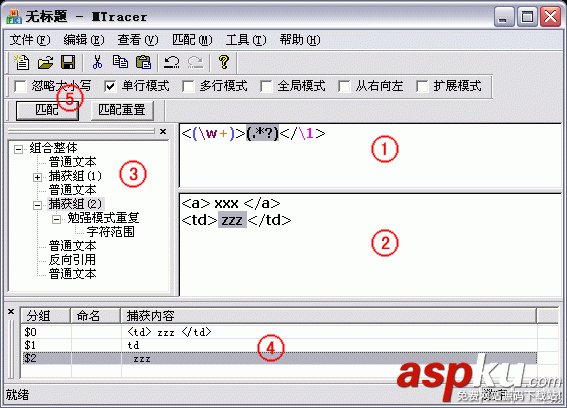
正则表达式的语法就不多说了,大家可以自己搜索查阅相关资料学习。本文所举例子是在《JavaScript语言精粹》上看到的,看完之后对正则表达式有了进一步的理解,故分享之。
例子
解析
下面让我们分解parse_url的各个部分,看看它是如何工作的:
^
^字符表示此字符串的开始,它是一个锚,指引exec不要跳过那些不像URL的前缀,只匹配那些从开头就像URL一样的字符串。
(?:([A-Za-z]+):)?
这个因子匹配一个协议名,但仅当它后面跟随一个 :(冒号)的时候才匹配。(?: . . .)表示一个非捕获型分组(noncapturing group)。后缀 ? 表示这个分组是可选的,它表示重复0次或1次。( . . .)表示一个捕获型分组。一个捕获型分组会复制它所匹配的文本,并把其放到result数组里。每个捕获型分组都会被指定一个编号。第一个捕获型分组的编号是1,所以该分组所匹配的文本副本会出现在result[1]中。 [ . . .]表示一个字符类。A-Za-z这个字符类包含26个大写字母和26个小写字母。连接字符 - 表示范围从A-Z。后缀 + 表示这个字符类会被匹配一次或多次。这个组后面跟着字符 : ,它会按字面进行匹配。
(//{0,3})
这个因子是捕获型分组2,匹配//。/ /表示应,该匹配 / (斜杠)。它用 / (反斜杠)来进行转义,这样它就不会被错误地解释为这个正则表达式的结束符。后缀 {0,3} 表示 / 会匹配0~3次。
([0-9./-A-Za-z]+)
这个因子是捕获型分组3。它会匹配一个主机名,由一个或多个数字、字母以及 . 或 - 字符组成。- 会被转义为 /- 以防止与表示范围的连字符相混淆。
(?::(/d+))?
这个可选的因子匹配端口号,它是由一个前置 : 加上一个或多个数字而组成的序列。/d表示一个数字字符。一个或多个数字组成的数字串会被捕获型分组4捕获。
(?://([^?#]*))?
这个因子也是可选的分组,匹配路径。该分组以一个 / 开始。之后的字符类[^?#]以一个^开始,它表示这个类包含除 ? 和 # 之外的所有字符。* 表示这个字符类会被匹配0次或多次。
注意我在这里的处理是不严谨的。这个类匹配除 ? 和 # 之外的所有字符,其中包括了行结束符、控制字符、以及其他大量不应在此被匹配的字符。大多数情况下,它会按照我们的预期去做,但某些恶意文本可能会有渗漏进来的风险。不严谨的正则表示式是一个常见的安全漏洞发源地。写不严谨的正则表达式比写严谨的正则表示式要容易的多。
(?:/?([^#]*))?
这个因子是一个以一个 ? 开始的可选分组。它包含捕获型分组6,这个分组包含0个或多个非#字符。
(?:#(.*))?
这个因子是以 # 开始的可选分组。. 会匹配除行结束符以外的所有字符。
$
$表示这个字符串的结束。它保证在这个URL的尾部没有其他更多的内容了。
通过这个简单例子,相信大家对正则表达式有了更进一步的理解,祝大家学习愉快!