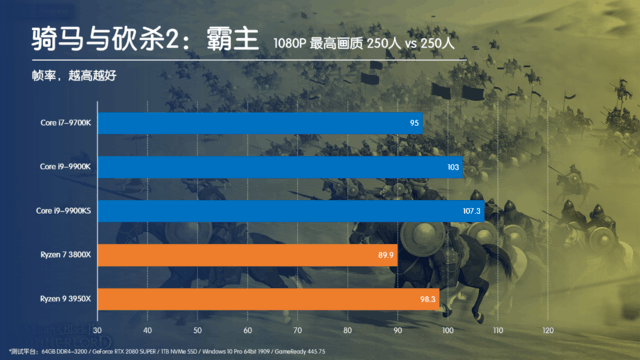
大家都知道,最近一段时间游戏大作频发,先是《使命召唤:战区》火爆全球,紧随其后的《骑马与砍杀2》也在一片叫好声中登顶Steam单周销量榜首。热门游戏自然少不了大量的测试,细心的玩家就会发现,在这些测试中,英特尔的CPU性能表现都要远优于AMD的Ryzen系列,特别是同样核心规模的时候,这种优势就愈发的明显。
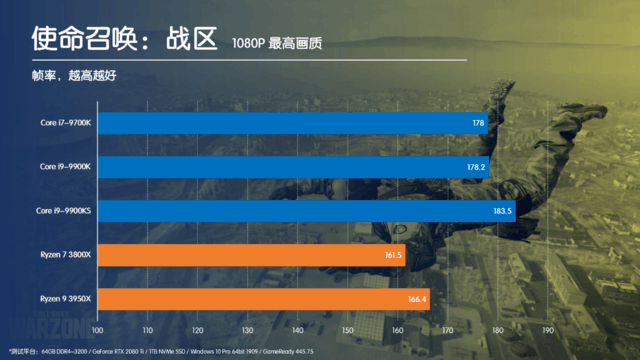
为什么英特尔的处理器要比AMD的更适合玩游戏呢?除去在主频上的优势之外,很重要的一点就是英特尔在CPU本身的架构上,要比AMD的Zen/ Zen2架构,更适合应对游戏这种包含大量复杂逻辑的运算形式,这其中涉及到的很重要的一个部分,就是CPU内部的“片内总线”。
片内总线负责连接CPU芯片内部的各个模块,包括CPU核心以及显示核心、内存控制器等辅助模块。作为各模块数据交换的途径,片内总线的效率,会对CPU性能有着显著的影响,甚至可以说片内总线的结构,决定着一颗CPU最合适的应用场景。片内总线的结构通常包括星形、线形、树形、环状(Ring)、网状(Mesh)以及全连接这几种。其中星形就是早期单核心CPU的主要结构,Core作为中央节点,其他模块都和它链接。进入多核时代后,星形结构就不再适用了。线形和树形同样不适合,因此目前能见到的片内总线方案,主要就是Ring、Mesh和全连接这三种方式。
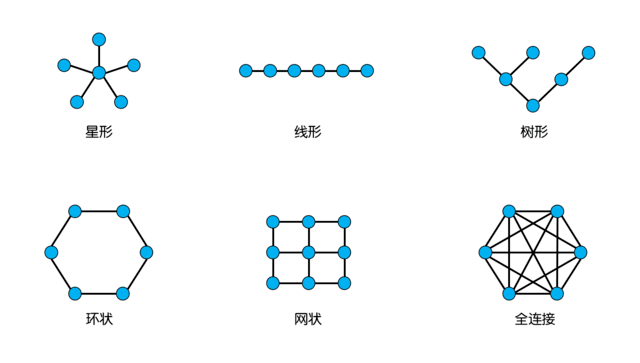
全连接的方式,从结构上来说很理想,因为CPU内部每一个核心节点都能直连另外任意节点,信息传递效率最高,延迟也最低。但是全连接的复杂度会随着核心数量的增加而大幅提升的,比如4核心需要6条内部通路,而8核心就需要28条,16核心就需要120条。如此复杂的线路在设计和制造都是灾难性的,因此目前只有AMD在Zen架构上,采用了缩水版的全连接方式。
所谓缩水,就是Zen/Zen2架构,实际上只做了4核心的全连接,这样只需要6条互联通路,在复杂度上还算可以承受。那么Ryzen和ThreadRipper那么多核心数量是怎么来的呢?那就要说到“胶水”(Multi-Chip-Module)技术了。

在Zen架构中,AMD把这4个全连接的核心成为一个CCX(CPUComplex)模块,2个这样的CCX通过IF互联总线连接,组成了一个芯片(一级胶水)。在Zen2架构中,AMD将这样一个芯片称作CCD(CoreChiplet Die),然后再通过组合多个CCD与I/O模块(cIOD),组成一颗完整的Ryzen3000系列CPU(二级胶水)。
经过两次胶水之后,全连接方式的优势就被完全抵消了,因为在跨CCX进行数据交换要通过IF总线,跨CCD沟通甚至要通过铜电路,由此带来的延迟将变得非常夸张。同时,也正是因此,Ryzen系列处理器非常依赖Windows操作系统的调用机制,AMD也多次与微软合作希望通过打补丁的方式让Windows10系统在进行线程跳转时,尽可能地在CCX内部完成,以此来降低延迟带来的性能损失,然而收效甚微。

