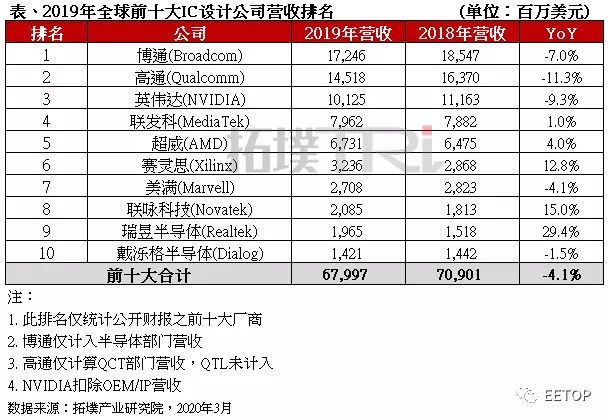
可以用^符号做[]内的前缀,表示除[]内的字符之外的字 符。 比如搜索oo前没有g的字符串所在的行. 使用 '[^g]oo' 作搜索字符串 woody@xiaoc:~/tmp$ grep -n '[^g]oo' regular_express.txt 2:apple is my favorite food. 3:Football game is not use feet only. 18:google is the best tools for search keyword. 19:goooooogle yes!
[] 内可以用范围表示,比如[a-z] 表示小写字母,[0-9] 表示0~9的数字, [A-Z] 则是大写字母们。[a-zA-Z0-9]表示所有数字与英文字符。 当然也可以配合^来排除字符。 搜索包含数字的行 woody@xiaoc:~/tmp$ grep -n '[0-9]' regular_express.txt 5:However ,this dress is about $ 3183 dollars. 15:You are the best is menu you are the no.1.
行首与行尾字符 ^ $. ^ 表示行的开头,$表示行的结尾( 不是字符,是位置)那么‘^$' 就表示空行,因为只有 行首和行尾。 这里^与[]里面使用的^意义不同。它表示^后面的串是在行的开头。 比如搜索the在开头的行 woody@xiaoc:~/tmp$ grep -n '^the' regular_express.txt 12:the symbol '*' is represented as star.
搜索以小写字母开头的行 woody@xiaoc:~/tmp$ grep -n '^[a-z]' regular_express.txt 2:apple is my favorite food. 4:this dress doesn't fit me. 10:motorcycle is cheap than car. 12:the symbol '*' is represented as star. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. woody@xiaoc:~/tmp$
搜索开头不是英文字母的行 woody@xiaoc:~/tmp$ grep -n '^[^a-zA-Z]' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 21:#I am VBird woody@xiaoc:~/tmp$
$表示它前面的串是在行的结尾,比如 '/.' 表示 . 在一行的结尾 搜索末尾是.的行 woody@xiaoc:~/tmp$ grep -n '/.$' regular_express.txt //. 是正则表达式的特殊符号,所以要用/转义 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 5:However ,this dress is about $ 3183 dollars. 6:GNU is free air not free beer. .....
搜索非空行 woody@xiaoc:~/tmp$ grep -vn '^$' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. ..........
点. 代表一个任意字符,必须存在。 g??d 可以用 'g..d' 表示。 good ,gxxd ,gabd .....都符合。
woody@xiaoc:~/tmp$ grep -n 'g..d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 9:Oh! the soup taste good! 16:The world is the same with 'glad'. woody@xiaoc:~/tmp$
搜索两个o以上的字符串 woody@xiaoc:~/tmp$ grep -n 'ooo*' regular_express.txt //前两个o一定存在,第三个o可没有,也可有多个。 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! the soup taste good! 18:google is the best tools for search keyword. 19:goooooogle yes!
搜索g开头和结尾,中间是至少一个o的字符串,即gog, goog....gooog...等 woody@xiaoc:~/tmp$ grep -n 'goo*g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
搜索g开头和结尾的字符串在的行 woody@xiaoc:~/tmp$ grep -n 'g.*g' regular_express.txt // .*表示 0个或多个任意字符 1:"Open Source" is a good mechanism to develop programs. 14:The gd software is a library for drafting programs. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go.
搜索包含两个o的字符串的行。 woody@xiaoc:~/tmp$ grep -n 'o/{2/}' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! the soup taste good! 18:google is the best tools for search keyword. 19:goooooogle yes!
搜索g后面跟2~5个o,后面再跟一个g的字符串的行。 woody@xiaoc:~/tmp$ grep -n 'go/{2,5/}g' regular_express.txt 18:google is the best tools for search keyword.
搜索包含g后面跟2个以上o,后面再跟g的行。。 woody@xiaoc:~/tmp$ grep -n 'go/{2,/}g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
扩展正则表达式是对基础正则表达式添加了几个特殊构成的。 它令某些操作更加方便。 比如我们要去除 空白行和行首为 #的行, 会这样用: woody@xiaoc:~/tmp$ grep -v '^$' regular_express.txt | grep -v '^#' "Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. ............
然而使用支持扩展正则表达式的 egrep 与扩展特殊符号 | ,会方便许多。 注意grep只支持基础表达式, 而egrep 支持扩展的, 其实 egrep 是 grep -E 的别名而已。因此grep -E 支持扩展正则。 那么: woody@xiaoc:~/tmp$ egrep -v '^$|^#' regular_express.txt "Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. .................... 这里| 表示或的关系。 即满足 ^$ 或者 ^# 的字符串。