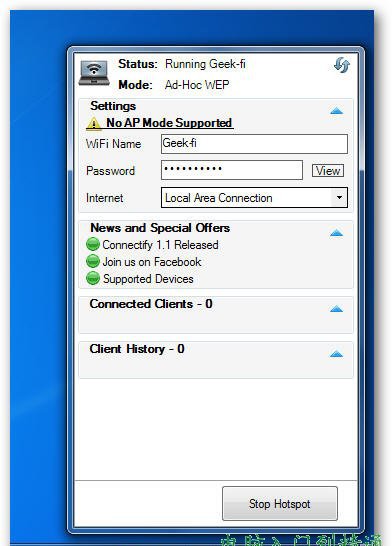
先直接上程序界面,了解整体工作流程是什么样子的,求服务器进行挂机测试,需要固定IP,空间大概需要10G左右(主要是BT种子占用空间过大),最好有SQLSERVER来做为存储数据库,目前采用的是ACCESS数据库做为测试,怕后期数据过百万,对网站进行查询操作很慢。
如果程序运行的时间够长,基本上网络上的种子都会过来,相当于搜片神器了.
开源地址:https://github.com/h31h31/H31DHTMgr
程序下载:H31DHT下载
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/4b8df2ff738a57dad4d6bdba33846ef1.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
也提供ASP网站的访问模式:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/29e63956d53d39d88c79001e2bdab52e.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
正在运行中的状态:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/c1783fe76691f4f269de0f928def379b.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
本次主要介绍对DHT磁力搜索的HASH文件进行处理操作流程。
后台处理程序主要采用C#里面读取文件类来进行读取,目前文件格式分为两种,一种是从http://torrage.com/sync下载回来的文件进行处理,
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/d1e3cf840a5c763e41efe1aa6768957e.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
另外一种是采用C++程序对DHT网络中的HASH文件进行搜索存储的自定义文件,
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/a4ab5e116442b399d0a16c14a271e53d.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
里面有HASH值和时间IP等信息,可以通过这些IP值分析出对方电脑上有哪些BT文件,当然这里面的HASH值对应的文件对应的可是当前活跃在网络上的文件,与上面网站上下载的固定的文件值有区别,
有了这些IP值,个人也可以做些行为分析方面的工作,比如哪些城市的IP在下载些什么类型的文件。
下面介绍下数据库方面的设计工作:
1.初步考虑到SQLSERVER对自己电脑工作速度会有影响,没有安装SQLSERVER数据库,采用ACCESS来进行处理操作;
2.ACCESS数据库每个表的大小最好控制不要超过4G,所以设计每表不超过100百万条数据;
3.对BT种子文件进行解析后,提取里面的文件名字,按照文件类型存储到不同的表中,主要分为6大类,电影,音乐,图片,书箱,程序,其它类,
4.由于BT种子里面语言对应的不一样,有中文,英文,日文,韩国等语言,对于搜索界面如果全部存储到一块,没有什么问题,但会影响查询速度,因为中国人一般喜欢用中文查询,如果想查日文,对选项进行选择一下,这样会对所有的表查询都会有很大提高,因为每个表的文件都基本上针对几种语言;
5.对于BT种子里面的文件列表直接采用100百万一个表,如果超过了,直接存储第二块表,因为主表里面有存储自己的文件列表在哪个表的关键字段;
6.另外对数据库信息也比较严谨一些,由于种子文件里面有很多广告信息,比如视频种子里面经常有网站URL,TXT,MHT等信息链接,程序经过初步判断直接不存储到文件表数据库中,占用数据库空间,影响查询速度,另外查询出来显示列表也不好看.
7.对于一个种子里面经常有>200多个的种子文件也没有进行存储,一个种子有很多文件也比较浪费空间,再说这种种子保存下来基本上都没什么意义,直接PASS;
8.对于文件名里面有网站信息的也采取的过滤措施,对查询有很好帮助.
