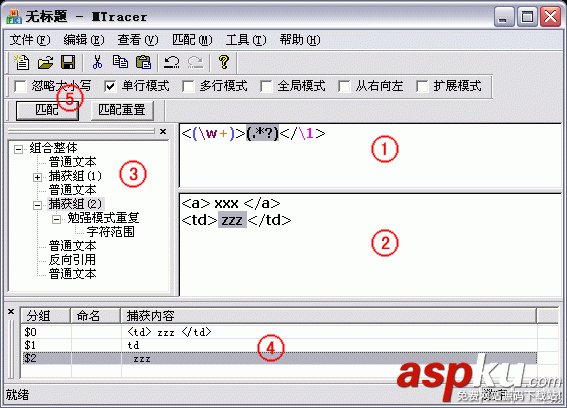
给你一篇文章,如何挑选出你想要的字符串呢?你可以从左到右从上到下,一个一个字符读取出来,写一大堆if做判断。这样太麻烦了,正则就是将以上过程抽象出来,用一些特定符号就能表示出大部分规则
对大部分人来说,正则主要是难记,其实只要对正则符号分类记忆,就会发现核心概念其实特别简单
注:本文会假设你至少看过一遍正则的文档,如果没看过,可以看mdn(有中文翻译),如果觉得mdn排版乱,推荐去https://devdocs.io/javascript/global_objects/regexp学习。本文所使用语言为javascript
元字符
/a/中的a就是一个元字符,一个元字符匹配一个实体字符,这里的“a”没有特殊含义,就匹配一个英文a
像//d/就匹配0到9的所有数字,如果两个连写//d/d/就可以匹配10到99的所有数字
/./可以匹配任何字符
集合
假如有一串字符串'0123456789',我只想匹配其中的'3','6','9',这时可以放在集合中/[369]/
执行后会发现只有3被匹配到,是因为集合中不管写多少东西都代表一个元字符,集合也是一种元字符
你可能见过这样都集合/[0-9a-zA-Z_]/它代表匹配所有数字,字母和下划线,它与元字符//w/的效果是一样的,集合更灵活/w更方便
排除型集合
/[^0-9]/除了数字都匹配(我喜欢叫它否定集合)
或(多选)
假设我有一大堆书单,我希望从中匹配出naroto和one piece,那么可以这样写/naroto|one pice/ 竖线代表或,a或b,你也可以写多个a|b|c|d,你当然可以写出0|1|2...|9来匹配所有数字。但要注意和集合的区别,集合是一个元字符,不能匹配单词,|两边可以是多个元字符
分组
我现在有一堆文件,我希望匹配出后缀是.css和.less的文件,你可以很自然的写出/.css|.less/这样的代码。其实还有一个简便写法/.(c|le)ss/,分组可以将若干个元字符放在同一个作用域中做处理,通过分组我们可以写出更简练的代码
分组还有一个特殊的用法,思考如何匹配'asd_asd_asd_asd_asd'这种字符串?
答案是/(asd)(_/1)+/,/1是个非常特殊的元字符,代表重复使用第一个分组的匹配结果,/2就代表第二个,以此类推,+加号表示重复一到多次(这个后面会讲),需要注意的是计数从1开始,/0代表另外的意思(请看文档)
量词
一长串字符中我只想匹配连续的数字,但//d/只会匹配一个,这时候可以使用量词//d{n,}/,n写几就是几到多,比如{1,}就是1到多。{n}这种写法表示n个相连,匹配2333可以写成/23{3}/
还有几个简写的量词
贪婪模式和非贪婪模式
量词有个尴尬的地方,比如用/.*a/去匹配 '123a123a',本来希望得到'123a',实际却得到'123a123a'。这是因为任何字符都满足/./加上量词会导致从头匹配到尾,但因为我们还有其他元字符,所以这时正则引擎会回溯,将已经匹配的结果从后往前一个个拿出来,与剩下的元字符相匹配。
这种模式叫贪婪模式,它可能会产生预期之外的结果和不必要的性能浪费
解决方案是使用非贪婪模式,在量词后面加?问号可以得到最小结果,现在使用/.*?a/去匹配就可以得到'123a'了。任何量词后都可以使用非贪婪模式
环视
x(?=y)这个功能有很多种翻译,比如零宽断言,我个人感觉比较准确的是“正向肯定环视”
x(?!y)正向否定环视
x代表元字符,y也代表元字符,x(?=y)的意思是紧接着y的x,比如 '-1a--2b-',使用//d(?=a)/去匹配,会得到1;//d(?!a)/去匹配,会得到2。
这功能怎么用?举个例子,有一段字符串'a(123)b',我只想要括号内的内容,但不想要括号
我需要匹配到右括号左边的位置,那么我可以写成/(?=/))/(注意括号需要转义),我不想要左括号/[^(]/,我不关心括号内的内容/.*/,这时组合三个正则就变成了/[^(].*(?=/))/
实际上这个功能匹配的是位置,从匹配到的位置开始找元字符,所以你如果在环视后面加量词是没用的
其他
^和$也是匹配位置的元字符,分别是匹配开头和结尾,比如我们想匹配文件结尾是.js的文件可以写成/.js$/。匹配http开头的链接可以写成/^http://///
还有一些特殊的/u[/b]/0等,需要你自己看文档
标识符
g:一个正则只会匹配一次,如果加上g标识符就会全局匹配, //d/g,这个正则是不管两个数字之间隔了什么,都会将所有数字匹配出来
i:不区分大小写/^http://///i就会匹配http://和HTTP://
核心概念就这么多,其他内容请详细查看文档
你以为这就结束了?其实还有后续哒!
我要继续说环视
还有个神奇的逆向环视没有讲x(?<=y) ,因为这是18年才进正式标准的功能,虽然它可能比js年龄大,但js就是不支持你怕不怕!
前面那个/[^(].*(?=/))/可以改成/(?<=y).*(?=/))/
正则最大但坑就是,让新手产生正则无所不能的想法,一个复杂字符串处理总以为可以通过一个神奇的正则来搞定。
正则不是万能的!
还是之前的例子,给字符串'a(1/(2(3)'让你取括号内的内容请问你怎么取?首先应该弄清需求,如果正则过于难写,可以用js的字符串处理函数辅助正则,分部操作。另外正则的性能并不高,不是说很复杂的操作写成一行正则性能就比其他方式快了,没有测试就没有发言权
正则理论上是有极限的,举个例子,有字符串1xxxyyyy2让你取{n}个x和{m}个y,n和m是不确定个数,写成x{1,}y{1,}是没问题的,但如果要求是x{n}y{n}就不行了,比如一个字符串有3个x,你就要取3个y,有4个x,你就要取4个y,单靠正则就无法完成了。
正则难,难在门槛高,门槛高在难记,之所以难记,其实还是因为反人类的符号让你下意识的排斥它。熟悉正则,正式正则,学会正则,会给你带来超乎想象的便利!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持VEVB武林网。
新闻热点






疑难解答