
Yonah、Woodcrest(Core)与Dempsey处理器的结构对比。Core继承了Yonah的双核心设计方式―共享L2缓存和系统总线接口,同时增加了L1缓存之间的通讯;不过Core的内部带宽更接近Dempsey,片上缓存的带宽远远超过Yonah,同时系统总线的带宽也有大幅提升 Core架构延续了Yonah的这一特性,因此服务器版本(Woodcrest)将比前代产品(Dempsey)提供更好的性能。此外,英特尔方面多次提到Core架构还可能实现在L1缓存之间直接传输数据,不过到目前为止英特尔对此并没有透露更多的细节,但我们可以相信如果这是真的话,Core的性能无疑会再提升一个档次。
三、指令融合和分支预测体系 此次英特尔从NetBurst架构到Core架构的转型,还有一项非常明显的改进。那就是x86指令的融合,它可以说是Core架构独有的特性之一(图3)。
在处理器内部,x86指令被称为Macro-ops,而内部指令被称为uops,而Macro-ops融合可以将两个Macro-ops融合成一个uops。举个例子来说,我们可以把x86 Compare(比较)指令与x86 Jump(跳转)指令融合在一起,生成一条单独的uops(比较并跳转指令)。在Core中每个解码器都可以完成这样的优化工作,但是每周期内最多只能有一个解码器完成这样的融合,所以最大指令解码带宽是每周期4 1个x86指令。
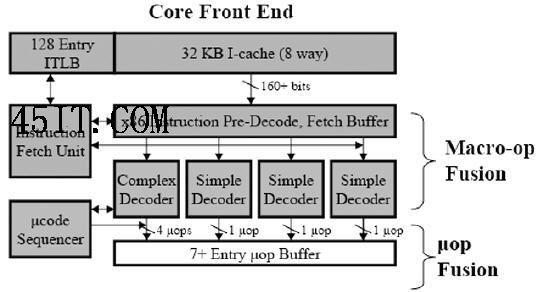


对比英特尔不同架构中的提取指令/译码单元,可以看到Core要比Yonah和Pentium 4更加复杂 这种融合的好处是显而易见的:首先,融合之后需要执行的指令变少了,这等于直接提高了处理器的执行性能;其次,乱序执行可以因此变得更有效率,因为融合的过程实际上就是让指令窗口检查更多的程序代码,更大限度地发现指令之间的并行性,从而提高处理器的执行效率。不过颇具讽刺意味的是,从某种程度上来看这种x86指令的融合机制使得x86处理器更加RISC(简单指令集)化而不是CISC(复杂指令集)化。
为了降低长流水线带来的负面影响,英特尔曾经在NetBurst架构的分支预测上花费了相当大的精力,其分支预测的错误率号称比上一代架构下降了33%以上,而Core架构的分支预测能力在NetBurst的基础上又有进步。
在新架构中,英特尔不仅保留了上一代架构的跳转目标缓冲区、跳转地址计算器以及返回地址堆栈,而且还采用两种新的预测算法―“循环探测”能够正确探测(程序的)循环退出,而“间接分支预测”可以基于全局的历史信息获取(预测)正确的目标地址。除此之外,Core架构还引入了其它的一些新特性,例如在原先的架构中,跳转命令总会引入一个周期的流水线空置,但是在Core架构中引入了一个用于存储跳转发生位置的队列,大部分的流水线空置都将被消除。诸多新特性的引入,使得Core的分支预测能力空前强大,从性能上来说无异于如虎添翼。
新闻热点






疑难解答