数据库表设计列表:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/45793174b4d484192544755b960b4625.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
存储DHT文件名字的表:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/8c6f96385b8b80f056424f2855111dce.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
存储种子文件列表:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/495345c6f7817ae0c0cb6c288c3900f5.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
--------------------------下面先介绍一下DHT的工作原理--------------------------------
DHT网络本质上是一个用于查询的网络,其用于查询一个资源有哪些计算机正在下载。每个资源都有一个20字节长度的ID用于标示,称为infohash。当一个程序作为DHT节点加入这个网络时,就会有其他节点来向你查询,当你做出回应后,对方就会记录下你。对方还会询问其他节点,当对方开始下载这个infohash对应的资源时,他就会告诉所有曾经询问过的节点,包括你。这个时候就可以确定,这个infohash对应的资源在这个网络中是有效的。
关于这个网络的工作原理,参看Kevin写的:P2P中DHT网络爬虫以及写了个磁力搜索的网页。
获取到infohash后能做什么?关键点在于,我们现在使用的磁力链接(magnet url),是和infohash对应起来的。也就是拿到infohash,就等于拿到一个磁力链接。但是这个爬虫还需要建立资源的信息,这些信息来源于种子文件。种子文件其实也是对应到一个资源,种子文件包含资源名、描述、文件列表、文件大小等信息。获取到infohash时,其实也获取到了对应的计算机地址,我们可以在这些计算机上下载到对应的种子文件。
在获取到infohash后,从一些提供映射磁力链到种子文件服务的网站上直接下载了对应的种子。
http://torrage.comhttps://zoink.ithttp://bt.box.n0808.com-------------------------我们后台处理程序就从上面进行种子的下载工作---------------------------
下面重点介绍下我们程序的模块设计:
![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/edd9cb036bf026ac56d3ee6ac6b2fabe.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
1.H31SQL类主要方面进行ACCESS和SQLSERVER数据库操作进行初步封装的一个类;
2.H31Debug主要是日志输出类
3.H31Down主要是下载BT种子文件进行的类;
4.TorrentFile类是用来解析BT种子文件类,由于目前可能有的BT种子格式对不上,有些文件解析不上;
5. MainForm主程序界面。
------------------------------------
下面介绍程序处理数据的主要流程:
1.读取本地文件,采用正则表达式对数据进行提取
[csharp] 2.从网站下载BT种子文件来进行处理 [csharp] 3.通过BT文件解析类来读取文件名和列表 4.通过正确正则表达式过滤掉WWW. BBS. 等网站信息,因为这样会影响搜索结果. [csharp] 5.判断文件名是中英文,日文等信息存储到不同的表中; [csharp] 开源地址:https://github.com/h31h31/H31DHTMgr 程序下载:H31DHT下载 下一文章准备对DHT的研究进行文章介绍.如果大家推荐度比较高,我下一步过两天就开源C++写的H31DHT数据抓取数据的程序,程序都是采用VS2005编写. 第一次运行H31DHTMgr程序可能没有数据,可以先从从http://torrage.com/sync下载一个TXT文件回来进行处理 ; 第一次运行H31DHT数据抓取程序可能很久才有几要数据回来,DHT网络好像对固定IP的比较喜欢,返回信息比较多,所以ADSL的抓取速度也不会很快. 另外求服务器进行程序测试,需要有固定IP,10G的WIN服务器空间,h31h31@163.com,谢谢. 由于DHT获取的种子内容带AV内容的多很多,所以不提供ASP网站查询的代码工作,如果提供境外服务器测试,可以提供ASP网站查询代码. 希望有兴趣的朋友一起把这个后台管理程序修改得更加完美一些. 由于第一次开源作品,希望大家推荐.![使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]](/d/file/p/2020/05-23/af812b47be7fa413fe325fab352cfe37.jpg "使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器]")
原文地址:http://blog.csdn.net/dyllove98/article/details/9455987
新闻热点






疑难解答