
1、原始表结构

非常简单的一张表,这次不讨论数据冗余和表字段的设计,如是否可以把Project和Baojian提出成一个表等等,这个是原始表结构,这个目前是没有办法改变的。
2、查询的sql语句为
select *from( select *,ROW_NUMBER() OVER (ORDER BY sc desc) as rank from( select *, case when ( 40-(a.p*(case when a.p > 0 then 1 else -0.5 end)))<=30 then 30 else ( 40-(a.p*(case when a.p > 0 then 1 else -0.5 end))) end as sc from ( select * from ( select a.ProjectNumber, a.ProjectName, a.BaojianNumber, a.BaojianName, a.ToubiaoPerson, sum(UnitPrice) as sumPrice, b.price as avgPrice, ((sum(UnitPrice)-b.price)/nullif(b.price,0)*100) as p, sum(case when UnitPrice>b.price then b.price else UnitPrice end )as pprice, sum(case when UnitPrice>MaxPrice then 1 else 0 end ) as countChao from ToubiaoDetailTest1 a join ( select ProjectNumber, ProjectName, BaojianNumber, BaojianName, avg(price) as price from( select * from( select ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson, SUM(UnitPrice) as price, SUM(case when UnitPrice>MaxPrice then 1 else 0 end ) as countChao from ToubiaoDetailTest1 group BY ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson ) tt where tt.countChao = 0 ) t group by ProjectNumber, ProjectName, BaojianNumber, BaojianName ) b on a.ProjectNumber=b.ProjectNumber and a.ProjectName=b.ProjectName and a.BaojianNumber=b.BaojianNumber and a.BaojianName=b.BaojianName group by a.BaojianNumber, a.BaojianName, a.ProjectNumber, a.ProjectName, a.ToubiaoPerson, b.price ) tt where tt.countChao=0 ) a ) b) t order by rank
