RegExp对先看整个字符串是不是匹配,如果没有发现匹配,先去掉最后字符串中的最后一个字符,并再次尝试,如果还没有发现匹配,那么再次去掉最后一个字符,这个过程会一直重复下去直到发现匹配或不剩任何字符串,上面的简单量词都是贪婪量词。
test():判断某个字符串是否匹配指定的模式
exec():返回一个数组,数组中的第一个条目是第一个匹配,其他的是反向引用
match():返回一个包含在字符串中的所有匹配的数组
search():返回在字符串中出现的第一个匹配的位置
replace():用另一个字符串来替换某个字符串中的所有匹配
split():将字符串分割成一系列子串并通过一个数组将它们返回
global:表示g是否被设置
ignoreCase:表示i是否被设置
multiline:表示m是否被设置
lastIndex:代表下次匹配将会从哪个字符位置开始
source:正则表达式的源字符串形式
input:表示测试用的字符串
lastMatch:最后匹配的字符
lastParen:最后匹配的分组
leftContext:在上次匹配的前面的子串
rightContext:在上次匹配的后面的子串
multiline:指定是否所有的表达式都使用多行模式
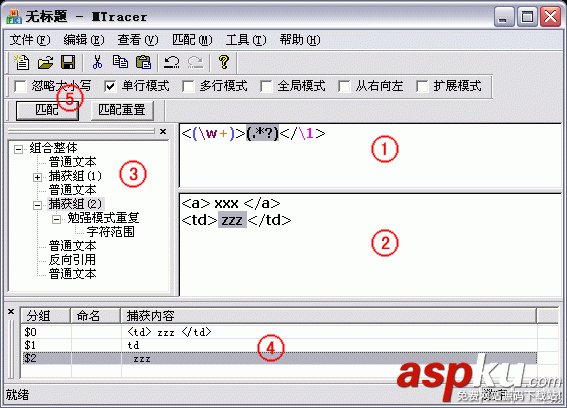
贪婪的、惰性的和支配性的量词
贪婪量词先看整个字符串是不是匹配,如果没有发现匹配,先去掉最后字符串中的最后一个字符,并再次尝试,如果还没有发现匹配,那么再次去掉最后一个字符,这个过程会一直重复下去直到发现匹配或不剩任何字符串,上面的简单量词都是贪婪量词。
惰性量词先看字符串中的第一个字母是不是一个匹配,如果不匹配则继续读入下一个字符进行匹配,如果没有则一直匹配下去,与贪婪量词刚好相反,惰性量词用上面的简单量词跟一个?表示。
支配量词只尝试匹配整个字符串,如果整个字符串不能匹配,不能进一步尝试。
注意:IE和Opera不支持支配量词。
新闻热点






疑难解答