避重就轻
Snopo给出的文本是这样的:or and name='zhangsan' and id=001 or age>20 or area='%renmin%' and like,问,如何提取其中正确的SQL查询语句。
简要分析可知,中间部分是合乎要求的,只是两端的有若干个like, or, and。构造能够解析合乎SQL语法的查询语句的正则表达式,应该是比较复杂的。可是,对于具体的问题,也可以更简单。上述的不良构的SQL语句,应该是使用程序自动生成的,它的两端会有一些不符合题意的文本。只要将这些文本去除就可以了。
于是,我写出了正则表达式:s/^(?:(?:or|and|like)/s*)+|/s*(?:(?:or|and|like)/s*)+$//mi;,这样就把多行字串首尾的like, or, and以及可能的空白字符全部去掉了,剩下的内容即为所求。
分而治之
答案发过去之后,Snopo显然不是很满意这种“偷懒”的办法。他继续问道,能否写出正则式,用来匹配合符SQL语法要求的条件查询语句?(只考虑where部分即可,不必写完整的select。)
的确,从快速解决问题的角度来说,只要能够行之有效地解决,用什么办法都可以;不过从学习知识的角度来说,不避重就轻,而是刨根问底,才是正途。既如此,就看一下如何使用正则,将该SQL查询语句解决掉。
最简单的查询语句,应该是真假判断,即 where 1; where True; where false,等等。 这样的语句使用正则式,直接/(?:-?/d+|True|False)/i。
稍复杂些的单条语句,可以是左右比较,即
复制代码代码如下:
name like 'zhang%', 或 age>25 ,或 work in ('it', 'hr', 'R&D')
。将其简单化,结构就变为A OP B。其中A代表变量,OP代表比较操作符,B代表值。
•A: 最简单的A,应该是/w+。考虑到实际情况,变量包含点号或脱字符,例如`table.salary`,可以记为/[/w.`]+/。这是比较笼统的细化。如果要求比较苛刻,还可以做到让脱字符同时在左右两边出现(条件判断)。
•OP: Where 常用的几种关系比较为:=, <>, >, <, >=, <=, Between, Like, in。使用简单的正则描述之,成为:/(?:[<>=]{1,2}|Between|Like|In)/i。
•B: B 的情况又可分为3种:变量,数字,字符串,列表。为简单起见,这里就不考虑算术表达式了。
◦变量的话,直接延用A的定义即可。不赘述。
◦数字:使用//d+/来定义。不考虑小数和负数了。
◦字符串:包括单引号字串和双引号字串。中间可以包括被转义的引号。我写了一个符合这一要求的引号字串正则表达式,形如:/(['"])(?://['"]|[^//1])*?/1/。不过,由于它只是庞大机器的一个零件,这样写的风险是极其大的。首先,它使用了反向引用;其次,该反向引用使用了全局的反向引用编号。我写了自动生成全局编号的函数,来解决这一问题。不过,这里谈细节是不是太深入了。应该先谈框架,再说细节才对。不应该一入手就陷进细节的汪洋大海。
◦列表:列表是形如(1, 3 , 4) 或 ("it", "hr", "r&d")之类的东东,它由简单变量以逗号相连,两边加上括号组成。列表的单项以I表示,它代表 数字|字符串。此时,列表就变为://(I(?:,I)*?/)/。它表示,左括号,一个I,一系列由逗号、I组成的其它列表项(0个或多个),右括号。简单起见没有考虑空白字符。
•至此,可以总结出单条语句的正则框架:S =~ /A OP B/i。S在此代表单条语句。
更为复杂的是多条语句,可以由单条语句组成,中间使用 and 或 or 连接。合理地构造单条语句,将其稳定地编制为多条语句,任务就完成了。
沿用上面的示例,以S代表单条语句,那么复合语句C就是 C =~ S(?:(?:or|and) S)*?/。至此,一个初具规模的条件语句解析器就诞生了。下面以python为例,一步一步实现出来。
Python实现
重申一句:虽然给出了实现,但是仍请注重思路,忽略代码。
复制代码代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#
#author: rex
#blog: http://iregex.org
#filename test.py
#created: 2010-08-06 17:12
#generage quoted string;
#including ' and " string
#allow /' and /" inside
index=0
def gen_quote_str():
global index
index+=1
char=chr(96+index)
return r"""(?P<quote_%s>['"])(?://['"]|[^'"])*?(?P=quote_%s)"""% (char, char)
#simple variable
def a():
return r'[/w.`]+'
#operators
def op():
return r'(?:[<>=]{1,2}|Between|Like|In)'
#list item within (,)
#eg: 'a', 23, a.b, "asdfasdf/"aasdf"
def item():
return r"(?:%s|%s)" % (a(), gen_quote_str())
#a complite list, like
#eg: (23, 24, 44), ("regex", "is", "good")
def items():
return r"""/( /s*
%s
(?:,/s* %s)* /s*
/)""" % (item(), item())
#simple comparison