既然胶水结构有这么大的劣势,为什么AMD还坚持使用这样的结构呢?原因很简单——省钱。通过使用这种模块化的结构,缩小了单一芯片的规模,AMD能够更好的控制芯片制造的良品率,毕竟用两个8核心CCD“粘”成一个3950X的难度远小于造一个完整的16核心的芯片,而且万一CCD里面坏了两个核心还能封包成3600X继续卖。同时,在频率和计算效率受限的情况下,AMD也是不得不靠胶水技术来堆核心数量,以换取市场上的一席之地。
自己有工厂生产CPU芯片的英特尔,在片内总线的选择上,更偏向对效率的追求。所以针对不同的应用场景使用了不同的结构。比如在MSDT平台上,因为核心数量相对少,大多数家用级用户很少需要去应对大规模并发数据运算的情况,因此选择了延迟控制更好的环形总线(RingBus)。
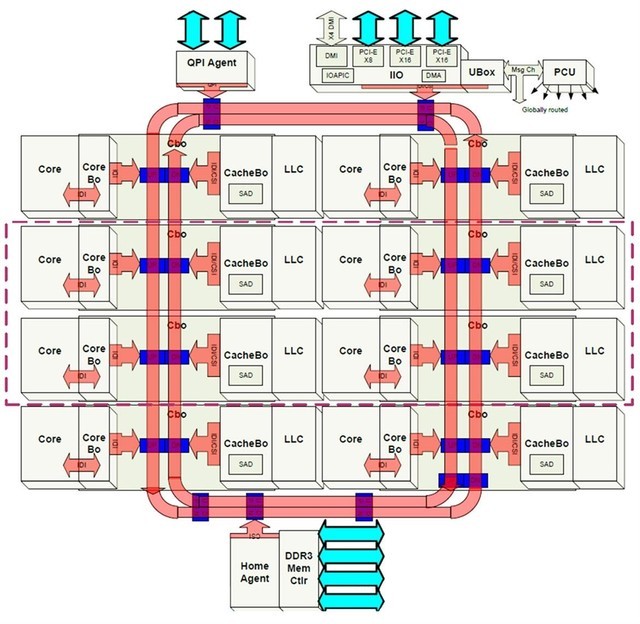
所谓RingBus就是通过一个环路(实际上包括顺时针和逆时针两个同心环)将所有的核心以及其他模块串在一起,核心(或模块)与总线连接的地方被称为RingStop。如此一来,核心之间的数据交互结构距离都不会超过RingStop的一半(因为Ring是双向的),保证了数据交换的延迟尽可能低且稳定。同时,再增加核心的时候,也不会增加互联的复杂度,只需要增加一个新的RingStop即可。
当然RingBus也不是万能的,当核心数量超过12个的时候,会因为RingBus过长而导致平均延迟增大到不可接受的地步。为此英特尔在需要更多核心的HEDT平台上,引入了网状(Mesh)结构。相比于Ring结构,Mesh解决了规模扩增的灵活性,因为在Mesh结构中加入新的节点,并不会导致延迟像Ring结构那样线性的增加。实际上Mesh针对早期HEDT平台所使用的2-Ring结构,还降低了内部核心数据交换延迟以及RAM和I/O的访问延迟。不过HEDT平台并不是我们这篇文章的重点,所以这里就不展开了。
让我们打个比方来解释一下这上面说到的这3种片内互联结构的差异:英特尔的Ring总线就相当于在一个大会议室里进行圆桌会议,每一个人就相当于一个核心节点。数据在核心之间的传递过程就相当于进行一次“击鼓传花”的游戏,只要人数(节点)不太多,那么在任意两个人之间传递东西,所花的时间都会控制在一个非常少的水平。
Mesh架构则很像我们上学时候的教室,里面的每一个学生就相当于一个核心节点。这时候如果要把一个东西在任意两个点之间传递,只需要选择最合适的路径传递过去就可以了,所需要的时间依然会很少。
相比之下,AMDRyzen处理器的CCX相当于4个人坐在一个房间里,一个CCD就是一栋楼里面有这样两个房间,Ryzen93950X或更高的TR系列则由2栋或更多栋楼组成。因此当数据在CCX里的4个人之间传递的时候,效率还算不错,但如果要传递给隔壁房间里的人,就要开门出屋,也就是延迟会大幅度增加。如果还要传递给其他楼里的人,那就要出房间,下楼上楼再进房间,过程中浪费的时间就可想而知了。
实际的测试结果很好的体现出了片内总线的结构差异带来的性能区别:
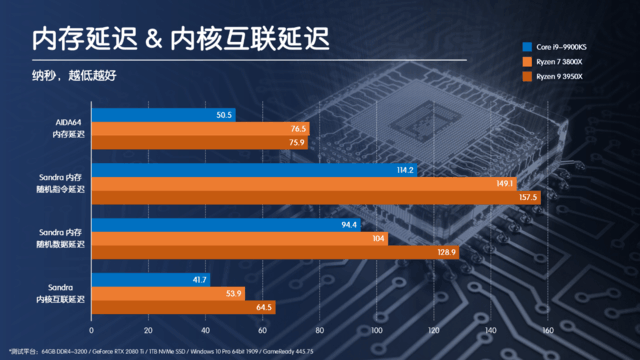
采用Ring结构的Corei9-9900K在延迟方面大幅优于同样8C/16T的Ryzen7 3800X,而对于采用双CCD进行片上胶水的Ryzen93950X更是遥遥领先。而在游戏过程中,CPU本身就需要频繁的对内存进行读写操作,这就将Ring结构的优势充分发挥了出来。即使对于骑砍2这样的大规模集团作战的游戏来说,理论上应该能够很好的发挥多核心的优势,但是因为Zen2架构的内核互联延迟太高,因此在我们开篇的测试数据中,16C32T的3950X反而被Corei9-9900K远远甩开。
考虑到无论是英特尔还是AMD,目前的微架构都将至少还要延续2代产品,因此可以肯定地说,在未来一段时间内,如果要为打游戏而装电脑,英特尔处理器还是最靠谱的选择。
新闻热点






疑难解答