此段sql语句主要的功能是:
1、根据ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson分组,查询所有数据的sum(UnitPrice)
其中UnitPrice>MaxPrice的判断是为了逻辑,如果有一条数据满足,则此分组所有的数据不查询。
2、根据ProjectNumber, ProjectName, BaojianNumber, BaojianName 分组,查询所有数据的avg(price),以上两步主要就是为了查询根据ProjectNumber, ProjectName, BaojianNumber, BaojianName分组的avg(price)值。
3、然后根据逻辑获取相应的值、分数和按照分数排序分页等等操作。
二、性能调优
在未做任何优化之前,查询一次的时间大约为20秒左右。
1、建立索引
根据sql语句我们可以知道,会根据5个字段(ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson)进行分组聚合,所以尝试添加非聚集索引idx_calc。
在索引键列添加ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson。如图:
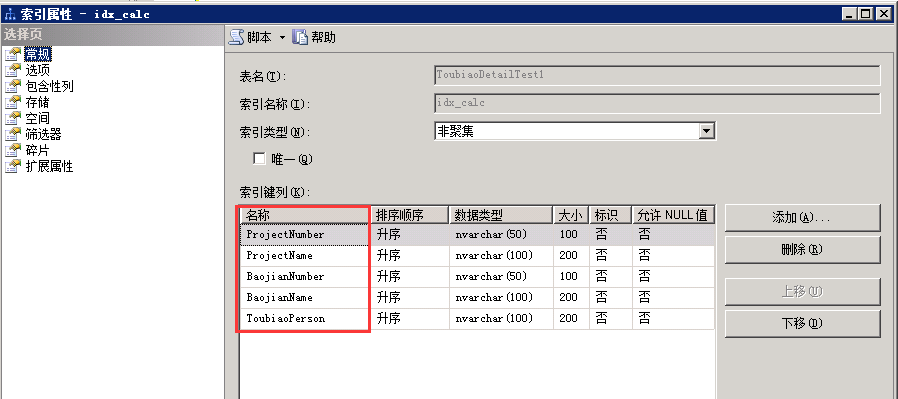
然后执行查询sql语句,发现执行时间已经减半了,只要10610毫秒。
2、索引包含列
分析查询sql可以得知,我们需要计算的值只有UnitPrice和MaxPrice,所以想到把UnitPrice和MaxPrice添加到idx_calc的包含列中。如图
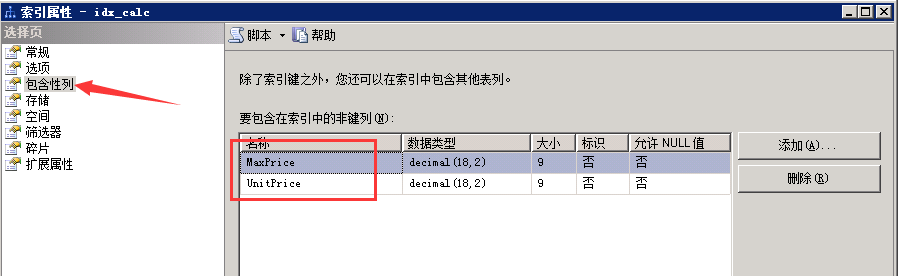
然后执行查询sql语句,发现执行时间再次减半,只要6313毫秒,现在已经从之前的20多秒优化成6秒多。
3、再次优化查询Sql
再次分析sql语句可以把计算所有数据的avg(price)语句暂时放置临时表(#temp_table)中,再计算其他值的时候直接从临时表中(#temp_table)获取数据。
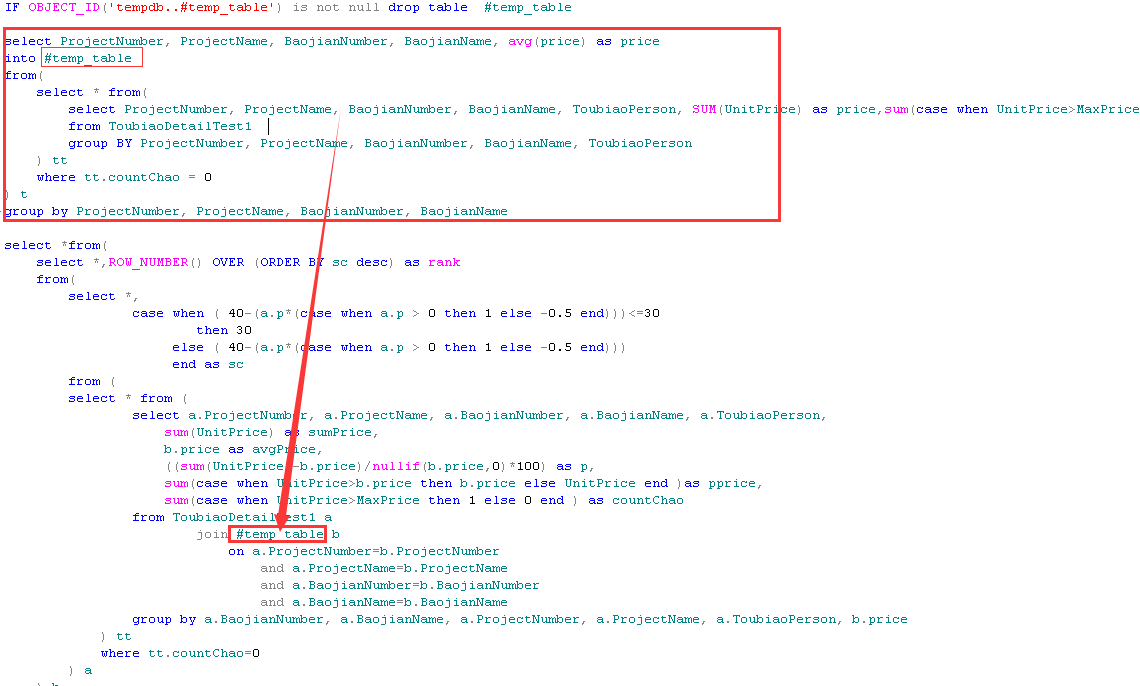
然后执行查询sql语句,执行时间只有2323毫秒。
在硬件、表数据量和查询稍复杂的情况下,这样已经可以基本上满足查询需求了。
三、总结
经过三步:1、建立索引,2、添加包含列,3、用临时表。用三步可以把查询时间从20秒优化至2秒。
以上所述是小编给大家介绍的SQL Server 性能调优之查询从20秒至2秒,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对武林网网站的支持!
新闻热点






疑难解答