#eg: a=15 , b>23
def s():
return r"""%s /s* %s /s* (?:/w+| %s | %s )""" % (a(), op(), gen_quote_str(), items())
#complex comparison
# name like 'zhang%' and age>23 and work in ("hr", "it", 'r&d')
def c():
return r"""
(?ix) %s
(?:/s*
(?:and|or)/s*
%s /s*
)*
""" % (s(), s())
print "A:/t", a()
print "OP:/t", op()
print "ITEM:/t", item()
print "ITEMS:/t", items()
print "S:/t", s()
print "C:/t", c()
该代码在我的机器上(Ubuntu 10.04, Python 2.6.5)运行的结果是:
复制代码代码如下:
A: [/w.`]+
OP: (?:[<>=]{1,2}|Between|Like|In)
ITEM: (?:[/w.`]+|(?P<quote_a>['"])(?://['"]|[^'"])*?(?P=quote_a))
ITEMS: /( /s*
(?:[/w.`]+|(?P<quote_b>['"])(?://['"]|[^'"])*?(?P=quote_b))
(?:,/s* (?:[/w.`]+|(?P<quote_c>['"])(?://['"]|[^'"])*?(?P=quote_c)))* /s*
/)
S: [/w.`]+ /s* (?:[<>=]{1,2}|Between|Like|In) /s* (?:/w+| (?P<quote_d>['"])(?://['"]|[^'"])*?(?P=quote_d) | /( /s*
(?:[/w.`]+|(?P<quote_e>['"])(?://['"]|[^'"])*?(?P=quote_e))
(?:,/s* (?:[/w.`]+|(?P<quote_f>['"])(?://['"]|[^'"])*?(?P=quote_f)))* /s*
/) )
C:
(?ix) [/w.`]+ /s* (?:[<>=]{1,2}|Between|Like|In) /s* (?:/w+| (?P<quote_g>['"])(?://['"]|[^'"])*?(?P=quote_g) | /( /s*
(?:[/w.`]+|(?P<quote_h>['"])(?://['"]|[^'"])*?(?P=quote_h))
(?:,/s* (?:[/w.`]+|(?P<quote_i>['"])(?://['"]|[^'"])*?(?P=quote_i)))* /s*
/) )
(?:/s*
(?:and|or)/s*
[/w.`]+ /s* (?:[<>=]{1,2}|Between|Like|In) /s* (?:/w+| (?P<quote_j>['"])(?://['"]|[^'"])*?(?P=quote_j) | /( /s*
(?:[/w.`]+|(?P<quote_k>['"])(?://['"]|[^'"])*?(?P=quote_k))
(?:,/s* (?:[/w.`]+|(?P<quote_l>['"])(?://['"]|[^'"])*?(?P=quote_l)))* /s*
/) ) /s*
)*
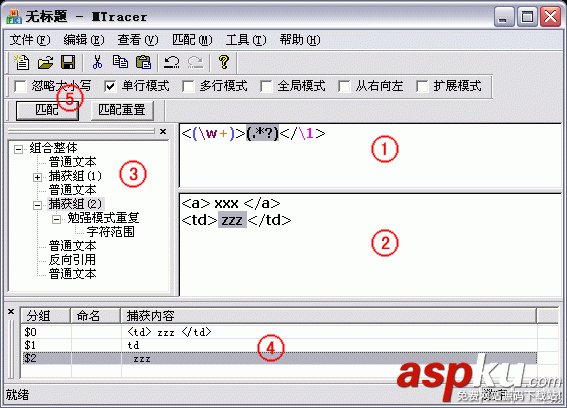
请看匹配效果图:

算术表达式
我记得刚才好像提到“为简单起见,这里就不考虑算术表达式了”。不过,解析算术表达式是个非常有趣的话题,只要是算法书,都会提及(中缀表达式转前缀表达式,诸如此类)。当然它也可以使用正则表达式来描述。
其主要思路是:
复制代码代码如下:
expr -> expr + term | expr - term | term
term -> term * factor | term / factor | factor
factor -> digit | ( expr )
以及代码:
复制代码代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
#
#author: rex
#blog: http://vevb.com
#filename math.py
#created: 2010-08-07 00:44
integer=r"/d+"
factor=r"%s (?:/. %s)?" % (integer, integer)
term= "%s(?: /s* [*/] /s* %s)* " % (factor, factor)
expr= "(?x) %s(?: /s* [+-] /s* %s)* " % (term, term)
print expr
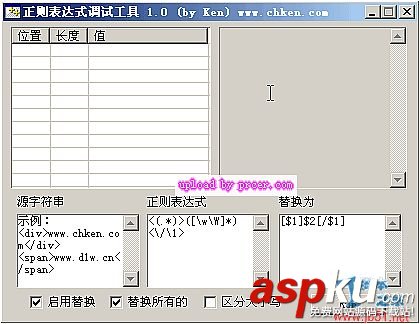
看一下它的输出和匹配效果图:

小贴士
•如果不用复杂的正则式就能解决问题,一定不要用。
•如果必须写比较复杂的正则式,请参考以下原则。
•从大处着眼,先理解待解析的文本的整体结构是什么样子,划分为小部件;
•从细处着手,试图实现每一个小部件,力求每一部分都是完整、坚固的,且放在全局也不会冲突。
•合理组装这些部件。
•分而治之的好处:只有某个模块出错,其它部分没错时,可以迅速定位错误,消除BUG。
•谨慎使用捕获括号,除非你知道自己在做什么,知道它会有什么副作用,以及是否有可行的解决措施。对于短小的正则式来说,一两个多余的括号是无伤大雅的;但是对于复杂的正则式来说,一对多余的括号可能就是致命的错误。
•尽量使用free-space模式。此时你可以自由地添加注释和空白字符,以便提高正则表达式的可读性。