而整个WPO其实是对浏览器(browser)的加载(load)和解析(parse)过程中的一些消耗行为进行优化, 而load和parse在整个浏览器工作过程中又互相纠结互相作用.
在这篇文字中讨论的更多是FE们能够伸手处理或者通过达成共识的方法来进行快速推动Tech们协助的一些事情.
OK, 我们慢慢把浏览器的工作过程掰细了看吧.
首先, 我们先整一个浏览器如何找到一个网站的简易工作原理 – DNS查询:
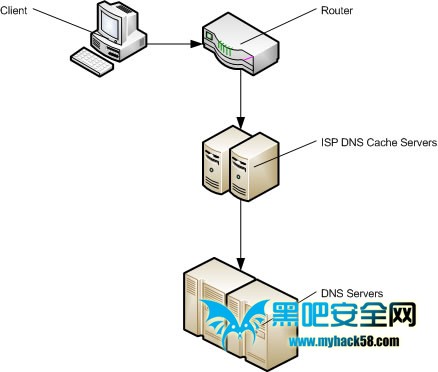
首先当用户在浏览器的地址栏中敲入了网站的网址 ( 比如: alibaba.com ) ,这时浏览器会首先通过访问的域名来定位到IP (DNS) 从而找到去哪里获取资源, 这时, 浏览器会依次进行如下查找:
1. 浏览器缓存 :
浏览器首先会在自己的缓存中查找有没有对应的域名 – IP匹配, 如果好运的话, 这里就可以直接尝试去访问资源了, 如果运气平平则往下走吧.
2. 系统缓存 :
浏览器缓存中没有命中, 浏览器会告诉操作系统:”嘿, 我在我自己口袋里没找到, 可能丢了, 我得去你那看看”, 然后, 一个系统进程(?)调取系统中的DNS缓存进行查询, 重复上一条的运气判断…
3. 路由器缓存 :
走到这, 运气还真不太好啊, 操作系统也没辙了, 那怎么办呢, 向路由去要要看吧… 重复运气判断…
4. ISP DNS缓存 :
好吧, 真不知道说运气好还是运气不好了, 不废话, 去ISP (网络提供商) 的DNS缓存服务器中寻找了, 一般情况下, 在ISP端的缓存中都能找到相应的缓存记录了, 不该这么背了, 或者… 您的ISP有够菜…
5. 递归搜索…
最无奈的情况发生了, 在前面都没有办法命中的DNS缓存的情况下, ISP的DNS服务器开始从root域名服务器开始进行递归, 顺序是从.com顶级域名服务器到alibaba的域名服务器, 再没找到…好吧, 您认为您要去的网站真的公开存在么…?
要强调的是, 不只是对网站第一次的域名访问需要做这样一次查询工作, 在对页面中的资源引用的域名解析时一样会有这样的一系列工作. 最明显的就是启用全新域名来做静态资源存储服务时, 基本上上述的1 – 5个步骤都得走上几遍. 才能让新域名在各DNS缓存服务器上留下记录.
在这个话题上, 关于DNS的类似系统级的解决方案不是FE能够控制得了的, 我们q可以在涉及到DNS时有些小Tips来从中做些事情.
好吧, 第一项.DNS相关的优化:
常规实践 : DNS解析的复杂性决定了不当的使用多域名获取资源会造成不必要的性能开销. 在WPO中, 很多优化工作是很艺术的, 在DNS和HTTP这两方面优化是就可以看到这个神奇的艺术性:
DNS的优化, 当然是尽可能少的造成DNS查询开销, 而在HTTP优化的策略中有一项优化措施是避免单域名下连接数的缺陷来进行资源多通道下载, 实施的细节会在 中详细介绍, 在这里只是简单的提一下, 静态资源多域名服务可以绕过浏览器单域名载入资源时并行连接数的限制, DNS优化需要我们尽可能少的域名解析, HTTP优化时需要我们适当的使用多域名服务, 那怎么样让两个优化实践都能够比较好的实施呢? [todo]
优雅降级 : 在某些现代浏览器 ( Google Chrome, Firefox 3.5+ ) 中, 已经能够支持DNS的预取了, 怎么个预取呢? 就是在浏览器加载网页时, 对网页中的或者的href属性中的域名进行后台的预解析(上文中的 1- 5步), 并且将解析结果缓存在浏览器端, 当用户在真正点击链接时, 省去在当下的DNS解析消耗, 把这个消耗过程转嫁到用户无法感知的浏览过程中去.
第一, 现代浏览器已经支持且默认打开了DNS Prefetch的功能. 当然也可以通过浏览器的配置来管理该功能:
用Firefox3.5+可以这样: 浏览器默认就打开了HTTP协议下的DNS预取功能, 默认关闭HTTPS协议下的DNS预取功能, 可通过 about:config 的 network.dns.disablePrefetch 和network.dns.disablePrefetchFromHTTPS <两个选项来控制两种协议下的预取功能.
Chrome管理DNS Prefetch方法暂时缺少.
第二, 可以通过用meta信息来告知浏览器, 我这页面要做DNS预取:
第三,可以使用link标签来强制对DNS做预取:
[todo DEMO]
注:更多精彩教程请关注武林网电脑教程栏目,武林网电脑办公群:(已满!)欢迎你的加入
新闻热点




疑难解答