一、分类问题损失函数——交叉熵(crossentropy)
交叉熵刻画了两个概率分布之间的距离,是分类问题中使用广泛的损失函数。给定两个概率分布p和q,交叉熵刻画的是两个概率分布之间的距离:
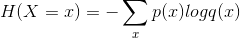
我们可以通过Softmax回归将神经网络前向传播得到的结果变成交叉熵要求的概率分布得分。在TensorFlow中,Softmax回归的参数被去掉了,只是一个额外的处理层,将神经网络的输出变成一个概率分布。
代码实现:
import tensorflow as tf y_ = tf.constant([[1.0, 0, 0]]) # 正确标签 y1 = tf.constant([[0.9, 0.06, 0.04]]) # 预测结果1 y2 = tf.constant([[0.5, 0.3, 0.2]]) # 预测结果2 # 以下为未经过Softmax处理的类别得分 y3 = tf.constant([[10.0, 3.0, 2.0]]) y4 = tf.constant([[5.0, 3.0, 1.0]]) # 自定义交叉熵 cross_entropy1 = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y1, 1e-10, 1.0))) cross_entropy2 = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y2, 1e-10, 1.0))) # TensorFlow提供的集成交叉熵 # 注:该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果 # labels为期望输出,且必须采用labels=y_, logits=y的形式将参数传入 cross_entropy_v2_1 = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y3) cross_entropy_v2_2 = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y4) sess = tf.InteractiveSession() print('[[0.9, 0.06, 0.04]]:', cross_entropy1.eval()) print('[[0.5, 0.3, 0.2]]:', cross_entropy2.eval()) print('v2_1', cross_entropy_v2_1.eval()) print('v2_2',cross_entropy_v2_2.eval()) sess.close() ''''' [[0.9, 0.06, 0.04]]: 0.0351202 [[0.5, 0.3, 0.2]]: 0.231049 v2_1 [ 0.00124651] v2_2 [ 0.1429317] ''' tf.clip_by_value()函数可将一个tensor的元素数值限制在指定范围内,这样可防止一些错误运算,起到数值检查作用。
* 乘法操作符是元素之间直接相乘,tensor中是每个元素对应相乘,要去别去tf.matmul()函数的矩阵相乘。
tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y)是TensorFlow提供的集成交叉熵函数。该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果;labels为期望输出,且必须采用labels=y_, logits=y3的形式将参数传入。
二、回归问题损失函数——均方误差(MSE,mean squared error)
均方误差亦可用于分类问题的损失函数,其定义为:
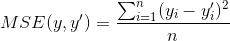
三、自定义损失函数
对于理想的分类问题和回归问题,可采用交叉熵或者MSE损失函数,但是对于一些实际的问题,理想的损失函数可能在表达上不能完全表达损失情况,以至于影响对结果的优化。例如:对于产品销量预测问题,表面上是一个回归问题,可使用MSE损失函数。可实际情况下,当预测值大于实际值时,损失值应是正比于商品成本的函数;当预测值小于实际值,损失值是正比于商品利润的函数,多数情况下商品成本和利润是不对等的。自定义损失函数如下:
新闻热点






疑难解答













